C'è uno schema nel caos? Proviamo a trovarlo! Apprendimento automatico sull'esempio di un campione specifico. - pagina 21
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Ho tagliato altri due anni da questo campione e la media degli esami è già diventata -485 (era 1214) e il numero di modelli che hanno superato il limite di 3000 punti è diventato 884 (era 277 l'ultima volta).
Tuttavia, i risultati sul campione d'esame sono peggiorati da una media di 2115 a 186 punti, cioè in modo significativo. Che cosa succede? Ci sono meno esempi nel campione del treno simili a quelli del campione di prova?
Il numero medio di alberi è sceso da 10 a 7.
L'interruzione dello zero sul grafico ha spostato la distribuzione dell'equilibrio verso il centro.
Su cosa si basa l'affermazione che il risultato dovrebbe essere simile al test? Presumo che i campioni non siano omogenei - non c'è un numero comparabile di esempi simili in essi, e penso che le distribuzioni di probabilità sui quanti differiscano un po'.
Traine. Sto parlando di dati in cui ci sono buoni modelli. Se si inseriscono 1000 varianti della tabella di moltiplicazione nell'addestramento, le nuove varianti che non corrispondono mai alla traiettoria (ma all'interno dei confini della traiettoria) verranno calcolate abbastanza bene. Un albero fornirà la variante più vicina, una foresta casuale farà una media di cento varianti più vicine e molto probabilmente fornirà una risposta più accurata di quella di un albero.
Se si possono trovare predittori con regolarità per il mercato, allora anche l'OOS sarà simile a una traccia. Ma non come ora che più della metà dei modelli sono negativi e un terzo sono positivi. Tutti i modelli di successo sono diventati così per caso, grazie a un seme casuale.
Il seme dovrebbe cambiare solo leggermente il successo del modello e in generale tutti dovrebbero avere successo. Ora risulta che non sono stati trovati modelli (né di sovrallenamento né di sottoallenamento).
È coinvolto solo per controllare l'interruzione dell'addestramento, cioè se non c'è alcun miglioramento sul test durante l'addestramento sul treno, l'addestramento si interrompe e gli alberi vengono rimossi fino al punto in cui c'è stato l'ultimo miglioramento sul modello di test.
È quindi chiaro perché anche i test sono buoni. Si tratta essenzialmente di un adattamento al test. Ho smesso di farlo per l'addestramento 1. Faccio il valving in avanti, incollo tutte le UOC insieme, quindi scelgo i migliori iperparametri del modello (profondità, numero di alberi, ecc.) tra le numerose varianti di UOC incollate. Presumo che l'Esame sarà circa lo stesso dell'incollaggio selezionato di tutte le UOC. In questa variante, per oltre 5 anni, mi sono riallenato una volta alla settimana: si tratta di centinaia di allenamenti e pezzi di OOS.
A quanto pare non ho indicato chiaramente il campione utilizzato: questo è il sesto (ultimo) campione dell'esperimento descritto qui, quindi ci sono solo 61 predittori.
strategie primitive, soprattutto in aree di mercato piatte.Beh, avete scelto questi 61 su oltre 5000. Il mio numero totale è inferiore e il numero di quelli selezionati è inferiore. E quando ne aggiungo 1 alla volta, dopo 3-4 selezionati, l'ulteriore aggiunta di segni non fa che peggiorare il risultato dell'OOS.
In generale, posso aggiungere altri predittori, perché ora vengono utilizzati solo con 3 TF, con alcune eccezioni - penso che se ne possano aggiungere un paio di migliaia, ma non è certo che tutti vengano utilizzati correttamente nell'addestramento, dato che 10000 varianti di semi per 61 predittori danno una tale diffusione....
Inoltre, è necessario effettuare un pre-screening dei predittori, che accelererà l'addestramento.
Se sono tutti uguali, è improbabile che si trovi qualcosa che migliori seriamente il risultato. Si possono provare dati completamente nuovi o indicatori unici.
Anche lo screening preliminare è un lavoro lungo, l'aggiunta di una alla volta è molto più lunga, anche fino a 3 caratteristiche, e se fino a 10, sono molti giorni. Ma non ha senso, dopo 3-4 caratteristiche di solito non c'è alcun miglioramento. A volte ci sono, ma l'aumento è minimo. Non sono stati trovati passi avanti (nei miei esperimenti, qualcuno potrebbe trovarli).
È logico che gli outlier siano outlier, penso solo che si tratti di inefficienze, che dovrebbero essere apprese rimuovendo il rumore bianco. In altre aree, le semplici strategie primitive spesso funzionano, soprattutto in aree di mercato piatte.
Il quadro di fondo è redditizio, ma in 5 anni ci sono stati solo 2 periodi nel 2017 con una forte crescita (apparentemente c'era una forte tendenza prevedibile), il modello ha guadagnato di più in questi 2 periodi. Sarebbe bello avere una crescita uniforme nel tempo. Spegnerei un modello del genere dopo un mese di inattività.
Naturalmente è possibile creare un EA - in attesa di cigni bianchi. Ma preferirei un trading attivo.
Tagliando altri due anni da questo campione, la media degli esami è già diventata -485 (era - 1214) e il numero di modelli che superano il limite dei 3000 punti è diventato 884 (era 277 l'ultima volta).
Tuttavia, i risultati sul campione d'esame sono peggiorati da una media di 2115 a 186 punti, cioè in modo significativo. Che cosa succede? Ci sono meno esempi nel campione del treno simili a quelli del campione di prova?
Il numero medio di alberi è sceso da 10 a 7.
L'interruzione dello zero sul grafico ha spostato la distribuzione dell'equilibrio verso il centro.
Puoi postare i file del primo post, voglio provare anche io un'idea.
Traine. Sto parlando di dati in cui sono presenti buoni modelli. Se si inviano 1000 varianti della tabella di moltiplicazione per l'addestramento, anche le nuove varianti che non coincidono mai con la traiettoria (ma all'interno dei confini della traiettoria) saranno ben calcolate. Un albero fornirà la variante più vicina, una foresta casuale farà una media di cento varianti più vicine e molto probabilmente fornirà una risposta più accurata di quella di un albero.
Se si possono trovare predittori con regolarità per il mercato, allora anche l'OOS sarà simile a una traccia. Ma non come ora che più della metà dei modelli sono negativi e un terzo positivi. Tutti i modelli di successo sono diventati così per caso, a partire da un seme casuale.
Il seme dovrebbe cambiare solo leggermente il successo del modello e in generale tutti dovrebbero avere successo. Ora risulta che non sono stati trovati modelli (né di sovrallenamento né di sottoallenamento).
Nessuno sta sostenendo che con buoni dati tutto funzionerà molto probabilmente alla perfezione. Ma non è possibile ottenere tali dati, quindi bisogna pensare a ciò che si può spremere da ciò che si ha.
Il fatto che sia possibile ottenere modelli efficaci in modo casuale, che saranno efficaci su nuovi dati, mi fa pensare a come ridurre questa casualità, cioè se ci sono metriche regolari per i segmenti quantistici, su cui il modello è stato costruito in modo coerente. Si tratta cioè di metriche aggiuntive rispetto all'avidità dell'obiettivo. Se è possibile stabilire tali dipendenze, è possibile costruire modelli con una maggiore probabilità di successo. Naturalmente, questo dovrebbe funzionare su campioni diversi.
Allora capisco perché anche i test sono buoni. È essenzialmente un adattamento al test. Io ho smesso di farlo per 1 studio. Faccio il valving in avanti, incollo tutte le UOC insieme, poi scelgo i migliori iperparametri del modello (profondità, numero di alberi, ecc.) tra le molte varianti di UOC incollate. Presumo che l'Esame sarà circa lo stesso dell'incollaggio selezionato di tutte le UOC. In questa variante, nell'arco di 5 anni, mi sono riqualificato una volta alla settimana: si tratta di centinaia di allenamenti e di pezzi di OOS.
La cosa principale è non separare l'ultima sezione d'esame.
Adattare gli iperparametri e valutare il risultato in base a cosa? Credo che si tratti dello stesso fitting con un elemento di media, se seguiamo la tua logica.
La logica di CatBoost è che se non è possibile migliorare il modello (con Logloss), allora non ha senso proseguire l'addestramento. In questo caso non ci sono garanzie che il modello sia buono, ovviamente.
Bene, questi 61 li hai scelti su oltre 5000. Ho sia il numero totale che il numero di quelli selezionati. E quando ne aggiungo 1 alla volta, dopo 3-4 selezionati, l'ulteriore aggiunta di caratteristiche peggiora solo il risultato su OOS.
No, non le ho scelte: le ho tolte dal modello durante l'allenamento su tutti i predittori.
In genere considero il predittore come un insieme di segmenti quantici. E per questo motivo seleziono i segmenti quantici, in generale posso anche scomporre tutti i predittori in binari - il risultato è leggermente peggiore, ma paragonabile. Forse per i predittori binari scarichi è necessario un metodo di addestramento speciale.
Se sono tutti uguali, è improbabile che si possa già trovare qualcosa che migliori seriamente il risultato. Si possono provare dati completamente nuovi o indicatori unici.
Cosa intendi per "più o meno uguali", immagino tu stia parlando di metriche o cosa? Naturalmente, è possibile provare dati diversi, ad esempio con uno strumento diverso.
Anche il pre-screening è un lavoro lungo, aggiungere una per una richiede molto più tempo, anche fino a 3 caratteristiche, e se fino a 10 ci vogliono molti giorni. ma non ha senso, dopo 3-4 caratteristiche di solito non c'è alcun miglioramento. A volte ci sono, ma l'incremento è minimo. Non sono stati trovati passi avanti (nei miei esperimenti, qualcuno potrebbe trovarli).
La variante di cui parli è un gioco lungo, ecco perché non ci gioco (beh, non ho un'automazione completa). Ma non sono d'accordo sul fatto che non ci sia alcun effetto - ho fatto degli abbandoni in gruppo, con la riduzione dei gruppi - il risultato è stato positivo. Ma continuo ad attribuire queste azioni al fitting o alla casualità - non c'è alcuna giustificazione per la scelta dei predittori.
La figura inferiore è redditizia, ma in 5 anni ci sono stati solo 2 periodi nel 2017 con una forte crescita (apparentemente c'era una forte tendenza prevedibile), il modello ha fatto i soldi più su questi 2 periodi. Sarebbe bello avere una crescita uniforme nel tempo. Io spegnerei un modello del genere dopo un mese di inattività.
Naturalmente, è possibile creare un Expert Advisor in attesa di cigni bianchi. Ma preferirei un trading attivo.
Per questo motivo sono favorevole all'utilizzo di serie di modelli, in quanto capisco che ognuno di essi può cogliere i propri pattern non frequenti.
In generale, l'obiettivo è che l'errore sulla traiettoria e sul test sia più o meno lo stesso. In questo caso l'esame si sta muovendo verso la traccia e il test, cioè verso l'alto, e loro verso il test, cioè verso il basso. Il sovrallenamento diminuisce.
E in base a quale parametro sono simili?
Prendiamo, ad esempio, la metrica della precisione, sottraiamo l'indicatore sul campione di test da quello del treno, - otteniamo il delta (asse y), e per x consideriamo il profitto sul campione d'esame.
Non c'è una dipendenza particolare, o cosa?
Di seguito sono riportate le due metriche per ogni campione - i dati vengono presi quando nuovi alberi vengono aggiunti al modello.
Ecco le caratteristiche di questo modello
Ed ecco le metriche di un altro modello, con perdite su due campioni
Ecco le caratteristiche del modello
È scomodo rispondere in stile forum, cliccando più volte su rispondi. Qui sotto le mie risposte sono evidenziate in colore.
Факт того, что возможно получить эффективные модели случайным образом, которые будут эффективны на новых данных, меня заставляет задуматься - как снизить эту случайность, т.е. есть ли какие то закономерные метрики у квантовых отрезков, по которым была последовательна построена модель. Т.е. речь о дополнительных метриках, кроме жадности по целевой. Если удастся установить такие зависимости, то и модели можно строить с большей вероятностью успешными. Конечно, это должно работать на разных выборках.
> Ho visto molto tempo fa come vengono costruiti i quanti, le varianti di base. Innanzitutto, la colonna viene ordinata.
1) per intervallo, a passi pari (ad es. da 0 a 1 con passo di valore esattamente attraverso 0,1 per un totale di 10 quanti 0,1, 0,2, 0,3 ... 0,9)
2) percentile - cioè per numero di esempi. Se dividiamo per 10 quanti, allora in ogni quanto mettiamo il 10% del numero di tutte le righe; se ci sono molti doppi, allora alcuni quanti saranno più del 10%, perché i doppi non devono cadere in altri quanti; per esempio, se i doppi sono il 30% del campione, allora in questo quanto cadranno tutti. A seconda del numero di campioni in ogni quanto, la distribuzione potrebbe essere 0,001, 0,12,0,45,0,51,0,74, .... 0,98.
3) esiste una combinazione di entrambe le tipologie
Quindi non c'è nulla di super intelligente nella costruzione dei quanti. Ho realizzato entrambi i metodi di quantizzazione per me stesso. E come sempre ho fatto qualcosa nel modo che ritengo migliore. Forse ho commesso un errore. Di solito eseguo i calcoli senza quantizzazione, ma su dati float.
Se si rendono binari tutti i predittori, ci saranno solo due quanti, uno con tutti 0 e l'altro con tutti 1.
Si adattano gli iperparametri e si valuta il risultato su cosa? Credo che sia lo stesso fitting con un elemento di media, se si segue la sua logica.
> Guardo i grafici di equilibrio e i drawdown. Non sono ancora riuscito ad automatizzare la selezione. Sì, l'adattamento serve a migliorare l'incollaggio OOS. Ma non il modello in sé (cioè non la traccia), bensì la selezione dei migliori iperparametri del modello.
Cosa intendi per "circa lo stesso", immagino che tu stia parlando di qualche metrica o cosa? Naturalmente, è possibile provare altri dati, ad esempio con un altro strumento.
> Tutti questi sono fatti su prezzi e mashup.
Su una vecchia domanda.
Su cosa si basa l'affermazione che il risultato dovrebbe essere simile al treno? Presumo che i campioni non siano omogenei - non c'è un numero comparabile di esempi simili, e penso che le distribuzioni di probabilità dei quanti siano leggermente diverse.
> Esempi qui https://www.mql5.com/ru/articles/3473
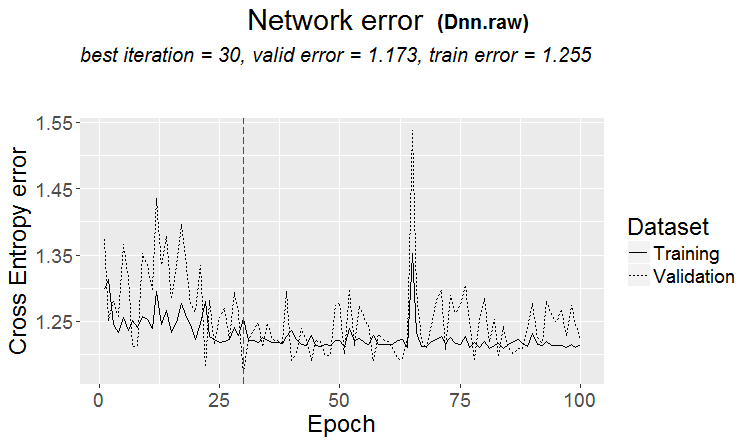
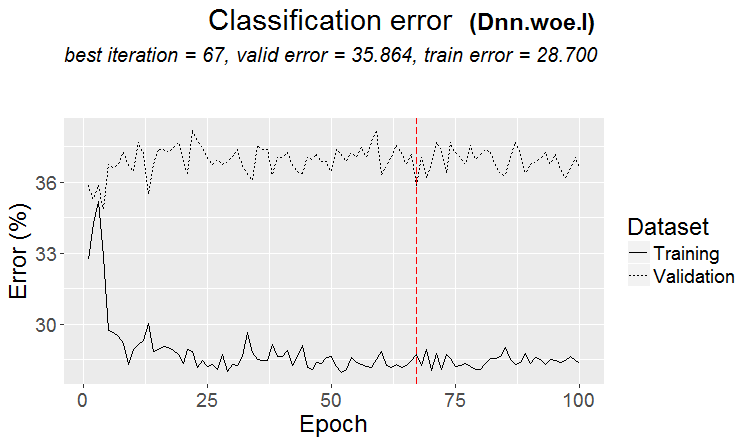
Una buona variante si ha quando si trova un modello: ternario e test hanno quasi lo stesso errore
Sui mercati accade più spesso qualcosa del genere: un buon test, ma dopo qualche passo di addestramento (nella figura dopo il terzo passo) inizia il retraining e l'errore del test inizia a crescere. Le immagini si riferiscono alle reti neurali, ma si verifica qualcosa di simile anche con le foreste e i boost, quando il modello diventa sovrallenato.
In base a quale metrica sono simili?
Ma questo non significa che le tue metriche siano sbagliate.
Quindi non c'è nulla di super intelligente nella costruzione quantistica. Ho realizzato entrambi i metodi di quantizzazione per me stesso. E come sempre ho fatto qualcosa nel modo che ritengo migliore. Forse ho commesso un errore. Di solito eseguo i calcoli senza quantizzazione, ma utilizzando dati fluttuanti.
Naturalmente ci sono diversi metodi, ora uso circa 900 tabelle quantistiche.
Il punto non sta nel metodo, ma nella scelta dell'intervallo del predittore in cui il valore medio del target binario è superiore a quello del campione (ora metto un minimo del 5% più un criterio sul numero di esempi - anch'esso un minimo del 5%), che indica informazioni utili nel predittore. Se non c'è questa informazione, si può sperare che appaia in qualche split, ma credo che sia meno probabile.
Infatti, capita che ci siano 1-2 trame di questo tipo, raramente ce ne sono molte. A questo punto si possono prendere solo queste trame, oppure prendere solo i predittori con tali trame, scegliendo la tabella quantistica migliore.
Personalmente, ho visto che i predittori, almeno i miei, non hanno transizioni regolari di probabilità, ma piuttosto avvengono in modo discontinuo e cambiano alla deviazione opposta, ad esempio era +5 ed è diventato immediatamente -5. Penso addirittura che se queste probabilità sono ordinate, il modello sarà più facile da addestrare, dato che viene addestrato su intervalli. Questo è il motivo per cui ha senso escludere le aree non informative e separare quelle in conflitto.
Se si rendono binari tutti i predittori, ci saranno solo 2 quanti, uno con tutti 0 e uno con tutti 1.
In realtà ce ne sarà uno - 0,5 :) Ma in questo modo è possibile decomporre il predittore in intervalli utili (contenenti informazioni potenzialmente utili).
> Guardando i grafici di equilibrio e i drawdown. L'automazione della selezione non ha ancora funzionato. Sì il fitting - per il miglior incollaggio OOS. Ma non il modello in sé (cioè non la traccia), bensì la selezione dei migliori iperparametri del modello.
Beh, è comprensibile, ma non canonico: anche le metriche del modello sono importanti, credo.
> Tutte cose che vengono fatte su prezzi e mashup.
In teoria sì, e che se si utilizzano le reti neurali, ma in realtà - no - dipendenze troppo complesse dovrebbero essere ricercati con calcoli diversi, per questo semplicemente non hanno la potenza di calcolo degli utenti comuni.
Su una vecchia domanda.
> Esempi qui https://www.mql5.com/ru/articles/3473
Una buona variante è quando viene trovato un modello: ternario e test hanno quasi lo stesso errore
Sui mercati accade più spesso qualcosa di simile: un buon test, ma dopo qualche passo di addestramento (nella figura dopo il terzo) inizia il retraining e l'errore del test inizia a crescere. Le immagini si riferiscono alle reti neurali, ma si verifica qualcosa di simile anche con le foreste e i boost, quando il modello diventa sovrallenato.
La regolarità viene sempre trovata - questo è il principio - la questione è se questa regolarità continuerà ad apparire o meno.
Non so che tipo di campione avete avuto. Ho avuto casi in cui il test imparava più velocemente dell'addestramento, ma più spesso accadeva il contrario e c'era un delta notevole tra i due. In condizioni ideali, ovviamente, la differenza sarà minima.
Posso dire con certezza che i modelli sono sottoaddestrati solo perché i campioni non sono molto simili e l'addestramento si interrompe quando non ci sono miglioramenti.
Un giorno vi mostrerò come appare graficamente il campione riqualificato: si tratta di due protuberanze separate da angoli....
Tagliare ancora a metà il campione di allenamento.
Ci sono solo 306 modelli, il profitto medio per esame è di -2791 punti.
Ma ho ottenuto questo modello
Con queste caratteristiche
L'aspettativa di Mat è certamente diminuita, ma Recall è cresciuta due volte - a causa di questo e di un grafico con un gran numero di offerte.
Sono stati utilizzati tali predittori:
E ce ne sono 9 in meno rispetto al campione - cercherò di prendere solo questi e di allenarmi sull'intero campione (su tutte le linee ferroviarie).
Le suddivisioni vengono effettuate solo fino al quantum. Tutto ciò che si trova all'interno del quanto viene considerato con gli stessi valori e non viene ulteriormente suddiviso. Non capisco perché cerchiate qualcosa in quantum, il suo scopo principale è quello di velocizzare i calcoli (lo scopo secondario è quello di caricare/generalizzare il modello in modo che non ci siano ulteriori suddivisioni, ma si può semplicemente limitare la profondità dei dati float) Io non lo uso, faccio solo modelli su dati float. Ho effettuato la quantizzazione su 65000 parti: il risultato è assolutamente identico al modello senza quantizzazione.
Personalmente, ho notato che i predittori, almeno i miei, non hanno transizioni graduali di probabilità, ma piuttosto avvengono bruscamente e cambiano alla deviazione opposta, ad esempio era +5 e immediatamente è diventato -5.
Ho notato anche qualcosa di simile. Aumentare la profondità di 1 cambia drasticamente la redditività, a volte in + a volte in -.
In effetti, ci sarà un - 0,5 :) Ma in questo modo sarà possibile suddividere il predittore in intervalli utili (contenenti informazioni potenzialmente utili).
Ci sarà una divisione che dividerà i dati in due settori - uno con tutti 0, l'altro con tutti 1. Non so come si chiami il quanta, credo che il quanta sia il numero di settori ottenuti dopo la quantizzazione. Forse è il numero di suddivisioni, come intende lei.