
MQL 언어를 사용하여 아무것도 없는 상태에서 심층 신경망(Deep Neural Network) 프로그래밍 하기

소개
최근 머신 러닝이 대중화되면서 많은 사람들이 딥 러닝에 대해 들어보고 이를 MQL 언어에 적용하는 방법을 알고 싶어합니다. 활성화 함수를 통해 간단한 인공 뉴런을 구현한 것은 보았지만 실제 심층 신경망을 구현한 것은 없었습니다. 저는 이 기사를 통해 은닉층 용의 쌍곡탄젠트 함수와 출력층 용의 Softmax 함수와 같은 다양한 활성화 함수를 사용하여 MQL 언어로 구현한 심층 신경망을 소개하고자 합니다. 심층 신경망을 완벽하게 구현하기 위해 첫 번째 단계부터 마지막 단계까지 살펴볼 것입니다.
1. 인공 뉴런 만들기
시작은 신경망의 기본 단위부터 시작합니다: 단일 뉴런 이 기사에서는 심층 신경망에서 사용할 뉴런의 유형간의 여러 다른 부분들에 대해 집중하여 설명할 것입니다. 그러나 뉴런 유형 간의 가장 큰 차이점은 일반적으로 활성화 함수입니다.
1.1. 단일 뉴런 부분
인간 두뇌의 뉴런에서 느슨하게 모델링 된 인공 뉴런은 단순히 수학적 계산을 호스팅합니다. 인간의 뉴런과 마찬가지로 인공 뉴런은 충분한 자극을 받을 때 작동합니다. 뉴런은 데이터의 입력을 결합하는 역할을 하는데 해당 입력을 증폭하거나 감쇠하는 계수 또는 가중치 세트를 적용하여 알고리즘이 학습하려는 작업과 관련된 입력에 대한 중요성을 할당합니다. 다음 이미지에서 작동하는 뉴런의 각 부분을 확인해 보세요:

1.1.1. 입력
입력(Inputs)은 주위 환경으로부터의 외부 트리거이거나 다른 인공 뉴런의 출력(outputs)에서 비롯됩니다; 이는 네트워크에 의해 평가될 것입니다. 입력은 뉴런의 "음식" 역할을 하고 입력을 통과하여 우리가 뉴런에게 한 훈련을 통해 우리가 해석할 수 있는 출력이 됩니다. 이들은 이산 값 또는 실수 값일 수 있습니다.
1.1.2. 가중치
가중치는 그에 해당하는 항목을 곱하여 값을 늘리거나 줄이며, 뉴런 내부로 들어가는 입력과 그에 따라 나오는 출력에 더 크거나 더 작은 의미를 부여하는 요소입니다. 신경망 훈련 알고리즘의 목표는 해결할 문제에 대한 "최상의" 가능한 최고의 가중치 값의 세트를 정하는 것입니다.
1.1.3. 순 입력 함수(Net Input Function)
이 뉴런에서 입력과 가중치는 각 항목에 가중치를 곱한 값의 합으로 단일 결과 제품으로 수렴됩니다. 이 결과 또는 값은 활성화 함수를 통해 전달되며 이를 통해 입력 뉴런이 신경망 출력에 미치는 영향을 측정할 수 있습니다.
1.1.4. 활성화 함수(Activation Function)
활성화 함수는 출력으로 이어집니다. 활성화 함수에는 여러 유형이 있을 수 있습니다(Sigmoid, Tan-h, Softmax, ReLU 등). 활성화 함수는 뉴런이 활성화되어질지 여부를 결정합니다. 이 기사에서는 Tan-h 및 Softmax 유형의 함수를 살펴봅니다.
1.1.5. 출력
마침내 출력을 얻었습니다. 출력은 다른 뉴런으로 전달되거나 외부 환경에 의해 샘플링될 수 있습니다. 값은 사용된 활성화 함수에 따라 이산 또는 실수일 수 있습니다.
2. 신경망 구축
신경망은 뇌와 같은 생물학적 신경계의 정보 처리 방법으로부터 영감을 받은 것입니다. 이는 인공 뉴런의 층으로 구성되며 각각의 층은 다음의 층에 연결됩니다. 따라서 이전 계층은 다음 계층에 대한 입력 역할을 하고 이렇게 출력 계층까지 계속 작동합니다. 신경망의 목적은 자율 학습을 통한 클러스터링, 비 자율 학습 또는 회귀를 통한 분류일 수 있습니다. 이 기사에서는 BUY, SELL 또는 HOLD의 세 가지 상태로 분류하는 기능에 중점을 둘 것입니다. 다음은 하나의 은닉층이 있는 신경망입니다:

3. 신경망에서 심층 신경망으로의 확장
심층 신경망을 일반적인 단일의 숨겨진 계층 신경망과 구별하게 하는 것은 심층 신경망의 깊이를 구성하는 계층의 수입니다. 3개 이상의 레이어(입력 및 출력 포함)는 "딥" 러닝에 해당합니다. 따라서 "딥"은 엄격하게 정의된 기술 용어로서 하나 이상의 숨겨진 레이어가 있다는 의미입니다. 신경망으로 더 깊이 들어갈수록 뉴런이 인식할 수 있는 더 복잡한 기능이 있습니다. 왜냐하면 뉴런은 이전 레이어의 기능을 집계하고 재결합하기 때문입니다. 이를 통해 딥 러닝 네트워크는 비선형 함수를 통과하는 수십억 개의 매개변수가 있는 매우 큰 고차원의 데이터 세트를 처리할 수 있게 됩니다. 아래 이미지에서 3개의 숨겨진 레이어가 있는 심층 신경망을 찾아보세요:

3.1. 심층 신경망 클래스
이제 신경망을 만드는 데 사용할 클래스를 살펴보겠습니다. 심층 신경망은 DeepNeuralNetwork라는 프로그램 정의 클래스에 캡슐화 되어 있습니다. 주 메서드는 3-4-5-3 완전히 연결된 피드포워드 신경망을 인스턴스화합니다. 뒤에서 네트워크에 공급할 항목의 몇 가지 예를 이 기사의 심층 신경망 교육 세션에서 보여주겠지만 지금은 네트워크의 생성에 중점을 둘 것입니다. 네트워크는 2개의 은닉층을 위해 하드코딩 됩니다. 3개 이상의 층이 있는 신경망은 매우 드물지만 더 많은 층이 있는 네트워크를 만들고 싶다면 이 기사에서 설명한 구조를 사용하여 쉽게 만들 수 있습니다. 입력-계층-A 가중치는 행렬 iaWeights에 저장되고 계층-A-계층-B 가중치는 행렬 abWeights에 저장되며 계층-B-출력 가중치는 행렬 boWeights에 저장됩니다. 다차원 배열은 첫 번째 차원에서만 정적이거나 동적일 수 있기 때문에(모든 추가 차원은 정적임) 행렬의 크기는 "#define" 문을 사용하여 상수 변수로 선언됩니다. 공간을 절약하기 위해 최상위 시스템 네임스페이스를 참조하는 선언문을 제외한 모든 using 문을 제거했습니다. 기사의 첨부 파일에서 전체 소스 코드를 찾을 수 있습니다.
프로그램 구조:
#define SIZEI 4 #define SIZEA 5 #define SIZEB 3 //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class DeepNeuralNetwork { private: int numInput; int numHiddenA; int numHiddenB; int numOutput; double inputs[]; double iaWeights[][SIZEI]; double abWeights[][SIZEA]; double boWeights[][SIZEB]; double aBiases[]; double bBiases[]; double oBiases[]; double aOutputs[]; double bOutputs[]; double outputs[]; public: DeepNeuralNetwork(int _numInput,int _numHiddenA,int _numHiddenB,int _numOutput) {...} void SetWeights(double &weights[]) {...} void ComputeOutputs(double &xValues[],double &yValues[]) {...} double HyperTanFunction(double x) {...} void Softmax(double &oSums[],double &_softOut[]) {...} }; //+------------------------------------------------------------------+
두 개의 은닉 레이어와 단일 출력 레이어에는 각각 aBiases, bBiases 및 oBiases라는 관련 바이어스 값의 배열이 있습니다. 숨겨진 레이어의 로컬 출력은 aOutputs 및 bOutputs라는 클래스 범위 배열에 저장됩니다.
3.2. 심층 신경망 출력 계산
ComputeOutputs 메서드는 예비(활성화 전)의 합계를 보유하도록 스크래치 배열을 설정하는 것으로 시작합니다. 이어서 레이어 A 노드에 대한 입력에 가중치를 곱한 예비 합계를 계산하고 편향 값을 추가한 다음 활성화 함수를 적용합니다. 그런 다음 방금 계산된 레이어 A의 출력을 로컬 입력으로 사용하여 레이어 B의 로컬 출력을 계산하고 마지막으로 최종 출력을 계산합니다.
void ComputeOutputs(double &xValues[],double &yValues[]) { double aSums[]; // hidden A nodes sums scratch array double bSums[]; // hidden B nodes sums scratch array double oSums[]; // output nodes sums ArrayResize(aSums,numHiddenA); ArrayFill(aSums,0,numHiddenA,0); ArrayResize(bSums,numHiddenB); ArrayFill(bSums,0,numHiddenB,0); ArrayResize(oSums,numOutput); ArrayFill(oSums,0,numOutput,0); int size=ArraySize(xValues); for(int i=0; i<size;++i) // copy x-values to inputs this.inputs[i]=xValues[i]; for(int j=0; j<numHiddenA;++j) // compute sum of (ia) weights * inputs for(int i=0; i<numInput;++i) aSums[j]+=this.inputs[i]*this.iaWeights[i][j]; // note += for(int i=0; i<numHiddenA;++i) // add biases to a sums aSums[i]+=this.aBiases[i]; for(int i=0; i<numHiddenA;++i) // apply activation this.aOutputs[i]=HyperTanFunction(aSums[i]); // hard-coded for(int j=0; j<numHiddenB;++j) // compute sum of (ab) weights * a outputs = local inputs for(int i=0; i<numHiddenA;++i) bSums[j]+=aOutputs[i]*this.abWeights[i][j]; // note += for(int i=0; i<numHiddenB;++i) // add biases to b sums bSums[i]+=this.bBiases[i]; for(int i=0; i<numHiddenB;++i) // apply activation this.bOutputs[i]=HyperTanFunction(bSums[i]); // hard-coded for(int j=0; j<numOutput;++j) // compute sum of (bo) weights * b outputs = local inputs for(int i=0; i<numHiddenB;++i) oSums[j]+=bOutputs[i]*boWeights[i][j]; for(int i=0; i<numOutput;++i) // add biases to input-to-hidden sums oSums[i]+=oBiases[i]; double softOut[]; Softmax(oSums,softOut); // softmax activation does all outputs at once for efficiency ArrayCopy(outputs,softOut); ArrayCopy(yValues,this.outputs); }배후에서 신경망은 두 개의 은닉층의 출력을 계산할 때 쌍곡선 탄젠트 활성화 함수(Tan-h)를 사용하고 최종 출력 값을 계산할 때 Softmax 활성화 함수를 사용합니다.
- 쌍곡선 탄젠트(Tan-h): 로지스틱 시그모이드와 마찬가지로 Tan-h 함수도 시그모이드이지만 대신 (-1, 1) 범위의 값을 출력합니다. 따라서 Tan-h에 대한 강한 음의 입력은 음의 출력에 매핑 됩니다. 또한 값이 0인 입력만 0에 가까운 출력에 매핑 됩니다. 이 경우 수학 공식과 이를 MQL 소스 코드로 구현한 것을 보여드리겠습니다.
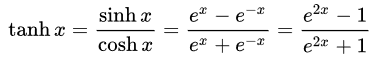
double HyperTanFunction(double x) { if(x<-20.0) return -1.0; // approximation is correct to 30 decimals else if(x > 20.0) return 1.0; else return MathTanh(x); //Use explicit formula for MQL4 (1-exp(-2*x))/(1+exp(-2*x)) }
- Softmax: 여러 클래스의 경우 각 클래스에 소수 확률을 할당합니다. 이러한 소수 확률은 1.0을 더해야 합니다. 이 추가적인 제한을 통해 훈련이 더 빨리 수렴됩니다.

void Softmax(double &oSums[],double &_softOut[]) { // determine max output sum // does all output nodes at once so scale doesn't have to be re-computed each time int size=ArraySize(oSums); double max= oSums[0]; for(int i = 0; i<size;++i) if(oSums[i]>max) max=oSums[i]; // determine scaling factor -- sum of exp(each val - max) double scale=0.0; for(int i= 0; i<size;++i) scale+= MathExp(oSums[i]-max); ArrayResize(_softOut,size); for(int i=0; i<size;++i) _softOut[i]=MathExp(oSums[i]-max)/scale; }
4. DeepNeuralNetwork 클래스를 사용하는 데모 Expert Advisor
Expert Advisor를 개발하기 전에 Deep Neural Network에 제공할 데이터를 정의해야 합니다. 신경망은 패턴 분류에 능숙하므로 일본 캔들의 상대 값을 입력으로 사용할 것입니다. 이 값들은 캔들의 위쪽 그림자, 몸체, 아래쪽 그림자의 크기와 방향(강세 또는 약세)입니다. 항목 수가 반드시 적을 필요는 없지만 이들 항목들은 테스트 프로그램용으로 충분합니다.
데모 Expert Advisor:
4-4-5-3 구조의 신경망에는 총 (4 * 4) + 4 + (4 * 5) + 5 + (5 * 3) + 3 = 63개의 가중치와 편향 값이 필요합니다.
#include <DeepNeuralNetwork.mqh> int numInput=4; int numHiddenA = 4; int numHiddenB = 5; int numOutput=3; DeepNeuralNetwork dnn(numInput,numHiddenA,numHiddenB,numOutput); //--- weight & bias values input double w0=1.0; input double w1=1.0; input double w2=1.0; input double w3=1.0; input double w4=1.0; input double w5=1.0; input double w6=1.0; input double w7=1.0; input double w8=1.0; input double w9=1.0; input double w10=1.0; input double w11=1.0; input double w12=1.0; input double w13=1.0; input double w14=1.0; input double w15=1.0; input double b0=1.0; input double b1=1.0; input double b2=1.0; input double b3=1.0; input double w40=1.0; input double w41=1.0; input double w42=1.0; input double w43=1.0; input double w44=1.0; input double w45=1.0; input double w46=1.0; input double w47=1.0; input double w48=1.0; input double w49=1.0; input double w50=1.0; input double w51=1.0; input double w52=1.0; input double w53=1.0; input double w54=1.0; input double w55=1.0; input double w56=1.0; input double w57=1.0; input double w58=1.0; input double w59=1.0; input double b4=1.0; input double b5=1.0; input double b6=1.0; input double b7=1.0; input double b8=1.0; input double w60=1.0; input double w61=1.0; input double w62=1.0; input double w63=1.0; input double w64=1.0; input double w65=1.0; input double w66=1.0; input double w67=1.0; input double w68=1.0; input double w69=1.0; input double w70=1.0; input double w71=1.0; input double w72=1.0; input double w73=1.0; input double w74=1.0; input double b9=1.0; input double b10=1.0; input double b11=1.0;
신경망과 관련한 입력의 경우 다음의 공식을 사용해서 전체 크기를 고려하여 캔들의 각 부분을 나타내는 백분율을 결정합니다.

//+------------------------------------------------------------------+ //|percentage of each part of the candle respecting total size | //+------------------------------------------------------------------+ int CandlePatterns(double high,double low,double open,double close,double uod,double &xInputs[]) { double p100=high-low;//Total candle size double highPer=0; double lowPer=0; double bodyPer=0; double trend=0; if(uod>0) { highPer=high-close; lowPer=open-low; bodyPer=close-open; trend=1; } else { highPer=high-open; lowPer=close-low; bodyPer=open-close; trend=0; } if(p100==0)return(-1); xInputs[0]=highPer/p100; xInputs[1]=lowPer/p100; xInputs[2]=bodyPer/p100; xInputs[3]=trend; return(1); }
이제 신경망을 통해 입력을 처리할 수 있습니다.
MqlRates rates[]; ArraySetAsSeries(rates,true); int copied=CopyRates(_Symbol,0,1,5,rates); //Compute the percent of the upper shadow, lower shadow and body in base of sum 100% int error=CandlePatterns(rates[0].high,rates[0].low,rates[0].open,rates[0].close,rates[0].close-rates[0].open,_xValues); if(error<0)return; dnn.SetWeights(weight); double yValues[]; dnn.ComputeOutputs(_xValues,yValues);
이제 거래 기회는 신경망 계산을 기반으로 처리됩니다. 소프트맥스 기능은 100%의 합을 기준으로 3개의 출력을 생성한다는 것을 잊지 마십시오. 값은 "yValues" 배열에 저장되며 60%보다 큰 값이 실행됩니다.
//--- if the output value of the neuron is mare than 60% if(yValues[0]>0.6) { if(m_Position.Select(my_symbol))//check if there is an open position { if(m_Position.PositionType()==POSITION_TYPE_SELL) m_Trade.PositionClose(my_symbol);//Close the opposite position if exists if(m_Position.PositionType()==POSITION_TYPE_BUY) return; } m_Trade.Buy(lot_size,my_symbol);//open a Long position } //--- if the output value of the neuron is mare than 60% if(yValues[1]>0.6) { if(m_Position.Select(my_symbol))//check if there is an open position { if(m_Position.PositionType()==POSITION_TYPE_BUY) m_Trade.PositionClose(my_symbol);//Close the opposite position if exists if(m_Position.PositionType()==POSITION_TYPE_SELL) return; } m_Trade.Sell(lot_size,my_symbol);//open a Short position } if(yValues[2]>0.6) { m_Trade.PositionClose(my_symbol);//close any position }
5. 전략 최적화를 사용한 심층 신경망 훈련
눈치채셨겠지만 심층 신경망 피드포워드 메커니즘만 구현되었으며 어떠한 훈련도 수행하지 않습니다. 이 작업은 전략 테스터에서 사용하기 위해 만들어 둔 것입니다. 아래에서는 신경망을 훈련하는 방법을 보여드리겠습니다. 많은 수의 입력과 훈련 매개변수의 범위로 인해 MetaTrader 5에서만 훈련할 수 있지만 최적화 값을 얻은 후에는 MetaTrader 4로 쉽게 복사할 수 있습니다.
전략 테스터 구성:
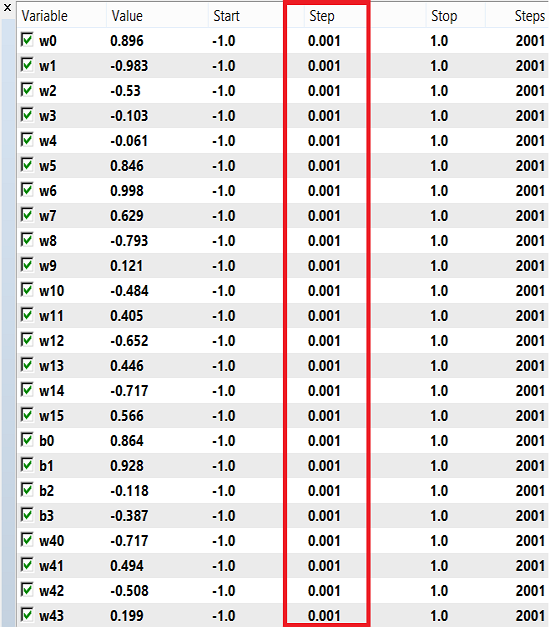
가중치와 편향은 훈련을 위해 -1에서 1까지의 숫자 범위와 0.1, 0.01 또는 0.001의 단계를 사용할 수 있습니다. 이 값을 시도해보고 어떤 값이 최상의 결과를 얻는지 확인할 수 있을 것입니다. 제 경우에는 아래 이미지와 같이 0.001의 간격을 사용했습니다.
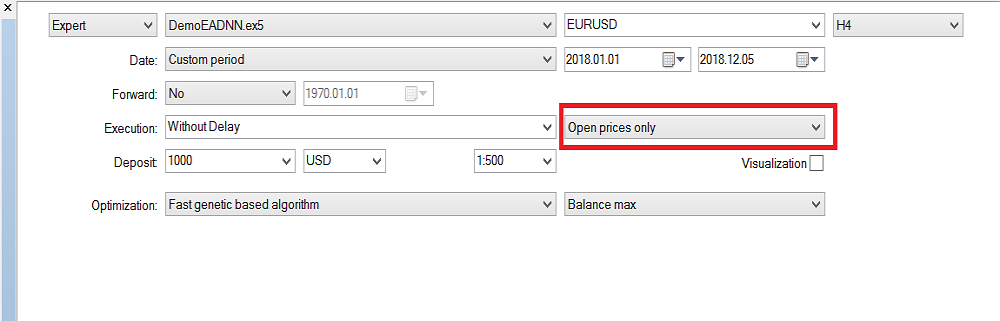
저는 최근에 완성된 캔들을 사용했기 때문에 "시가만 사용"을 선택했습니다. 그러므로 매 틱마다 실행할 필요는 없습니다. 이제 H4 시간 프레임에서 최적화를 실행했으며 작년에 백테스트에서 다음과 같은 결과를 얻었습니다.

결론
이 기사에서 제시한 코드와 설명은 두 개의 은닉층이 있는 신경망을 이해하는 데 좋은 기초를 제공할 것입니다. 3개 이상의 은닉층의 경우는? 관련 연구 문헌에서 내린 결론에 따르면 두 개의 은닉층이 거의 모든 실제의 문제를 다루는데 충분하다는 것입니다. 이 기사에서는 심층 신경망이 원시 데이터에서 추상적인 기능을 학습할 수 있는 능력을 바탕으로 심층 신경망을 사용하여 환율 예측을 위한 모델을 개발하는데 쓰이는 접근 방식을 간략하게 설명합니다. 잠정적인 결과는 우리의 심층 네트워크가 선진 통화 시장에 대한 기준 모델보다 훨씬 더 높은 예측 정확도를 생성한다는 것입니다.
MetaQuotes 소프트웨어 사를 통해 영어가 번역됨
원본 기고글: https://www.mql5.com/en/articles/5486
 알고리즘에 기반한 트레이딩 시스템을 설계하는 이유와 방법
알고리즘에 기반한 트레이딩 시스템을 설계하는 이유와 방법
 더 나은 프로그래머 (Part 07): 성공적인 프리랜서 개발자가 되기 위한 참고 사항
더 나은 프로그래머 (Part 07): 성공적인 프리랜서 개발자가 되기 위한 참고 사항
 Expert Advisor 처음부터 개발하기
Expert Advisor 처음부터 개발하기
 더 나은 프로그래머 (Part 06): 효율적인 코딩으로 이끄는 9가지 습관
더 나은 프로그래머 (Part 06): 효율적인 코딩으로 이끄는 9가지 습관
나는 꽤 오랫동안 그것에 대해 작업하고 있었다.
나는 전문가가 아니기 때문에 내 코드에 무엇이 문제인지 모르겠습니다. 커뮤니티 칼리지에서 공부하는 IT 학생일 뿐입니다.
EA를 개체 레이블을 만드는 사용자 지정 표시기로 만들고 싶습니다.
(구매[+1], 판매[-1],무시[0] 또한 요금[0].high를 rate[1].high로 변경)하지만 일부 문서를 아무리 읽어도 최종 출력이 표시되지 않습니다.
다음 함수를 업데이트하여 `void` 대신 `bool`을 반환하면 잘못된 가중치가 주어졌음을 알 수 있습니다.
파일 상단의 가중치도 업데이트해야 합니다(네트워크를 초기화할 때만 업데이트하는 것으로는 충분하지 않습니다.P
하드 코딩된 NN입니다. 나중에 훈련할 수 없으므로 뉴런 수를 늘리는 것은 권장하지 않습니다...
공유해주신 코드 감사합니다. 새로운 코더로서 몇 가지 질문이 있습니다. 경험이 있는 분들의 도움을 받을 수 있기를 바랍니다. 미리 감사드립니다.
1. " DeepNeuralNetwork.mqh" 파일을 컴파일할 때 왜 이런 일이 발생하는지 이해할 수 없습니다. 아래 스크린샷을 참조하십시오.
2. DemoEADNN.mq5에서 이 두 파일은 어디에 있습니까? 아래 스크린샷을 참조하세요.
감사해요.
1. "DeepNeuralNetwork.mqh" 파일을 컴파일할 때 몇 가지 오류가 있어 수정할 수 없습니다.
2. DemoEADNN.mq5에서 이 두 파일을 찾을 수 없습니다. 아래 스크린샷을 참조하십시오.
감사해요.
매우 유용한 기사
정말 감사합니다