Reti neurali. Domande degli esperti. - pagina 5
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
D'accordo. È quello che chiedevo, qual è il rapporto tra errore e profitto, preferibilmente su OOS....))
Troppo joo hai detto che il risultato nued potrebbe essere dovuto alla normalizzazione dei dati, ho risposto che non c'era.
Sono d'accordo con Leo che non è sempre il criterio dell'errore che determina il profitto finale, ma è l'errore che conta nel compito che ho davanti a me ora. Stasera posterò la previsione fatta dalla griglia per avere le opinioni degli altri sulla qualità della previsione e i possibili miglioramenti)
Хорошо, чуть позже (часа через 2-3), попробую обоснованно показать, каким образом профит (или что то другое, не важно, что мы хотим получить от сети) зависит от фитнес функции.
А гарантию того, что мы получим профит в будующем, конечно, никто дать никогда не сможет. А вот к чему стремится должна сетка, пожалуй, мы должны определять для неё однозначно.
Non devi perdere tempo, perché la differenza tra "volere" e "ottenere" non è affatto filosofica, anche se è formulata in termini filosofici di "soggettivo" e "oggettivo".
Il fatto che i risultati sul fit siano inversamente proporzionali all'errore quadratico medio è qualcosa che sappiamo senza di voi.
Inequivocabilmente la rete deve mirare a un profitto sull'OOS. Altrimenti non ha senso.
То, что результаты на подгонке обратно пропорциональны среднеквадратичной ошибке - это мы и без Вас знаем.
State usando anche l'errore quadratico medio? Lei è il padre della rete emc. :)
Reshetov ha scritto(a) >>.
Sicuramente la rete deve puntare a un profitto sull'OOS. Altrimenti non ha senso.
È comprensibile. Un'altra questione è come dovrebbe sforzarsi per ottenerlo.
Вы тоже что ли используете среднеквадратичную ошибку? Отец эмкуэльных сетей Вы наш. :)
Это и ежу понятно. Другой вопрос, как она должна к этому стремится.
Non uso l'errore quadratico medio per il trading, perché caratterizza solo la qualità del fit.
Quindi l'errore nel campione non dovrebbe in alcun modo tendere a
Come promesso, pubblico una foto e una spiegazione. Rete: MLP uno strato nascosto. 2000 punti in formazione. 1000 sull'out of sampler) ho ricevuto corrente e pre EMA dalla prima immagine e pre-close dalla prima e dalla seconda. Questo è tutto! Perché tutto e così poco? Perché l'aumento del numero di neuroni, degli strati, degli ingressi ecc. non influenza affatto il risultato. Questo è ciò che mi spaventa) E ciò che viene mostrato come una previsione, si può ottenere, beh, una formula molto semplice, che viene calcolata a mano. Perché non mi è chiaro. Cosa dovrei cambiare? Si può fare meglio?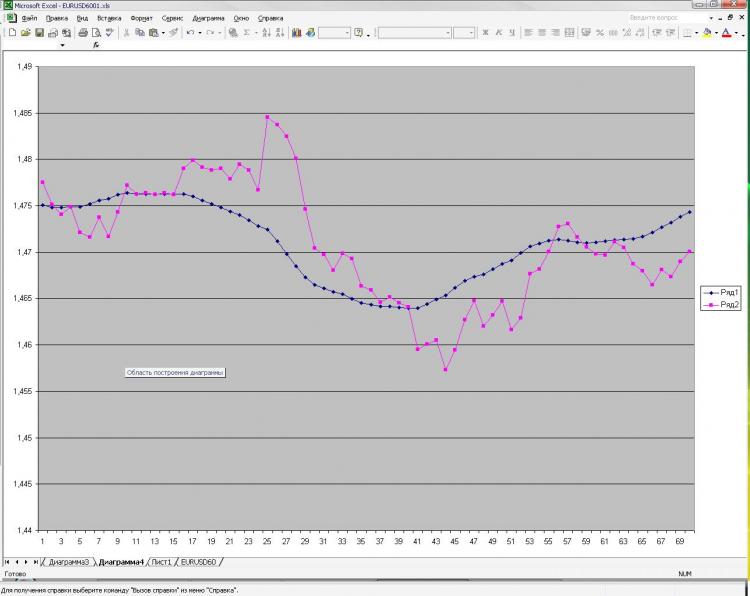
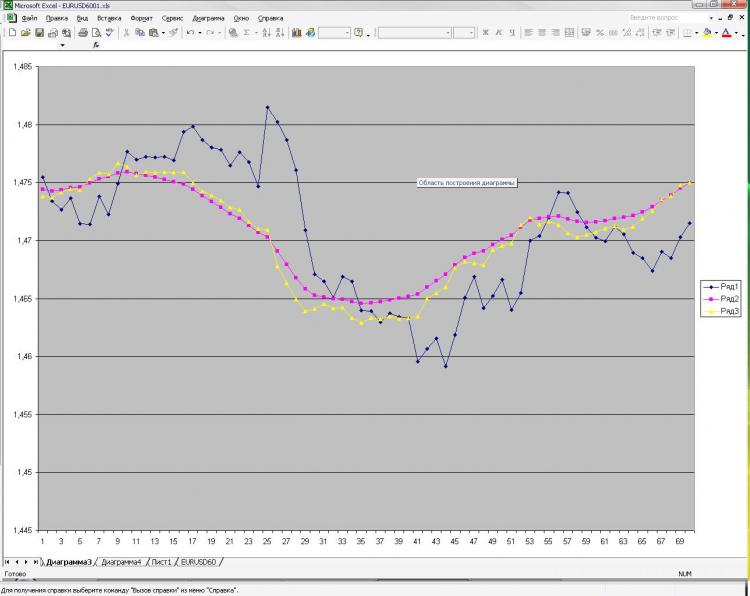
Как и обещал выкладываю картинку и пояснения к ней. Сеть: MLP один скрытый слой. 2000 точек в обучении. 1000 на аут оф сампле) На вход были даны текущее и пред значение ЕМА с первой картинки, а также пред клоуз с первой и второй картинки. Все! Почему все и так мало? Да потому, что увеличение кол-ва нейронов, слоев, входов и т.д. на результат ВООБЩЕ не влияет. Это меня и пугает) Причем, то, что изображено в качестве прогноза, можно получить, ну очень простой формулой, которая ручками считается. Почему так мне непонятно. Что нужно менять? Можно ли сделать лучше?
Avete descritto il problema dell'approssimazione. Due punti di "riferimento" non sono sufficienti per descrivere la forma. Inoltre, si fornisce un altro punto di forza ciascuno, che non solo non descrive la curvatura, ma anche una linea retta. Prova almeno 3 punti da ogni serie di parametri di input. Cioè tre punti EMA e tre punti di clausola, quindi 6 neuroni di ingresso, con 6 a 12 neuroni nello strato nascosto. Un numero maggiore di neuroni nello strato nascosto non è ragionevole per questo problema.
Изначально я давал 40 последних клоузов с первого и второго чарта, а также 40 значений ема с первого чарта - результат тот же, почти один в один! Давал вместо абс значений %-ые приращения - тоже самое! Разница лишь в сотых долях %. Если итоговый "прогноз" и был более плавный, но я разницы на заметил. Можно подать одино из пред значений ЕМА, которую и нужно получить на выходе. В этом случае прогноз 100% т.к. формула ЕМА как Вы помните реккурентная, но в этом случае сети не нужны))))) Вот я и не могу понять, что такое, где я ошибаюсь.
Dammi un campione qui, lo proverò in Statistica