
Força bruta para encontrar padrões (Parte II): Imersão

Introdução
Decidi continuar o tópico levantado no artigo anterior e realizar uma análise aprofundada sobre vários pares de moedas usando uma versão modificada de meu programa. A este respeito, quero agradecer ao usuário Aleksey Vyazmikin por sua contribuição para o desenvolvimento da ideia. Os conselhos do Alexey foram muito úteis a nível técnico e me animaram a realizar este trabalho. No próximo artigo, continuarei a trabalhar com este tópico e proporcionarei ao público dados e resultados muito mais interessantes. Acredito que seja muito importante mostrar e dizer o quão eficaz é a análise de um determinado par de moedas numa escala global, bem como demostrar as diferenças quando se analisa intervalos de tempo de duração máxima e mínima. Claro, devido ao fato de que meu tempo é limitado e minhas capacidades de computação também são limitadas, fui capaz de cobrir apenas alguns pares de moedas e 1 período gráfico, mas acho que é suficiente para nossa primeira experiência com os padrões globais. Ao analisar os dados, usarei adicionalmente os dados do artigo anterior.
Por que este assunto é tão interessante na minha opinião?
Como resultado, para qualquer programador de Expert Advisors no MetaTrader 4 e MetaTrader 5, tudo se resume a incontáveis linhas de código, testes, otimizações, verificações back-forward e, na maioria dos casos, não obtemos o que queremos ver. Este cenário geralmente aborrece uma parte dos programadores que fica entediada. O processo de pesquisa e busca se torna uma rotina. Afinal, se o trabalho não der a recompensa emocional adequada, sem falar no dinheiro, depois de um tempo você acabará desistindo. Aqui acontece o mesmo. Para mim, chegou o momento em que queria me despedir da rotina e começar a automatizar as ações que uma máquina pode realmente realizar com sucesso. Ao contrário de mim, o carro não tem emoções e é um trabalhador ideal. Claro, uma máquina não tem a amplitude de pensamento que uma pessoa possui, mas tem muito poder de computação, e aquelas coisas que uma pessoa pode fazer de forma mais complexa e original, uma máquina pode fazê-las mais simples, mas mais rápido do que uma pessoa. Eu tive escolha, começar a escrever minha própria arquitetura de rede neural capaz de evoluir ou iniciar a abordagem mais simples para resolver o problema. Eu escolhi esta abordagem. Apesar de tudo ser simples, há espaço para criatividade, em contraste com a programação simples de produtos MQL. Por que não trabalhar um modelo universal e apenas melhorá-lo adicionando gradualmente a funcionalidade necessária? Você pode começar com um modelo simples e, em seguida, criar novos modelos com base num princípio operacional específico. Assim, podemos nos livrar da rotina entediante e ir mais longe com nosso desenvolvimento. Na verdade, a preguiça humana é o motor do progresso :-).
Nova versão do programa de força bruta e sua lista de mudanças
Houve apenas uma alteração - à primeira vista insignificante - no programa que está destacada num retângulo vermelho abaixo na imagem. Esta configuração é obtida da segunda guia, onde mostra seu melhor lado. O motivo pelo qual adicionei essa configuração tem um impacto muito forte na qualidade dos resultados finais. Acontece que, durante a análise na primeira guia, todos os resultados foram inicialmente ordenados por indicador de qualidade. O fator de lucro ou valor esperado em pontos foi usado como critério de qualidade. Porém, o programa não nos permitiu avaliar a forma do gráfico - como critério de forma usei o fator de linearidade (similaridade a uma linha reta), o que nos livra da necessidade de verificar visualmente cada variante. Se pensarmos com cuidado, podemos concluir que gráficos mais retos e suaves no final são mais propensos a fornecer uma variante de alta qualidade na segunda guia, e também reduz o número de variantes que serão descartadas por um filtro semelhante na segunda guia. Para calcular este indicador é necessária segunda execução. Se este filtro estiver ativo, a velocidade da força bruta diminui cerca de 2 vezes, mas o que é importante para nós não é a velocidade, mas, sim, a qualidade total dos resultados primários obtidos, pois tudo o que acontece a seguir depende da sua qualidade.
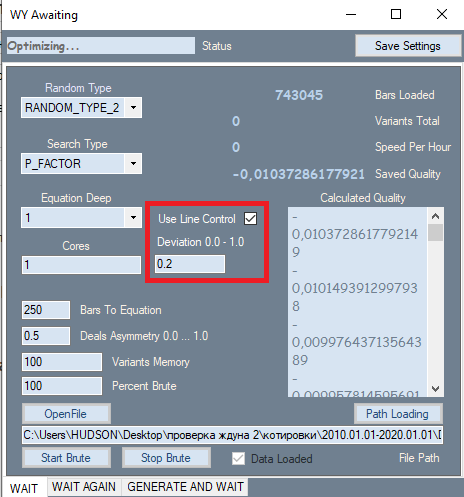
Além do filtro introduzido, o próprio polinômio foi alterado. Agora, o polinômio aceita não apenas os valores Close[i]-Open[i] de barras específicas como argumentos, mas também os seguintes valores:
- Close[i]-Open[i]
- High[i]-Open[i]
- Low[i]-Close[i]
- Low[i]-Open[i]
- High[i]-Close[i]
Agora verifica-se que a fórmula contém todos os dados de preços de uma determinada barra, ao contrário da versão anterior do programa. Claro, a complexidade do polinômio aumenta muito com isso e, como resultado, a velocidade da força bruta diminui, mas agora podemos selecionar fórmulas de mercado melhores e mais eficientes, desde que haja poder de computação suficiente. É claro que podemos formular outras variáveis com a participação desses dados, mas ao usar esses valores no polinômio, verifica-se a implementação desses valores que podem ser uma combinação linear daqueles apresentados, por exemplo
- C1*(High[i]-Close[i]) + C2*(Low[i]-Close[i]) = NewQuant
- se C1 = 1 e C2 = -1
- NewQuant = (High[i]-Close[i]) - (Low[i]-Close[i]) = High[i]-Low[i]
- em outros casos
- NewQuant = (C1-C3)*(High[i]-Close[i])+(C2+C3)*(Low[i]-Close[i]) + C3*((High[i]-Close[i]) - (Low[i]-Close[i])) = (C1-C3)*(High[i]-Close[i])+(C2-C3)*(Low[i]-Close[i]) + C3*(High[i]-Low[i])
Em outras palavras, a partir de uma combinação linear de variáveis, que por sua vez consistem em combinações lineares de outras variáveis, podemos criar novas variáveis sem incluí-las na fórmula básica, e o melhor passo seria não incluir aquelas variáveis que podem ser formadas a partir de outras que já estão na fórmula. Elas aparecerão durante a seleção de coeficientes, dependendo dos valores dos próprios coeficientes.
O novo polinômio será muito mais complicado no final:
- Y = Soma(0,NC-1)( C[i]*Variante do produto(x[1]^p[1]*x[2]^p[2]...*x[N]^p[N]) )
- Soma(0,N)(p[i])=MaxPowOfPolinom
- NC - número total de termos no polinômio, que é igual ao número de coeficientes selecionados
onde x[i] são os argumentos que o polinômio assume, p[i] é a potência à qual elevamos esse argumento. A potência total de todos os fatores constituintes não deve exceder o número que permitimos para nosso polinômio, porque nenhum computador pode lidar com cenários complexos desse gênero. Pessoalmente, quase sempre uso potência 1, ou 2 ou 3 como último recurso, quando o número de barras para a fórmula está se aproximando do mínimo. Mas a verdade é que usar potências mais altos é ineficaz, mesmo em servidores. Poder de processamento insuficiente.
Abaixo estão as variantes para os argumentos. A soma final inclui todas as combinações possíveis de produtos:
- x[i] =Close[i]-Open[i]
- x[i] =High[i]-Open[i]
- x[i] =Low[i]-Close[i]
- x[i] =High[i]-Open[i]
- x[i] =High[i]-Close[i]
Eu também gostaria de falar por que razão nos focamos em torno desse polinômio notório. A questão é que, em última análise, qualquer sistema se resume a um conjunto de condições, uma ou várias condições, não importa, porque as condições são uma função lógica. O conjunto de condições pode ser convertido numa expressão booleana que dá verdadeiro ou falso. É impossível interpretar um sinal assim exceto como Sim ou Não, é impossível determinar o quão forte é o sinal ou ajustá-lo. Claro, se você usar vários indicadores como um sinal, você pode ajustar separadamente os parâmetros de entrada desses indicadores e, como resultado, isso levará a uma mudança na expressão lógica final, ou a uma mudança no sinal, que por sua vez afetará a negociação. Mas acho que isso é extremamente inconveniente, mesmo que eu alterar um ou outro parâmetro de um indicador específico, não saberemos como isso afetará a negociação.
A ideia principal por trás dessa abordagem era simplicidade e eficiência. Por que essa abordagem? Existem várias vantagens:
- Exclusividade da função otimizada
- Dependência da força do sinal em relação ao valor da função
- Fácil de usar
- O único parâmetro otimizado é o valor polinomial
O mais importante é que não precisamos selecionar o número de condições nem seu tipo. Isso ocorre porque inicialmente nos acostumamos com a ideia de que, em vez de procurar um conjunto infinito de condições, podemos reduzi-las todas a uma única função fornecendo um número fracionário positivo ou negativo na saída. Dependendo da confiabilidade de uma função particular, será possível exigir um sinal mais forte a nível de módulo. Em algumas fórmulas, isso levará à escalabilidade. Por escalabilidade, quero dizer a capacidade de amplificar um sinal quando o número de transações diminui.
Basicamente, minha pesquisa, como acho que também seja o caso de outras pessoas, leva a uma única conclusão. O desejo de fortalecer o sinal de entrada leva inevitavelmente a uma diminuição no número de transações por um determinado período. Em termos simples, para qualquer função onde está inevitavelmente presente um componente aleatório, sempre há pontos com um resultado mais previsível do que outros. Se nossa função for eficiente o suficiente, ela pode atingir certos indicadores de previsibilidade com requisitos crescentes para o sinal dessa função. É claro que isso não acontece com todas as funções que satisfazem nossos requisitos primários, mas quanto mais rigorosos estes últimos, maiores são os valores esperados dos indicadores de lucratividade das fórmulas que podemos encontrar usando a busca detalhada de coeficientes. Isso será verdadeiro para o aumento de gradiente e para outros métodos de localização de padrões, também para redes neurais.
Muito depende de qual é a amostra de dados. Quanto menor a amostra, maior a chance de obter um resultado aleatório. Um resultado aleatório é entendido como um resultado que não serve, ou que serve de forma extremamente ruim, se o sistema final for testado com base no histórico global do símbolo usado para pesquisar o padrão.
Tentaremos responder à questão de como a qualidade do sistema de negociação final no futuro depende do tamanho da área analisada e da quantidade de mão de obra necessária para buscar esse sistema. Primeiro, definimos a fórmula do valor esperado para o número de estratégias encontradas ao longo de um período fixo:
- Mn(t) = W(t,F)*Ef(T,N,L)
- Mn é o valor esperado para o número de estratégias encontradas atendendo aos requisitos
- W(t,F) = F*t é o número total de variantes classificadas por unidade de tempo
- Ef(T,N,L) = ? é a eficiência da força bruta, que depende do comprimento do segmento, do tipo de cotação, do número necessário de ordens fechadas e do fator de linearidade exigido, se for levado em consideração na pesquisa (este valor é equivalente à probabilidade de que o indicadores da variante atual terão os valores necessários e suficientes)
- N é o número mínimo permitido de transações que nos servirão para o nosso teste
- L é o fator de linearidade máximo permitido (como um critério de controle adicional)
- F é a frequência de iteração das opções de estratégia
É extremamente difícil determinar a forma da função Ef, mas podemos estimar aproximadamente como será e quais propriedades possui:
")
Para poder representar uma função multidimensional num plano, é necessário fixar todos os seus argumentos com algum tipo de número, exceto o argumento com o qual construímos o próprio gráfico. No nosso caso, estamos interessados na variável T, que representa a duração da amostra analisada, visto que estamos analisando um único período. Se descartarmos essa suposição, podemos considerar o tamanho da amostra como T, isso não mudará a aparência dos gráficos. Naturalmente, estamos interessados em como os 2 argumentos restantes afetarão a aparência do gráfico. Descrevi tudo na imagem. Quanto mais ordens quisermos na versão final, menos sistemas encontraremos que atendam aos nossos requisitos, simplesmente porque é muito mais fácil encontrar um sistema com menos ordens. A mesma consideração se aplica ao fator de linearidade (desvio de uma linha reta), com a única diferença de que o melhor fator de linearidade é aquele que é menor (tende a zero).
Se você não fixar o conceito de qualidade do sistema, porque este valor pode ser tanto um fator de lucro quanto um valor esperado, então você também pode introduzir o conceito de qualidade máxima do sistema encontrado. Da mesma forma, você pode descrever aproximadamente do que depende:
- Mq=Mq(T,N,S)
- S é a configuração da fórmula selecionada
Em outras palavras, a qualidade da estratégia depende diretamente da eficácia de nossa fórmula, bem como de nossas necessidades e da complexidade do site. Além disso, também assumimos que o início da seção é fixo e que cada variação do ponto de início do treinamento é única e fornece parâmetros de início exclusivos. Ou seja, ao escolher uma data de início diferente para o nosso segmento de treinamento, teremos diferentes desempenhos, qualidade final dos sistemas resultantes e outros parâmetros.
Também podemos compreender que cada tipo de desempenho tem um valor máximo, por exemplo, o fator de lucro é infinito, mas não gosto de usá-lo para análise por não ser limitado de cima, já que torna alguns modelos gráficos mais difíceis de perceber. Por isso, em vez do original, eu uso P_FACTOR, meu próprio análogo desse valor, ele não é de forma alguma inferior a ele, apenas está na faixa [-1,1].
- P_FACTOR=(Profit-Loss)/(Profit+Loss)
O máximo desta valor é 1, o que significa que é muito mais conveniente trabalhar com este indicador. A este respeito, você pode criar uma função que descreve o máximo deste indicador dependendo de T (a área selecionada e sua amostra).
- Mx=Mx(T)
Se P_FACTOR for escolhido como indicador ou critério de qualidade, então Mx(T)=1; já se, por exemplo, for o valor esperado, então a forma desta função será desconhecida, mas sabe-se que Mx'(T)>0, em toda a parte positiva do eixo T. Ou seja, a derivada é positiva em qualquer ponto, o que significa que o gráfico está aumentando o tempo todo.
Para o fator de lucro, tudo isso ficará assim:

Aqui, por exemplo, apenas o limite superior do fator de lucro e 2 gráficos, simbolizando 2 fórmulas diferentes com requisitos diferentes. No gráfico, aquele que tem uma cor de limão é melhor, pois é muito menos sujeito a redução de qualidade quando o "T" tende para o infinito.
Para o valor esperado, tudo ficará assim:

Aqui, como no gráfico anterior, existem 2 variações que simbolizam 2 fórmulas diferentes com requisitos diferentes, apenas resta Mx(T), que desempenha o papel de uma assíntota, no sentido de que Mq(T,N,S) é incapaz de superar essa barreira. O Mq(T,N,S) ideal se fundirá com o gráfico Mx(T) e indicará que encontramos o "Graal". É claro que isso nunca acontecerá na realidade, mas é importante entender. Acredito que isso é muito importante para a atitude correta em relação ao mercado, a menos que você queira realmente entender o que é o mercado e valorize o seu tempo.
No Forex, como em qualquer outro mercado, é mais correto e preciso operar apenas com os conceitos da teoria da probabilidade. Vou até escrever abaixo algumas regras básicas de análise matemática no Forex:
- Quase todas as quantidades não são fixas e são substituídas por seus valores esperados
- Os valores esperados de uma amostra maior tendem ao resultado de uma amostra global
- Use probabilidades com mais frequência
A fiabilidade dos dados do site nada mais é do que um indicador de amostragem. Quanto maior a amostra, mais extenso o conjunto de dados de entrada e mais justa a fórmula final. Acontece que como a amostra tende para o infinito, o resultado final tenderá para um valor limite fixo.
Mudanças de template e por que são necessárias?
Como a lógica de trabalho foi melhorada, será necessário editar as funções no template para que funcionem corretamente e aceitem novos parâmetros, a implementação dessas funções é idêntica tanto no programa quanto no código do template, caso contrário simplesmente não funcionará. As funções originais foram aprimoradas com base num valor, mas foram adicionados mais 4 que terão que ser aprimorados. Em primeiro lugar, essas mudanças deveriam dar fórmulas mais qualitativas, na medida em que não é possível avaliar qualitativamente, mas deveria ser óbvio que só vai melhorar. Quanto mais dados são usados numa fórmula, maiores são seus recursos de pesquisa.
Ao escrever este artigo, encontrei uma falha em meu código - combinações de fatores podem ser repetidas, a ordem desses fatores é caótica pela maneira de construir uma função que implementa um polinômio multidimensional. Esta função constrói uma árvore de chamada, mas não pode controlar as permutações de elementos em alguns lugares. Existem duas maneiras de evitar essa situação:
- Controlar todas as permutações possíveis de multiplicadores
- Compensar o número de fatores duplicados na fórmula, dividindo o fator total pelo seu número
Pessoalmente, escolhi a segunda variante. Não é muito original, e a desvantagem é que o coeficiente médio tenderá a 0,5, mas pelo menos esses multiplicadores serão úteis. Para o artigo, usei um polinômio de grau 1, que não é afetado por esse erro, você não precisa se preocupar com isso. Não é difícil calcular o número de combinações para um multiplicador com uma potência total fixa:
- Comb=n!/(n-k)!
- n - número de possíveis multiplicadores independentes
- k - potência total do termo final
Abaixo está a implementação desta fórmula no código:
double Combinations(int k,int n) { int i1=1; int i2=1; for ( int i=n; i<n-k; i-- ) i1*=i; for ( int i=n-k; i>1; i-- ) i2*=i; return double(i1/i2); }
Assim foi transformada a função principal do polinômio final, as mudanças estão relacionadas à parte para o polinômio unidimensional, pois agora não dependemos de 1 parâmetro da barra, mas, sim, de 5. Claro, existem 4 matrizes iniciais, mas na forma simples, os dados de preços não podem ser usados apenas como dados, em vez disso, é necessário transformá-los em alguns valores mais flexíveis, que é a diferença entre os preços vizinhos, e os preços vizinhos podem ser aberturas e fechamentos de barras, qualquer coisa, desde que o valor quantizado final contenha a diferença nos preços de fechamento.
double Val; int iterator; double PolinomTrade()//Polynomial for trading { Val=0; iterator=0; if ( DeepBruteX <= 1 ) { for ( int i=0; i<CNum; i++ ) { Val+=C1[iterator]*(Close[i+1]-Open[i+1])/Point; iterator++; } for ( int i=0; i<CNum; i++ ) { Val+=C1[iterator]*(High[i+1]-Open[i+1])/Point; iterator++; } for ( int i=0; i<CNum; i++ ) { Val+=C1[iterator]*(Open[i+1]-Low[i+1])/Point; iterator++; } for ( int i=0; i<CNum; i++ ) { Val+=C1[iterator]*(High[i+1]-Close[i+1])/Point; iterator++; } for ( int i=0; i<CNum; i++ ) { Val+=C1[iterator]*(Close[i+1]-Low[i+1])/Point; iterator++; } return Val; } else { CalcDeep(C1,CNum,DeepBruteX); return ValStart; } } ///Fractal calculation of numbers double ValW;//the number where everything is multiplied (and then added to ValStart) uint NumC;//the current number for the coefficient double ValStart;//the number where to add everything void Deep(double &Ci0[],int Nums,int deepC,int deepStart,double Val0=1.0)//intermediary fractal { for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(Close[i+1]-Open[i+1])*Val0; Deep(Ci0,Nums,deepC-1,deepStart,ValW); } else { ValStart+=(Ci0[NumC]/Combinations(deepStart,Nums*5))*(Close[i+1]-Open[i+1])*Val0/Point; NumC++; } } for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(High[i+1]-Open[i+1])*Val0; Deep(Ci0,Nums,deepC-1,deepStart,ValW); } else { ValStart+=(Ci0[NumC]/Combinations(deepStart,Nums*5))*(High[i+1]-Open[i+1])*Val0/Point; NumC++; } } for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(Open[i+1]-Low[i+1])*Val0; Deep(Ci0,Nums,deepC-1,deepStart,ValW); } else { ValStart+=(Ci0[NumC]/Combinations(deepStart,Nums*5))*(Open[i+1]-Low[i+1])*Val0/Point; NumC++; } } for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(High[i+1]-Close[i+1])*Val0; Deep(Ci0,Nums,deepC-1,deepStart,ValW); } else { ValStart+=(Ci0[NumC]/Combinations(deepStart,Nums*5))*(High[i+1]-Close[i+1])*Val0/Point; NumC++; } } for ( int i=0; i<Nums; i++ ) { if (deepC > 1) { ValW=(Close[i+1]-Low[i+1])*Val0; Deep(Ci0,Nums,deepC-1,deepStart,ValW); } else { ValStart+=(Ci0[NumC]/Combinations(deepStart,Nums*5))*(Close[i+1]-Low[i+1])*Val0/Point; NumC++; } } } void CalcDeep(double &Ci0[],int Nums,int deepC=1) { NumC=0; ValStart=0.0; for ( int i=0; i<deepC; i++ ) Deep(Ci0,Nums,i+1,i+1); }
A função de cálculo do tamanho da matriz de coeficientes também sofreu uma ligeira alteração. É que o loop é 5 vezes maior agora:
int NumCAll=0;//size of the array of coefficients void DeepN(int Nums,int deepC=1)//intermediate fractal { for ( int i=0; i<Nums*5; i++ ) { if (deepC > 1) DeepN(Nums,deepC-1); else NumCAll++; } } void CalcDeepN(int Nums,int deepC=1) { NumCAll=0; for ( int i=0; i<deepC; i++ ) DeepN(Nums,i+1); }
Todas essas funções são necessárias para implementar o polinômio final, POO é redundante, é melhor usar funções semelhantes para construir uma árvore de chamada, especialmente para fórmulas que não podem ser escritas explicitamente, expansões multidimensionais são um exemplo disso. É bastante difícil entender sua lógica, mas não impossível. Análogos dessas funções também são implementados dentro do programa C#. Infelizmente, os Expert Advisors anexados ao artigo não as terão dentro deste código, haverá uma versão anterior, mas é bastante eficiente, embora um tanto desajeitada. O programa está em fase de protótipo, muito ainda não foi pensado e muitos detalhes foram omitidos, no futuro tudo será mostrado de forma apresentável. Até agora, o programa não é adequado para analisar padrões globais em PCs comuns, mas estou constantemente atualizando-o e em breve sua funcionalidade aumentará bastante. Existem muitas deficiências no meu programa, mas os erros são identificados e eliminados gradualmente. O programa apresenta boa funcionalidade.
Análise dos padrões encontrados
Novamente, como as minhas capacidades computacionais e o meu tempo são limitados, tive que limitar a quantidade de dados, mas acho que será suficiente para tirar algumas conclusões. Em particular, para analisar padrões globais, tivemos que usar apenas gráficos de hora em hora, bem como um tempo limitado para análise. Todos os testes serão realizados no MetaTrader 4. Acontece que os valores esperados dos padrões encontrados estão no nível de spread e no MetaTrader 5, mesmo ao usar a opção Configurações de símbolo de teste personalizado, o testador aplica um spread que não é menor do que o valor que registrado no histórico. O valor é ajustado com base nos dados reais do tick da corretora atual e no spread da área selecionada. Isso é feito para proteger o usuário de resultados de teste muito otimistas. Eu precisei abstrair desses mecanismos, para isso foi escolhido o testador MetaTrader 4.
Vou começar com padrões globais. Seu valor esperado era de apenas 8 pontos. Isso é porque para a fórmula pegamos 50 candles e apenas cerca de 200 000 variantes foram testadas na primeira guia, para cada par de moedas e apenas em 1 núcleo. Se o servidor fosse bom, seria muito mais fácil. Por enquanto é o que há. A próxima versão do programa será menos dependente do poder de computação. Neste tópico, quero focar não tanto no valor esperado em pontos dos resultados, mas em como seu desempenho afeta seu comportamento futuro.
Vamos começar com o par EURUSD H1. Tudo isso foi testado na parcela 2010.01.01-2020.01.01 para ter a chance de encontrar um patrão global:

Os resultados não são tão agradáveis à vista, mas isso é tudo que conseguimos arrancar do par no período definido. Você pode ver o padrão global, embora não seja tão pronunciado, dado o fator de lucro, mas pode ver que há algo funcionando. Para força bruta, peguei 50 candles na fórmula. Na verdade, está longe de ser o melhor resultado que se pode obter, mas é necessário. A razão para isso ficará clara mais tarde. Testamos este o período forward 2020.01.01-2020.11.01 para este trecho, para entender como se comportará no futuro:

Não era o que eu esperava, mas é perfeitamente compreensível. Resulta que essa análise não é suficiente para ganhar algo com a continuação do padrão. Em princípio, se analisarmos os padrões globais parece-me viável, apenas se isso funcionar por pelo menos mais alguns anos, caso contrário, essa análise não faz sentido algum. No início do gráfico, você pode ver que o padrão continua a funcionar, mas após seis meses ele está realmente invertido; basicamente, essa análise pode ser suficiente para negociar durante vários meses, se, é claro, você encontrar parâmetros de teste inicial bons o suficiente. Nesse caso, analisei com base no valor P_Factor. Este valor é semelhante ao Profit Factor, com a única diferença de que assume valores [0...1]. 1 - 100% do lucro. Na primeira guia, o máximo desse indicador era cerca de 0,029. Assim, o valor médio de todas as variantes encontradas foi de cerca de 0,02, o que deu um resultado semelhante.
Seguinte gráfico, EURCHF:

O resultado máximo para as variantes do gráfico na primeira guia deste programa foi em torno de 0,057, seu grau de previsibilidade é 2 vezes maior que o do gráfico anterior, o que também influenciou o Profit Factor final, que na verdade é 0,09 maior que o do o anterior. Vamos ver se a melhora nos indicadores globais afetará o período forward:

Percebe-se que o padrão continua ao longo do ano, pode não ser homogêneo e o fator lucro é menor, mas mesmo assim, podemos tirar conclusões preliminares. Na verdade, o fator de lucro é menor devido ao fato de que houve áreas bastante grandes de um aumento acentuado no saldo no teste global, e eles aumentaram o fator de lucro final. Nos próximos anos, se você testar, tenho certeza que será praticamente igual. A conclusão preliminar é que melhorar a qualidade e a aparência do gráfico afetou seu desempenho no futuro, independentemente do par de moedas, mas é importante que, neste caso, nossas configurações fossem mais aplicáveis a este par de moedas em particular e isso gerasse um resultado. Se olharmos de perto, o motivo das ondas no gráfico pode ser visto no teste global, onde as flutuações de equilíbrio aumentaram muito nos últimos anos e esta é apenas a continuação delas.
Passamos para o gráfico USDJPY:

O gráfico é o mais feio de todos, vamos ver o que acontece no período futuro:

Parece ser uma vantagem, mas a segunda metade é muito semelhante à segunda do primeiro gráfico EURUSD H1, o mesmo movimento para cima no início e, em seguida, uma reversão e um movimento para baixo quase em linha reta. Na verdade, as conclusões são as mesmas do primeiro gráfico. Um resultado final com qualidade insuficiente. Mesmo assim, você pode contar com alguns meses de negociações lucrativas, usando esse padrão, se, é claro, houver um valor esperado e um fator de lucro suficientemente bons.
Gráfico USDCHF mais recente:

Não muito, mas como está, agora vamos dar uma olhada no período forward:

A imagem que vejo é a mesma que em outros gráficos, exceto para EURCHF. A eficiência é mantida até meados do ano, quando ocorre a reversão e inversão do padrão.
As conclusões preliminares podem ser tiradas da seguinte forma:
- Obviamente, EURCHF foi o melhor gráfico
- EURCHF superou todos na seção de treinamento e no teste forward
- Em todos os gráficos, o padrão funciona até o meio do ano, exceto para EURCHF
De tudo isso, podemos concluir que os indicadores de qualidade na área de treinamento afetam diretamente o que vemos no período forward, em particular, um aumento no fator de lucro do resultado final pode indicar que o este último é muito menos aleatório do que nos demais gráficos, podendo indicar a descoberta bem-sucedida de um padrão global. Existe um ditado que diz: "toda brincadeira tem um fundo de verdade." Isso pode ser parafraseado para Forex ou qualquer outro mercado: "todo padrão tem uma parcela de padrão." Quanto mais fortes forem os indicadores de teste, maior será essa parcela.
Agora vou tentar mudar o tamanho da amostra. Vou pegar 1 ano. Intervalo 2017.01.01-2018.01.01 EURJPY H1. Verei como o padrão se comportará para um mês no futuro:

O gráfico não parece muito bom, mas o fator de lucro final e o valor esperado são certamente maiores do que as das variantes de 10 anos. A amostra é 12 vezes menor do que as variantes iniciais, no entanto, esses dados também são dados e não devemos ignorá-los.
Vou pegar um período forward para um mês no futuro, com intervalo 2018.01.01-2018.02.01:

Tomei essa variante como exemplo para deixar mais claros meus raciocínios futuros. Pode-se observar que a inversão do padrão ocorre quase que imediatamente. Infelizmente, não foi possível fornecer mais dados. Os cálculos e a configuração do software levam muito tempo. Mas essa informação deve ser suficiente para uma primeira análise.
Análise de informações
Depois de testar todos os Expert, podemos tirar algumas conclusões:
- A construção de robôs que implementam padrões globais e que têm uma duração de trabalho suficiente é possível usando uma simples pesquisa detalhada de números
- A duração do trabalho no futuro depende diretamente do tamanho da amostra de dados
- A duração do trabalho depende diretamente da qualidade do teste na área de treinamento
- Ao testar o período de avanço em todos os gráficos, a operabilidade para padrões globais permanece pelo menos 2-3 meses
- A probabilidade de encontrar um padrão que funcione por pelo menos mais alguns anos tende a um máximo quando a qualidade do resultado final na seção de força bruta tende a 100%
- Para pesquisar padrões globais, diferentes configurações funcionam de maneira diferente para diferentes pares de moedas
Quanto aos padrões locais, por exemplo, mês-ano, tudo é completamente diferente. No último artigo, analisei padrões locais, mas sem as inovações que esta versão do programa trouxe. Qualquer modernização permite um olhar mais claro sobre as mesmas questões, eliminando informações desnecessárias. Em geral, em relação aos padrões locais:
- Você deve sempre jogar com a substituição do padrão
- Podemos usar martingale, mas com cuidado
Ou seja, quanto maior a amostra, mais ela permanecerá operacional no futuro, e vice-versa, quanto menor a amostra, mais rápido o padrão se inverterá no futuro, é claro que isto acontece desde que não haja otimização direta, que, por falar nisso, acho que vou estragar tudo, mas não no próximo artigo, embora haja mais tarefas prioritárias. Nesse caso, a inversão do padrão no caso de um trecho curto ocorre de maneira garantida. A partir de todos esses pensamentos, seguem as conclusões no que diz respeito de 2 tipos de negociação:
- Uso de padrões globais
- Uso de padrões locais
Deve-se entender que, no primeiro caso, quanto maior a área de treinamento que usamos, mais tempo vai funcionar. Mas, de qualquer forma, precisamos lembrar que é melhor buscar novas fórmulas a cada 2 a 3 meses. No caso de padrões locais, as buscas devem ser realizadas todas as semanas enquanto o mercado estiver congelado. A qualidade dos resultados será baixa, mas você não precisa se preocupar com isso, pois você saberá que poderá extrair pelo menos algum lucro.
Agora tentarei resumir todos os dados obtidos como resultado do meu estudo de padrões usando escalas diferentes. Para isso, em minha opinião, vale a pena introduzir uma função que reflita o valor esperado para o lucro de uma determinada ordem, bem como uma função que reflita o fator lucro, com base no fato de não conhecermos o futuro ou, apenas parcialmente. Se desejarmos, podemos criar funções que caracterizam outros valores menos importantes. O espaço de eventos ou uma variável aleatória - como você quiser - serão todos os possíveis cenários futuros. A este respeito, sabemos apenas:
- Existem incontáveis cenários possíveis para a barra "F" no futuro (foi ou não aberta uma ordem)
- Para todos os possíveis cenários futuros em que numa determinada barra é aberta uma nova ordem, esta última terá um valor esperado em pontos e um fator de lucro (imagine que você está realizando um teste com base numa barra, só que as barras subsequentes são sempre diferentes para cada ordem)
- Para cada fórmula, todas essas quantidades serão diferentes
- Para seções com diferentes datas de início futuras (o início futuro coincide com o final da seção de treinamento) e com seção de treinamento de diferente duração (que é equivalente a diferentes datas de início para a seção de treinamento), os parâmetros finais buscados adotarão valores únicos
Todas essas afirmações podem ser convertidas em fórmulas matemáticas. Em linguagem matemática, fica assim:
- MF=MF(T,I,F,S,R) — valor esperado de ordens numa barra específica no futuro.
- PF=PF(T,I,F,S,R) — fator de lucro de ordens numa barra específica no futuro.
- T — duração da seção de treinamento (neste caso, o tamanho da amostra ou o número de barras é o mesmo)
- I — data de término da seção de treinamento
- F — número da barra no futuro, a contar desde a data de término do treinamento
- S — polinômio ou algoritmo único (se o padrão for encontrado manualmente ou programando um novo robô)
- R — resultados alcançados usando um determinado polinômio ou estratégia (em outras palavras, o desempenho ao otimizar seu sinal), eles incluem o número de transações na área de treinamento e indicadores como o valor esperado, fator de lucro e outros parâmetros.
Com base nos dados obtidos durante a força bruta em diferentes instrumentos e datas, posso desenhar como as funções que inseri acima no gráfico ficarão se usarmos "F" como argumento:

Este gráfico mostra 2 variantes exclusivas de estratégias que foram treinadas em locais diferentes usando configurações diferentes e que alcançaram resultados diferentes. É muito importante compreender que existem inúmeras variantes, mas todas diferem na duração e na qualidade do padrão inicial. Também é muito importante entender que depois sempre ocorre uma inversão do padrão. Essa regra pode não funcionar apenas para padrões muito fortes, e mesmo para eles há sempre o risco de que o gráfico se reverta, mesmo depois de 5 anos. Aqui, as mais resistentes serão aquelas fórmulas que foram encontradas a partir da amostra de maior tamanho. Se elas foram encontrados manualmente e essas fórmulas estavam inicialmente sujeitas a alguma teoria, então essas fórmulas no futuro podem funcionar indefinidamente. No caso de usarmos força bruta ou outros métodos de aprendizado de máquina, não teremos garantias. Tudo o que temos é uma avaliação da integridade, que só pode ser feita com base em dados estatísticos. Essa análise é possível com a ajuda do meu programa, mas não está disponível para uma pessoa, até porque o tempo e o poder de computação são limitados.
O que vem agora?
A análise de padrões globais mostrou que o poder de um computador comum não é suficiente para análises profundas e de alta qualidade com grandes amostras de, digamos, 10 anos ou mais. Porém, para uma pesquisa de alta qualidade, precisamos tomar amostras grandes. Talvez se rodarmos o programa durante alguns meses no servidor, encontraremos uma ou 2 variantes boas, sendo que essa não é uma tarefa para um computador fixo, com certeza. Portanto, é necessário aumentar a eficiência e, ao mesmo tempo, aumentar a velocidade a nível de pesquisa detalhada de variantes. Eu vejo o desenvolvimento futuro do programa da seguinte forma:
- Adicionando recursos para analisar janelas de tempo fixas de servidor
- Adicionando recursos de análise em dias fixos da semana
- Adicionando recursos para gerar janelas de tempo aleatoriamente
- Adicionando recursos para gerar aleatoriamente uma matriz de dias da semana permitidos para negociação
- Aprimorando a segunda etapa de análise (guia otimização), em particular, a implementação de cálculos multicore e correção de erros do otimizador.
As mudanças listadas, de acordo com a ideia, devem aumentar muito a velocidade do programa, a variabilidade e qualidade das variantes encontradas e, por fim, garantir a disponibilidade de ferramentas mais ou menos normais para análise de mercado.
Fim do artigo
Espero que este artigo tenha sido útil para o leitor. Parece-me muito importante abordar os padrões globais do artigo, foi extremamente difícil fazê-lo, visto que a potência do programa ainda não é suficiente para este tipo de análise. Se eu tivesse um bom servidor de 30 núcleos, não seria difícil. Por uma boa causa, era necessário gastar várias vezes mais tempo nessa análise, talvez o dobro do tempo.
Espero que seja possível aumentar o poder de computação no futuro. O próximo artigo será mais interessante. Na verdade, houve um pouco de matemática para podermos compreender tudo em termos gerais, uma vez que sem isso seria impossível realizar uma análise efetiva mesmo com o uso de software útil, já para não falar da pesquisa detalhada manual, ou otimização.
Basicamente, o artigo pretendia fornecer informações para aqueles que ainda não conseguiram atingir nem mesmo resultados extremamente modestos manualmente, bem como permitir que as pessoas pudessem pelo menos entender que considerações valem a pena para escrever robôs e prever o tempo gasto.
Finalmente, quero dizer que me parece que a maneira como o padrão é encontrado não é tão importante, se manualmente ou com automação. Se um padrão tem certos indicadores de lucratividade, podemos considerá-lo plenamente funcional. De qualquer forma, certos parâmetros do padrão nos darão algumas previsões, pelo menos por um tempo mínimo no futuro, e é o suficiente para ganhar dinheiro em dado momento. Além disso, não pense que se você encontrar algum tipo de padrão tão funcional como você imagina, ele continuará a funcionar depois. Para afirmar isso, você precisa de uma amostra muito grande com um desempenho a nível de negociação muito bom para toda a amostra, bem como de um número suficiente de ordens em relação ao tamanho desta. Uma coisa é encontrar um padrão e outra é avaliar o tempo estimado de viabilidade futura. Essa questão é fundamental, na minha opinião. Qual é o sentido por trás de procurar um padrão se não compreendermos por quanto tempo e quão bem ele funcionará. Também decidi compartilhar meu programa com todos, ele estará no arquivo. Você pode fazer perguntas sobre a configuração por mensagem privada.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/8660
 Algoritmo de aprendizado de máquina CatBoost da Yandex sem conhecimento prévio de Python ou R
Algoritmo de aprendizado de máquina CatBoost da Yandex sem conhecimento prévio de Python ou R
 Reamostragem avançada e seleção de modelos CatBoost pelo método de força bruta
Reamostragem avançada e seleção de modelos CatBoost pelo método de força bruta
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso