Informazioni sul profilatore di codice MT5
Backtest in esecuzione a:
2021.07.10 08:00: 37.101 Core 01 EURUSD, H1: 230861 ticks, 998 barre generate. Il test è passato in 0: 03: 09.367 (compresa la pre-elaborazione dei tick 0: 00: 00.515).
Ho aggiunto del codice per misurare il tempo di esecuzione di SymbolInfoTick () usando GetMicrosecondCount ().
ulong start= GetMicrosecondCount (); //--- Get tick information if (! SymbolInfoTick (symbol,tick)) return ( false ); BENCH += GetMicrosecondCount ()-start;
Risultato:
2021.07.10 08:00: 37.101 Core 01 2021.05.30 23:59:59 Totale = 1209572 Eseguito = 836973 in 661874 microsecondi
Così, SymbolInfoTick () ha preso un totale di 661 millisecondi sui dati storici in 3 minuti e 9 secondi. Tuttavia, il profiler mostra che utilizza il 74,71% delle misure. Non capisco quanto questo sia accurato o utile.
Un altro esempio di dati strani.

Secondo le statistiche globali, SymbolInfoTick () era nello stack delle chiamate 209 volte. Ma nel codice c'è scritto 210. Buona precisione.
Secondo le statistiche globali, SymbolInfoTick è campionato 209 volte (che è lo 0,83% di tutti i campioni). OK. Ora i dati del codice dicono che lo raggiunge 1 volta (che ora è 1,49%, quindi se si guarda l'altro totale, qual è?). Una volta calcolato, 1 uguale a 1,49% significa che la quantità totale (100%) è 67. Così, l'1,49% si riferisce a OnTimer (), che è la funzione principale in questo caso. Ma come può esserci 1 lì e 209 nelle statistiche globali?
Anche se non è un errore, come può essere rapidamente utile (cosa che un profiler dovrebbe essere, secondo me)?
Un altro
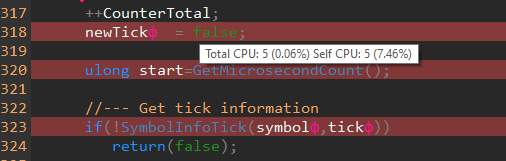
Questa è una linea di codice sopra SymbolInfoTick (), come mostrato prima. Quindi, un'assegnazione come newTick = false è stata "selezionata" 5 volte! Altre 5 volte dopo aver chiamato SymbolInfoTick () ( 1 - 1,49%)? A parte gli scherzi?
Chiedetevi cos'è e qual è la differenza:
- Profilazione basata sul campionamento (come abbiamo ora, simile a Visual Studio C++ e altri)
- Profilazione basata su strumenti di codice (come facevamo prima)
Chiedetevi cos'è e qual è la differenza:
- Profilazione basata sul campionamento (come abbiamo ora, simile a Visual Studio C++ e altri)
- Profilazione basata sulla strumentazione del codice (come avevamo prima)
La differenza è evidente.
Il problema è usarlo nella pratica con dati incoerenti ed errori.
Un altro esempio di dati strani.
Secondo le statistiche globali, SymbolInfoTick () era nello stack delle chiamate 209 volte. Ma nel codice c'è scritto 210. Buona precisione.
Secondo le statistiche globali, SymbolInfoTick è campionato 209 volte (che è lo 0,83% di tutti i campioni). OK. Ora i dati del codice dicono che lo raggiunge 1 volta (che ora è l'1,49%, quindi se si guarda l'altro totale, qual è?). Una volta calcolato, 1 uguale a 1,49% significa che la quantità totale (100%) è 67. Così, l'1,49% si riferisce a OnTimer (), che è la funzione principale in questo caso. Ma come può esserci 1 lì e 209 nelle statistiche globali?
Anche se non è un errore, come può essere rapidamente utile (cosa che un profiler dovrebbe essere, secondo me)?
Lo screenshot mostra le statistiche per la stringa chiamante, non la funzione SymbolInfoTick.
In totale, la stringa data è stata misurata 210 volte, una volta che c'era uno "stop" esattamente sulla stringa, prima della chiamata di SymbolInfoTick o subito dopo, e 209 volte come stringa di ritorno da SymbolInfoTick
Un altro
Questa è una linea di codice sopra SymbolInfoTick (), come mostrato prima. Quindi, un'assegnazione come newTick = false è stata "selezionata" 5 volte! Altre 5 volte dopo aver chiamato SymbolInfoTick () ( 1 - 1,49%)? A parte gli scherzi?
Non capisco bene quello che c'è scritto.
Per leggere questa schermata: la stringa è stata "fermata" 5 volte, del carico totale questo è 0,06%, per il codice della funzione a cui la stringa appartiene questo è 7,46%
Il contatore "Self CPU" mostra l'effetto del codice della stringa sulla velocità della funzione in cui si trova la stringa.
Importante, il tempo della funzione chiamata nella stringa non è contato da questo contatore, forse questo è sbagliato, pensiamo.
Il contatore "Total CPU" mostra l'effetto del codice della stringa sull'intero programma, e questo contatore tiene conto delle funzioni chiamate nella stringa.
Non capisco bene quello che è scritto.
Il modo in cui dovreste leggere questo screenshot è questo: la linea è "fermata" 5 volte, del carico totale è lo 0,06%, per il codice della funzione a cui la linea appartiene è il 7,46%
Sì, lo so. (Scusate per il mio tono precedente, mi sono un po' arrabbiato).
Il problema è:
newTickф = false ; // Total CPU : 5 (0.06%) Self CPU : 5 (7.46%)
finora
if (! SymbolInfoTick (symbolф,tickф)) // Total CPU : 210 (2.57%) Self CPU : 1 (1.49%)
La CPU generale va bene.
Ma per quanto riguarda Self CPU, come è possibile che "newTick = false" sia uguale a 5 e una chiamata di funzione come SymbolInfoTick () sia uguale solo a 1? Per me non ha senso.
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Ho iniziato a usare un nuovo profiler. In questa sezione potremmo centralizzare le informazioni su come usarlo correttamente.
Per cominciare ho alcune domande su cose strane riguardo ai dati restituiti dal profiler.
Il rapporto di profilazione che viene utilizzato in un EA in esecuzione su dati storici:
2021.07.08 15:43:06.269 MQL5 profiler 139098 total measurements, 0/0 errors, 320 mb of stack memory analyzed (92848/1073741824)
2021.07.08 15:43:06.269 MQL5 profiler 982065 frame di funzioni totali trovati (279627 codice mql5, 122460 built-in,571051 altro, 8927 sistema)
Risultati (Funzioni per chiamata):
Q1. Il rapporto dice 139098 misure, ma OnTick () Total CPU è 150026, come è possibile? (ma CopyHistoryData 80087 come 57,58% significa correttamente 100% = 139098).
Q2. Il rapporto dice 571.051 altre "funzioni". Cosa sono queste funzioni se non sono funzioni mql, embedded o di sistema?
Q3. CopyHistoryData mostra 80087 Total CPU, con 3 chiamate di funzione segnalate (CopyHigh, CopyLow, CopyTime) che hanno diversi totali di CPU, ok. Tuttavia, la CPU nativa per queste funzioni è la stessa e uguale alla CPU totale (stack delle chiamate). Questo sembra non essere corretto poiché a 80087 (stack) per CopyHistoryData la somma per 3 funzioni è 62.161 (44286 + 9448 + 8427), come può essere che con 62.161 chiamate rileva 80.087 pause in queste 3 funzioni? Impossibile, l'unica spiegazione è che questo numero è globale per CopyHistoryData e quindi inutile. Mi manca qualcosa?