Ottimizzazione degli algoritmi.
joo
Per cominciare, penso che tu debba portare il codice a:
1. Compilabile.
2. Forma leggibile.
3. Commento.
In linea di principio, l'argomento è interessante e urgente.
joo
Per cominciare, penso che tu debba portare il codice a:
1. Compilabile.
2. Forma leggibile.
3. Commento.
Ok.
Abbiamo una matrice ordinata di numeri reali. Devi scegliere una cella della matrice con una probabilità corrispondente alla dimensione del settore immaginario della roulette.
Il set di numeri di prova e la loro probabilità teorica di cadere sono calcolati in Excel e presentati per il confronto con i risultati dell'algoritmo nell'immagine seguente:
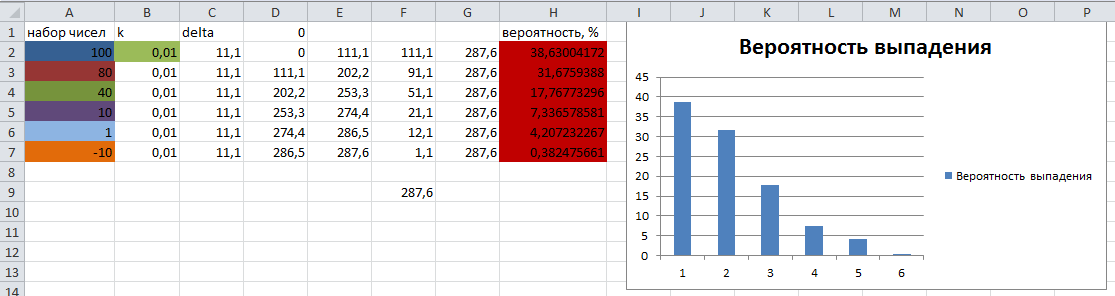
Il risultato dell'esecuzione dell'algoritmo:
2012.04.04 21:35:12 Roulette (EURUSD,H1) h0 38618465 38.618465
2012.04.04 21:35:12 Roulette (EURUSD,H1) h1 31685360 31.68536
2012.04.04 21:35:12 Roulette (EURUSD,H1) h3 7.334754 7.334754
2012.04.04 21:35:12 Roulette (EURUSD,H1) h4 4205492 4.205492
2012.04.04 21:35:12 Roulette (EURUSD,H1) h5 385095 0.385095
2012.04.04 21:35:12 Roulette (EURUSD,H1) 12028 ms - Tempo di esecuzione
Come potete vedere, i risultati della probabilità che la "palla" cada sul settore corrispondente sono quasi identici a quelli calcolati teoricamente.
#property script_show_inputs //--- input parameters input int StartCount=100000000; // Границы соответствующих секторов рулетки double select1[]; // начало сектора double select2[]; // конец сектора //—————————————————————————————————————————————————————————————————————————————— void OnStart() { MathSrand((int)TimeLocal());// сброс генератора // массив с тестовым набором чисел double array[6]={100.0,80.0,40.0,10.0,1.0,-10.0}; ArrayResize(select1,6);ArrayInitialize(select1,0.0); ArrayResize(select2,6);ArrayInitialize(select2,0.0); // счетчики для подсчета выпадений соответствующего числа из тестового набора int h0=0,h1=0,h2=0,h3=0,h4=0,h5=0; // нажмём кнопочку секундомера int time_start=(int)GetTickCount(); // проведём серию испытаний for(int i=0;i<StartCount;i++) { switch(Roulette(array,6)) { case 0: h0++;break; case 1: h1++;break; case 2: h2++;break; case 3: h3++;break; case 4: h4++;break; default: h5++;break; } } Print((int)GetTickCount()-time_start," мс - Время исполнения"); Print("h5 ",h5, " ",h5*100.0/StartCount); Print("h4 ",h4, " ",h4*100.0/StartCount); Print("h3 ",h3, " ",h3*100.0/StartCount); Print("h1 ",h1, " ",h1*100.0/StartCount); Print("h0 ",h0, " ",h0*100.0/StartCount); Print("----------------"); } //—————————————————————————————————————————————————————————————————————————————— //—————————————————————————————————————————————————————————————————————————————— // Рулетка. int Roulette(double &array[], int SizeOfPop) { int i=0,u=0; double p=0.0,start=0.0; double delta=(array[0]-array[SizeOfPop-1])*0.01-array[SizeOfPop-1]; //------------------------------------------------------------------------------ // зададим границы секторов for(i=0;i<SizeOfPop;i++) { select1[i]=start; select2[i]=start+MathAbs(array[i]+delta); start=select2[i]; } // бросим "шарик" p=RNDfromCI(select1[0],select2[SizeOfPop-1]); // посмотрим, на какой сектор упал "шарик" for(u=0;u<SizeOfPop;u++) if((select1[u]<=p && p<select2[u]) || p==select2[u]) break; //------------------------------------------------------------------------------ return(u); } //—————————————————————————————————————————————————————————————————————————————— //—————————————————————————————————————————————————————————————————————————————— // Генератор случайных чисел из заданного интервала. double RNDfromCI(double min,double max) {return(min+((max-min)*MathRand()/32767.0));} //——————————————————————————————————————————————————————————————————————————————
OK.
Abbiamo una matrice ordinata di numeri reali. Dobbiamo selezionare una cella nella matrice con una probabilità corrispondente alla dimensione del settore immaginario della roulette.
Spiega il principio dell'impostazione della "larghezza del settore": corrisponde ai valori della matrice? O è impostato separatamente?
Questa è la domanda più oscura, il resto non è un problema.
Seconda domanda: cos'è il numero 0,01. Da dove viene?
In breve: ditemi dove trovare le corrette probabilità di abbandono dei settori (larghezza come frazione della circonferenza).
È possibile solo la dimensione di ogni settore. A condizione (l'impostazione predefinita) che la dimensione negativa non esista in natura. Anche nel casinò. ;)
Spiega il principio dell'impostazione della "larghezza del settore": corrisponde ai valori della matrice? O è impostato separatamente?
La larghezza dei settori non può corrispondere ai valori della matrice, altrimenti l'algoritmo non funzionerà per tutti i numeri.
Ciò che conta è la distanza tra i numeri. Più tutti i numeri sono lontani dal primo numero, meno è probabile che cadano. In sostanza rimandiamo su una linea retta barre proporzionale alla distanza tra i numeri, regolata da un fattore di 0,01, in modo che l'ultimo numero la probabilità di cadere non era uguale a 0 come il più lontano dal primo. Più alto è il coefficiente, più uguali sono i settori. File Excel allegato, sperimentate con esso.
MetaDriver:
1. In breve: ditemi dove trovare le corrette probabilità di abbandono dei settori (larghezza in frazioni di circonferenza).
2. Potete semplicemente dimensionare ogni settore. assumendo (per default) che le dimensioni negative non esistono in natura. nemmeno nei casinò. ;)1. Il calcolo delle probabilità teoriche è dato in excel. Il primo numero è la probabilità più alta, l'ultimo numero è la probabilità più bassa ma non è uguale a 0.
2) Le dimensioni negative dei settori non esistono mai per qualsiasi insieme di numeri, a condizione che l'insieme sia ordinato in ordine decrescente - il primo numero è il più grande (funzionerà con il più grande dell'insieme ma un numero negativo).
La larghezza dei settori non può corrispondere ai valori della matrice, altrimenti l'algoritmo non funzionerà per tutti i numeri.
hu: Ciò che conta è la distanza tra i numeri. Più distanti sono tutti i numeri dal primo numero, meno probabilità ci sono che cadano. In sostanza rimandiamo su una linea retta segmenti proporzionali alle distanze tra i numeri, corretti di un fattore di 0,01, in modo che la probabilità dell'ultimo numero di non cadere fosse 0 come il più lontano dal primo. Più alto è il coefficiente, più uguali sono i settori. Il file excel è allegato, sperimentatelo.
1. Il calcolo delle probabilità teoriche è dato nell'excel. Il primo numero è la probabilità più alta, l'ultimo numero è la probabilità più bassa ma non uguale a 0.
2. non ci saranno mai dimensioni negative dei settori per qualsiasi insieme di numeri, a condizione che l'insieme sia ordinato in ordine decrescente - il primo numero è il più grande (funzionerà anche con il più grande dell'insieme ma numero negativo).
Il vostro schema "di punto in bianco" fissa la probabilità del numero più piccolo(vmh). Non c'è una giustificazione ragionevole.
// Poiché la "giustificazione" è un po' difficile. Va bene - ci sono solo N-1 spazi tra N chiodi.
Quindi dipende dal "coefficiente", anch'esso tirato fuori dalla scatola. perché 0,01 ? perché non 0,001 ?
Prima di fare l'algoritmo, bisogna decidere il calcolo della "larghezza" di tutti i settori.
zyu: dare la formula per calcolare le "distanze tra i numeri". Quale numero è il "primo"? Che distanza è da se stesso? Non mandarlo a Excel, ci sono stato. È confuso a livello ideologico. Da dove viene il fattore di correzione e perché è così?
Quello in rosso non è affatto vero. :)
sarà molto veloce:
int Selection() { return(RNDfromCI(1,SizeOfPop); }
La qualità dell'algoritmo nel suo complesso non dovrebbe essere influenzata.
E anche se lo fa, questa opzione supererà la qualità a scapito della velocità.
1. Il vostro schema "di punto in bianco" fissa la probabilità del numero più piccolo(vmh). Non c'è una giustificazione ragionevole. Quindi(vmh) dipende dal "coefficiente" anche "fuori dalla scatola". perché 0,01 ? perché non 0,001 ?
2. Prima di fare l'algoritmo, bisogna decidere il calcolo della "larghezza" di tutti i settori.
3. zu: dare la formula per calcolare le "distanze tra i numeri". Quale numero è il "primo"? Quanto è lontano da te? Non mandarlo a Excel, ci sono stato. È confuso a livello ideologico. Da dove viene il fattore di correzione e perché esattamente?
4. Quello evidenziato in rosso non è affatto vero. :)
1. Sì, non è vero. Mi piace questo coefficiente. Se ti piace un altro, ne userò un altro - la velocità dell'algoritmo non cambierà.
2. la certezza è raggiunta.
3. ok. abbiamo un array ordinato di numeri - array[], dove il numero più grande in array[0], e un raggio di numeri con un punto di partenza 0,0 (potete prendere qualsiasi altro punto - non cambierà nulla) e diretto in direzione positiva. Disponi i segmenti sulla semiretta in questo modo:
start0=0=0 end0=start0+|array[0]+delta|
start1=end0 end1=start1+|array[1]+delta|
start2=end1 end2=start2+|array[2]+delta|
......
start5=end4 end5=start5+|array[5]+delta|
Dove:
delta=(array[0]-array[5])*0.01-array[5];
Questa è tutta l'aritmetica. :)
Ora, se lanciamo una "palla" sul nostro raggio segnato, la probabilità di colpire un certo segmento è proporzionale alla lunghezza di quel segmento.
4. Perché avete evidenziato gli errori (non tutti). Dovresti evidenziare:"Essenzialmente stiamo tracciando sulla linea dei numeri i segmenti proporzionali alle distanze tra i numeri, corretti con un fattore di 0,01 in modo che l'ultimo numero non abbia una probabilità di colpire lo 0".
sarà molto veloce:
int Selection() { return(RNDfromCI(1,SizeOfPop); }
La qualità dell'algoritmo nel suo complesso non dovrebbe essere influenzata.
E se anche solo leggermente influenzato, supererà la qualità a scapito della velocità.
:)
Stai suggerendo di selezionare semplicemente un elemento dell'array a caso? - Questo non tiene conto delle distanze tra i numeri della matrice, quindi la tua opzione è inutile.
- www.mql5.com
:)
Stai suggerendo di selezionare semplicemente un elemento dell'array a caso? - Questo non tiene conto della distanza tra i numeri nell'array, quindi la tua opzione è inutile.
non è difficile da controllare.
È confermato sperimentalmente che non è adatto?
è confermato sperimentalmente che non ha valore?
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Accetti la politica del sito e le condizioni d’uso
Suggerisco di discutere qui i problemi di logica degli algoritmi ottimali.
Se qualcuno dubita che il suo algoritmo abbia una logica ottimale in termini di velocità (o chiarezza), allora è il benvenuto.
Inoltre, do il benvenuto a questo thread a coloro che vogliono praticare i loro algoritmi e aiutare gli altri.
Originariamente ho postato la mia domanda nel ramo "Domande da un Dummie", ma mi sono reso conto che non appartiene a quel ramo.
Quindi, per favore, suggerite una variante più veloce dell'algoritmo "roulette" di questa:
Chiaramente, gli array possono essere portati fuori dalla funzione, così non devono essere dichiarati ogni volta e ridimensionati, ma ho bisogno di una soluzione più rivoluzionaria. :)