"New Neural" è un progetto di motore di rete neurale Open Source per la piattaforma MetaTrader 5. - pagina 56
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
Sì, è esattamente quello che volevo sapere.
A mql5
SZ la più grande preoccupazione al momento è se i dati dovranno essere copiati in speciali array della CPU o se sarà supportato il passaggio di un array come parametro in una normale funzione. Questa domanda può cambiare radicalmente l'intero progetto.
ZZY puoi rispondere nei tuoi piani di dare solo OpenCL API, o hai intenzione di avvolgerlo nei tuoi wrapper?
2) Ci sarà un wrapper, solo le GPU HW saranno supportate (con supporto OpenCL 1.1).
Le selezioni multiple di GPU, se presenti, saranno possibili solo attraverso le impostazioni del terminale.
OpenCL sarà usato in modo sincrono.
Sì, è esattamente quello che volevo sapere.
A mql5
SZ La preoccupazione principale al momento è se i dati dovranno essere copiati in speciali array della CPU o se sarà supportato il passaggio di un array come parametro in una normale funzione. Questa domanda può cambiare radicalmente l'intero progetto.
ZZZY puoi rispondere nei piani di dare solo OpenCL API o hai intenzione di avvolgerlo nei tuoi wrapper?
Giudicando da:
mql5:
Sarete infatti in grado di utilizzare direttamente le funzioni della libreria OpenCL.dll senza dover inserire DLL di terze parti.
Le funzioni OpenCL.dll saranno disponibili come se fossero funzioni native MQL5 mentre il compilatore reindirizzerà le chiamate da solo.
Da questo si può concludere che le funzioni di OpenCL.dll possono essere stabilite già ora (chiamate dummy).
Renat e mql5, ho capito bene l'"ambiente"?
Giudicando da:
Le funzioni OpenCL.dll possono essere usate come se fossero funzioni MQL5 native e il compilatore stesso reindirizzerà le chiamate.
Da questo si può concludere che le funzioni di OpenCL.dll possono essere stabilite già ora (chiamate dummy).
Renat e mql5, ho capito bene la "situazione"?
Finora, questo è lo schema del progetto:
Gli oggetti sono rettangoli, i metodi sono ellissi.I metodi di trattamento sono divisi in 4 categorie:
Questi quattro metodi descrivono l'intera elaborazione su tutti gli strati, i metodi sono importati nell'elaborazione attraverso oggetti metodo, che sono ereditati dalla classe base e sovraccaricati come necessario a seconda del tipo di neurone.
Nikolai, conosci la frase: l'ottimizzazione prematura è la radice di tutti i mali.
Dimenticatevi di OpenCL per ora, dovrete fare qualcosa di decente senza di esso. Avrete sempre il tempo di trasporlo, soprattutto se non è ancora disponibile.
Nikolay, conosci una frase popolare - l'ottimizzazione prematura è la radice di tutti i mali.
Dimenticatevi di OpenCL per ora; avreste potuto scrivere qualcosa di decente senza di esso. Si può sempre cambiare. Inoltre, non c'è ancora una funzione interna.
Sì, è una frase popolare e l'ultima volta ero quasi d'accordo, ma dopo averla analizzata ho capito che non potevo semplicemente pianificarla e poi riprogettarla per la GPU, ha esigenze molto specifiche.
Se pianifichiamo senza GPU, allora sarebbe logico fare un oggetto Neuron, che sarebbe responsabile sia per le operazioni all'interno di un neurone, sia per l'allocazione dei dati di calcolo nelle celle di memoria richieste, ereditando una classe da un antenato comune potremmo facilmente collegare il tipo di neurone richiesto e così via,
Ma avendo lavorato un po' con il mio cervello, ho capito subito che questo approccio distruggerà completamente i calcoli della GPU, il nascituro è destinato a strisciare.
Ma ho il sospetto che il mio post qui sopra vi abbia confuso. Per "metodo di calcolo parallelo" intendo un'operazione abbastanza specifica di moltiplicazione degli input con i pesi in*wg, per metodo di calcolo successivo intendo somma+=a[i] e così via.
Solo per una migliore compatibilità futura con le GPU, propongo di derivare le operazioni dai neuroni e combinarle in una singola mossa in un oggetto di livello, e i neuroni fornirebbero solo informazioni da dove prendere dove mettere.
Lezione 1 qui https://www.mql5.com/ru/forum/4956/page23
Lecture 2 qui https://www.mql5.com/ru/forum/4956/page34
Lecture 3 qui https://www.mql5.com/ru/forum/4956/page36
Lecture 4 qui https://www.mql5.com/ru/forum/4956/page46
Lezione 5 (ultima). Codifica sparsa
Questo argomento è il più interessante. Scriverò questa lezione gradualmente. Quindi, non dimenticate di controllare questo post di tanto in tanto.
In generale il nostro compito è quello di presentare la quotazione del prezzo (vettore x) sulle ultime N barre come una decomposizione lineare in funzioni di base (serie della matrice A):
dove s sono i coefficienti della nostra trasformazione lineare che vogliamo trovare e utilizzare come input per lo strato successivo della rete neurale (ad esempio SVM). Nella maggior parte dei casi, conosciamo le funzioni di base A , cioè le scegliamo in anticipo. Possono essere seni e coseni di diverse frequenze (si ottiene la trasformata di Fourier), funzioni Gabor, Hammoton, wavelets, curlets, polinomi o qualsiasi altra funzione. Se queste funzioni ci sono note in anticipo, allora la codifica rada si riduce a trovare un vettore di coefficienti s in modo tale che la maggior parte di questi coefficienti sia zero (vettore rado). L'idea è che la maggior parte dei segnali informativi hanno una struttura che è descritta da un numero di funzioni di base inferiore al numero di campioni del segnale. Queste funzioni base incluse nella descrizione sparsa del segnale sono le sue caratteristiche necessarie che possono essere utilizzate per la classificazione del segnale.
Il problema di trovare la trasformazione lineare dimessa dell'informazione originale è chiamato Compressed Sensing (http://ru.wikipedia.org/wiki/Compressive_sensing). In generale, il problema è formulato come segue:
minimizzare la norma L0 di s, soggetto a As = x
dove la norma L0 è uguale al numero di valori non nulli del vettore s. Il metodo più comune per risolvere questo problema è la sostituzione della norma L0 con la norma L1, che costituisce la base del metodo di ricerca delle basi(https://en.wikipedia.org/wiki/Basis_pursuit):
minimizza la norma L1 di s, soggetto a As = x
dove la norma L1 è calcolata come |s_1|+|s_2|+...+|s_L|. Questo problema si riduce all'ottimizzazione lineare
Un altro metodo popolare per trovare il vettore sparso s è il matching pursuit(https://en.wikipedia.org/wiki/Matching_pursuit). L'essenza di questo metodo è trovare la prima funzione base a_i di una data matrice A tale che si adatti al vettore di input x con il più grande coefficiente s_i rispetto alle altre funzioni base.Dopo aver sottratto a_i*s_i dal vettore di ingresso, aggiungiamo la prossima funzione base al residuo risultante, e così via, fino a raggiungere l'errore dato. Un esempio del metodo del matching pursuit è il seguente indicatore, che inscrive un seno dopo l'altro nel vettore di input con il minimo residuo: https://www.mql5.com/ru/code/130.
Se le funzioni di baseA(dizionario) non ci sono note in anticipo, dobbiamo trovarle a partire dai dati di inputx utilizzando metodi chiamati collettivamente apprendimento del dizionario. Questa è la parte più difficile (e per me la più interessante) del metodo di codifica sparsa. Nella mia lezione precedente ho mostrato come queste funzioni possono, per esempio, essere trovate dalla regola di Ogi, che rende queste funzioni vettori principali di citazioni in ingresso. Sfortunatamente, questo tipo di funzioni di base non porta a una descrizione disgiunta dei dati di input (cioè il vettore s non è spartito).
I metodi esistenti di apprendimento dei dizionari che portano a trasformazioni lineari disgiunte si dividono in
Imetodi probabilistici per trovare le funzioni di base si riducono a massimizzare la massima verosimiglianza:
massimizzare P(x|A) su A.
Di solito si assume che l'errore di approssimazione abbia una distribuzione gaussiana, il che ci porta a risolvere il seguente problema di ottimizzazione:
(1)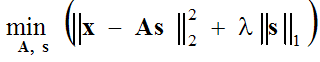 ,
,
che viene risolto in due fasi: (1-fase di codifica sparsa) con le funzioni di base A fisse, l'espressione tra parentesi viene minimizzata rispetto al vettore s, e (2-fase di aggiornamento del dizionario) il vettores trovato è fisso e l'espressione tra parentesi viene minimizzata rispetto alle funzioni di base A usando il metodo di discesa del gradiente:
(2)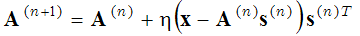
dove (n+1) e (n) in apice denotano i numeri di iterazione. Questi due passi (passo di codifica rada e passo di apprendimento del dizionario) vengono ripetuti fino a quando non viene raggiunto un minimo locale. Questo metodo probabilistico per trovare le funzioni di base è usato ad esempio in
Olshausen, B. A., & Field, D. J. (1996). Emersione delle proprietà del campo recettivo delle cellule semplici con l'apprendimento di un codice sparso per le immagini naturali. Natura, 381(6583), 607-609.
Lewicki, M. S., & Sejnowski, T. J. (1999). Apprendimento di rappresentazioni sovraccomplete. Neural Comput, 12(2), 337-365.
Il metodo delle direzioni ottimali (MOD) usa gli stessi due passi di ottimizzazione (passo di codifica rada e passo di apprendimento del dizionario), ma nel secondo passo di ottimizzazione (passo di aggiornamento del dizionario) le funzioni di base sono calcolate uguagliando la derivata dell'espressione tra parentesi (1) rispetto ad A a zero:
dove otteniamo
(3)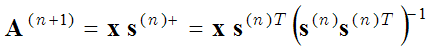 ,
,
dove s+ è una matrice pseudo-inversa. Questo è un calcolo più accurato della matrice di base rispetto al metodo di discesa del gradiente (2). Il metodo MOD è descritto più in dettaglio qui:
K. Engan, S. O. Aase e J.H. Hakon-Husoy. Metodo delle direzioni ottimali per la progettazione del telaio. IEEE International Conference on Acoustics, Speech, and Signal Processing. vol. 5, pp. 2443-2446, 1999.
Calcolare le matrici pseudo-inverse è ingombrante. Il metodo k-SVD evita di farlo, ma non l'ho ancora capito. Potete leggere qui:
M. Aharon, M. Elad, A. Bruckstein. K-SVD: un algoritmo per la progettazione di dizionari sovraccarichi per la rappresentazione sparsa. IEEE Trans. Signal Processing, 54(11), novembre 2006.
Non ho ancora capito i metodi di clustering e on-line per trovare il dizionario. I lettori interessati possono fare riferimento al prossimo sondaggio:
R. Rubinstein, A. M. Bruckstein, and M. Elad, "Dictionaries for sparse representation modeling," Proc. of IEEE , 98(6), pp. 1045-1057, giugno 2010.
Qui ci sono alcune interessanti lezioni video su questo argomento:
http://videolectures.net/mlss09us_candes_ocsssrl1m/
http://videolectures.net/mlss09us_sapiro_ldias/
http://videolectures.net/nips09_bach_smm/
http://videolectures.net/icml09_mairal_odlsc/
Questo è tutto per ora. Espanderò questo argomento nei prossimi post, man mano che sarò in grado e che i visitatori di questo forum saranno interessati.
Nikolai, conosci la frase popolare - l'ottimizzazione prematura è la radice di tutti i mali.
È una frase così comune per gli sviluppatori per coprire la loro inutilità, che si può essere schiaffeggiati per ogni volta che la si usa.
La frase è fondamentalmente dannosa e assolutamente sbagliata, se stiamo parlando di sviluppo di software di qualità con un lungo ciclo di vita e orientamento diretto all'alta velocità e ai carichi elevati.
L'ho verificato molte volte nei miei molti anni di pratica del project management.
È una frase così comune per coprire le cazzate degli sviluppatori che si può ottenere uno schiaffo per ogni volta che la si usa.
Quindi dovete prendere in considerazione alcune caratteristiche che appariranno chissà quando con chissà quale interfaccia in anticipo perché vi dà un aumento delle prestazioni?
L'ho provato molte volte nei miei anni di pratica di project management.