Discussion of article "Advanced resampling and selection of CatBoost models by brute-force method"
Hi,
Thanks for the article. I tried it but somehow I dont get the nice equity curve (even for the training period) in MT5 backtest as it is shown in python (see below). When I backtest with your EURUSD EA from your article it works. What can I solve the error?
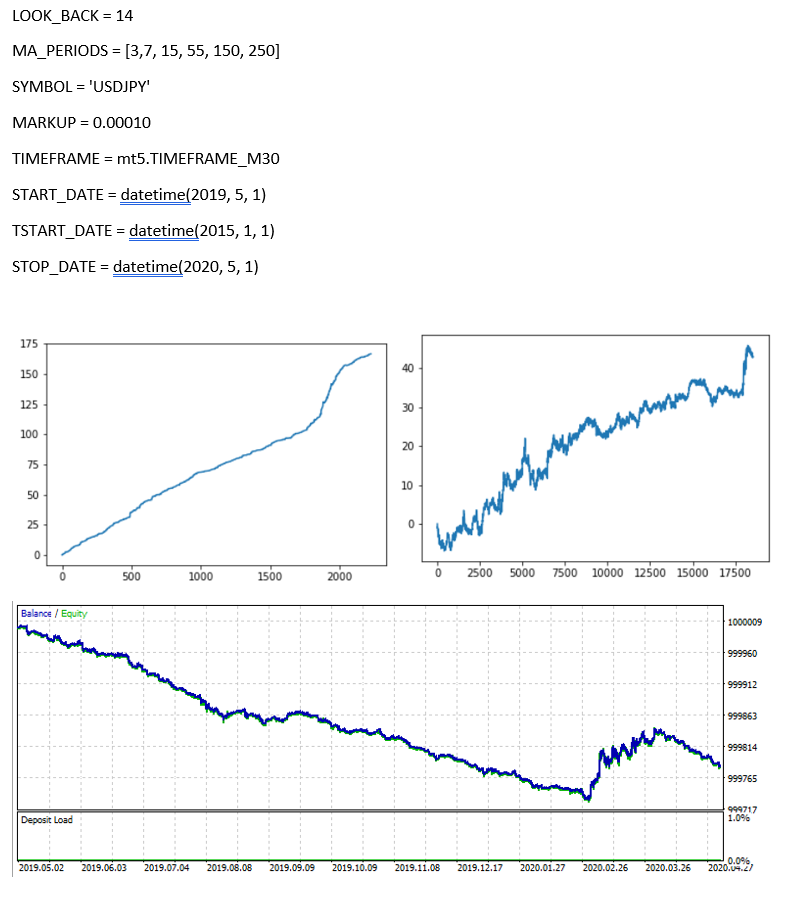
Hi,
Thanks for the article. I tried it but somehow I dont get the nice equity curve (even for the training period) in MT5 backtest as it is shown in python (see below). When I backtest with your EURUSD EA from your article it works. What can I solve the error?
Hi, maybe problem with MARKUP for the custom tester for usdjpy, so results are different
Hi, maybe problem with MARKUP for the custom tester for usdjpy, so results are different
Hi Maxim,
The current article is okay, but limited computing power and curve fitting are biggest concerns to such traditional methods and hence, usually I stay away from testing such approaches.
Are you interested to write an article on implementation of "MuZero" from DeepMind in Forex?
https://deepmind.com/blog/article/muzero-mastering-go-chess-shogi-and-atari-without-rules
https://medium.com/applied-data-science/how-to-build-your-own-muzero-in-python-f77d5718061a
I am asking this to you since I am a basic level MQL5 programmer and it can take a long time for me to write from scratch which you can probably do easily.
Please let me know your thoughts.
I will define what to write for the following in forex coding and can you convert it to MQL5 code:
- The value: how good is the current position?
- The policy: which action is the best to take?
- The reward: how good was the last action?
Thanks.

- deepmind.com
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
New article Advanced resampling and selection of CatBoost models by brute-force method has been published:
This article describes one of the possible approaches to data transformation aimed at improving the generalizability of the model, and also discusses sampling and selection of CatBoost models.
A simple random sampling of labels used in the previous article has some disadvantages, such as:
Model 1 has autocorrelation of residuals, which can be compared to model overfitting on certain market properties (for example, related to the volatility of training data), while other patterns are not taken into account. Model 2 has residuals with the same variance (on average), which indicates that the model covered more information or other dependencies were found (in addition to the correlation of neighboring samples).
Author: Maxim Dmitrievsky