L'apprendimento automatico nel trading: teoria, modelli, pratica e algo-trading - pagina 1929
Ti stai perdendo delle opportunità di trading:
- App di trading gratuite
- Oltre 8.000 segnali per il copy trading
- Notizie economiche per esplorare i mercati finanziari
Registrazione
Accedi
Accetti la politica del sito e le condizioni d’uso
Se non hai un account, registrati
a seguito di una conversazione personale
la tua opzione
versione semplice
come potete vedere i valori sono abbastanza diversi, potete controllare voi stessi
Nel mio modello.
quindi solo una colonna, ma non ha molta importanza.
===================UPD
Amico, sono diversi ogni volta che si esegue umap_tranform, non dovrebbe essere
Non stavo prestando attenzione. È passato molto tempo...
a seguito di una conversazione personale
la tua opzione
versione semplice
come potete vedere i valori sono abbastanza diversi, potete controllare voi stessi
Nel mio modello.
quindi solo una colonna, ma non ha molta importanza.
===================UPD
Amico, sono diversi ogni volta che si esegue umap_tranform, non dovrebbe essere così
Di solito per la ripetibilità si imposta il Seed (dell'HSS integrato) su qualche valore. In caso contrario, si usa il random. Forse anche questo pacchetto ha Seed - controlla.
Penso di sì, ma il punto è che senza RMS dovrebbe essere sempre lo stesso, nel pacchetto analogico "umap" il risultato è sempre lo stesso
per te, con la sola speranza che tu impari la r-ku)
ci sono due funzioni
get.indи
get.targetil primo crea una data serie di indicatori, il secondo il target dello zigzag
tutto quello che dovete fare è caricare i dati con un prezzo di chiusura di 10k e scriverli nella variabile clos
e ottenere il vostro umap con l'obiettivo
https://github.com/jlmelville/uwotper te, con la sola speranza che tu impari il p)
ci sono due funzioni
и
il primo crea un set di indicatori di data, il secondo crea un obiettivo di zigzag
tutto quello che dovete fare è caricare i dati con un prezzo di chiusura di 10k e scriverli nella variabile clos
e ottenere il vostro umap con l'obiettivo
https://github.com/jlmelville/uwotMolto piacere di conoscerti, grazie!
Vorrei più commenti :)
La questione qui è come sincronizzare i predittori dal file con l'obiettivo risultante?
Molto piacere di conoscerti, grazie!
Vorrei più commenti :)
La domanda qui è come sincronizzare i predittori dal file con l'obiettivo?
Bene, poiché l'obiettivo è costruito usando il prezzo, è già in sincronia, e se i predittori sono costruiti usando la stessa scena, significa che lo sono anche loro)
Oppure non capisco la domanda.
Ho cercato di nominare le variabili in modo che fossero comprensibili senza commenti
Una domanda da un nerd.
Ci sono tre variabili A, B, C. Una sorta di condizione è scritta a mano da loro. Per esempio.
Voglio riprodurre questa condizione automaticamente. Non ho bisogno di trovarlo, perché lo so già. Ma ho bisogno di avere, ad esempio, decine di coefficienti di peso la cui combinazione può colpire questa condizione con alta probabilità, quando imposto A, B, C lì (polinomio o HC - non so, perché so zero) e ottenere la condizione originale.
Mi interessa sapere che tipo e quanti pesi di ingresso ha la funzione richiesta, in modo che tali condizioni originali possano essere riprodotte tramite i pesi?
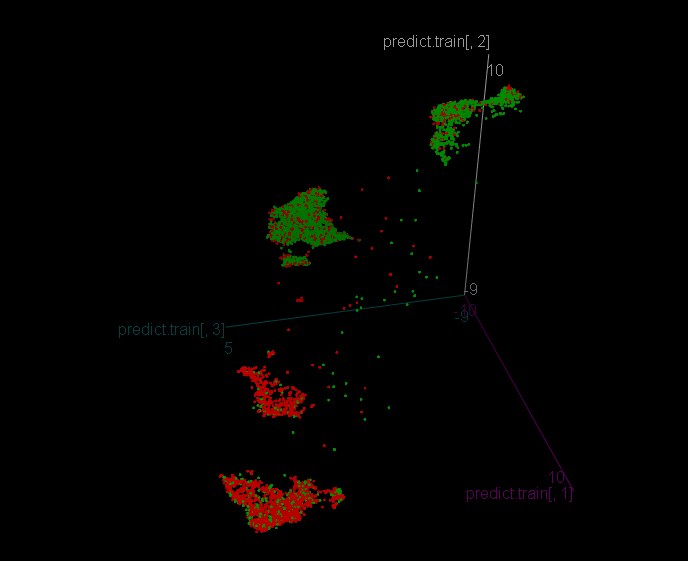
Quindi, come sono stati formati gli alberi sui grappoli, ve lo dico e ve lo mostro.
Abbiamo ottenuto il seguente modello per il riconoscimento delle classi
La storia ha una precisione abbastanza accurata di 0,9196756 - cioè la logica del cluster è abbastanza riproducibile.
Poi ho addestrato un modello per ogni cluster
Cluster 1
Cluster 2
Cluster 3
Cluster 4
Tutti i cluster hanno una precisione di 0,53 circa.
E questo è l'aspetto del modello senza la suddivisione in cluster
La precisione 0,5293815 è circa la stessa dei cluster.
Se confrontiamo i modelli per cluster e un modello ad albero con l'intero campione, vediamo che gli alberi cluster hanno più foglie con informazioni generalizzate sul campione con target 1 e -1, che è teoricamente buono.
Vediamo cosa mostrano i test - prima guardiamo il periodo di allenamento
Modello senza partizionamento dei cluster:
Modello con partizionamento in cluster:
Vediamo che l'accuratezza è migliore con il modello senza clustering, ma commercia di più con il modello su cluster, che permette una migliore performance finanziaria.
Ora guardiamo il campione al di fuori della formazione.
Ed ecco i nostri cluster:
E il modello senza cluster:
La situazione qui sembra essere invertita - molti scambi hanno avuto un effetto negativo quando il mercato ha iniziato a convogliare da aprile.
Ho deciso di guardare le foglie dei modelli di cluster individualmente, se non ci fosse stato alcun cluster, su un istogramma discendente:
Un totale di 6 foglie non redditizie (zero obiettivo rimosso - è un divieto di ingresso), si scopre che non siamo nel cluster giusto?
Bene, poiché l'obiettivo è basato sul prezzo, è già sincronizzato, e se i predittori sono basati sulla stessa scena, lo sono anche loro)
Oppure non capisco la domanda.
Ho cercato di nominare le variabili in modo che fossero comprensibili senza commenti
Come prendere un set di dati con predittori e prezzo di chiusura e caricarlo con la specifica di una colonna con prezzo di chiusura invece di usare la variante di generazione di indicatori in R?
Da quanto ho capito, dato che l'obiettivo è ZZ tops, allora una parte del campione con predittori dovrebbe essere filtrata, qui, e quindi per alimentare i predittori si dovrebbe filtrare anche la tabella con predittori, o cosa?
Una domanda da un nerd.
Ci sono tre variabili A, B, C. Una sorta di condizione è scritta a mano da loro. Per esempio.
Voglio riprodurre questa condizione automaticamente. Non ho bisogno di trovarlo, perché lo so già. Ma ho bisogno di avere, ad esempio, decine di coefficienti di peso la cui combinazione può colpire questa condizione con alta probabilità, quando imposto A, B, C lì (polinomio o HC - non so, perché so zero) e ottenere la condizione originale.
Mi interessa sapere che tipo e quanti pesi di ingresso ha la funzione richiesta, in modo che tali condizioni originali possano essere riprodotte tramite i pesi?
in alternativa
Su input di NS - valori A,B,C n volte (diciamo, 1000), su output - risposte della vostra formula per questi valori come 0;1. Provate. E vedere l'errore di classificazione e quanto bene il modello riproduce la condizione.
se volete vedere esattamente quale tipo e interpretarlo, potete farlo attraverso gli alberi.
Variante 2 (se la prima non ha funzionato bene) - A, B, A-B, C, A+3*C, 2B - variabili, tutte le stesse della prima variante da mettere nell'albero. E si può vedere la sua struttura come nelle foto di Alexey qui sopra