
거래 시스템의 평가 - 일반적 진입, 퇴출 및 거래의 효율성

소개
거래 시스템의 효율성을 결정하는 많은 조치가 있습니다. 그리고 트레이더는 그들이 좋아하는 것을 선택합니다. 이 문서에서는 S.V.의 "Statistika dlya traderov"("Statistics for traders") 책에 설명된 접근 방식에 대해 설명합니다. 불라쇼프 (Bulashev). 불행히도 이 책의 부수가 너무 적어 오랫동안 재발행되지 못했습니다. 그러나 전자 버전은 여전히 많은 웹 사이트에서 열람가능합니다.
프롤로그
2003년에 출간된 책으로 기억합니다. 그리고 그 당시는 MQL-II 프로그래밍 언어를 사용하는 MetaTrader 3의 시대였습니다. 그리고 그 당시 플랫폼은 다소 진보적이었습니다. 따라서 현대의 MetaTrader 5 클라이언트 터미널과 비교하여 거래 조건 자체의 변화를 추적할 수 있습니다. 이 책의 저자는 여러 세대에 걸쳐 트레이더의 구루가 되었습니다(이 지역의 빠른 세대 변화를 고려해봤을 때). 그러나 시간은 멈추지 않습니다. 이 책에 설명된 원칙이 여전히 적용 가능함에도 불구하고 접근 방식을 조정해야 합니다.
S.V. Bulashev는 우선 그 당시의 실제 거래 상황에 기초하여 그의 책을 썼습니다. 그렇기 때문에 저자가 설명한 통계를 변환 없이 사용할 수 없습니다. 더 명확하게 하기 위해 당시의 거래 가능성을 기억해봅시다. 현물 시장에서의 한계 거래는 투기적 이익을 얻기 위해 통화를 사는 것은 잠시 후 매도하는 것을 의미합니다.
이것이 기본이며 "트레이더를 위한 통계" 책이 작성될 때 정확한 해석이 사용되었음을 상기해볼 필요가 있습니다. 1랏의 각 거래는 동일한 볼륨의 역 거래로 마감되어야 합니다. 그러나 2년 후(2005년), 이러한 통계의 사용은 개편이 필요했습니다. 그 이유는 MetaTrader 4에서 부분적인 거래 성사가 가능해지기 때문입니다. 따라서 Bulashev가 설명한 통계를 사용하려면 해석 시스템을 개선해야 합니다. 특히 해석은 열지 않고 닫는 방식으로 이루어져야 합니다.
5년 후 상황은 크게 바뀌었습니다. 그렇게 습관적인 용어 Order는 어디에 있습니까? 이미 떠난지 오랩니다. 이 포럼에서 질문의 흐름을 고려할 때 MetaTrader 5의 정확한 해석 시스템을 설명하는 것이 좋습니다.
따라서 오늘날에는 더 이상 고전적인 용어인 주문이 없습니다. 이제 주문은 거래 포지션을 열거나 변경하기 위해 trader 또는 MTS가 만드는 중개인 서버에 대한 거래 요청입니다. 이제 포지션입니다. 그 의미를 이해하기 위해 저는 한계 거래를 언급했습니다. 사실 한계 거래는 빌린 돈으로 수행됩니다. 그리고 그 돈이 존재할 때까지 지위가 존재합니다.
포지션을 폐쇄하여 차용인과 계정을 정산하고 결과적으로 손익을 고정하는 즉시 포지션은 존재하지 않습니다. 그건 그렇고, 이 사실은 왜 반대 포지션이 닫히지 않는지를 설명합니다. 사실은 빌린 돈이 그대로 남아 있고, 돈을 빌린 사람이 돈을 사든 팔든 차이가 없다는 것입니다. 거래는 실행된 주문의 기록일 뿐입니다.
이제 거래의 기능에 대해 이야기합시다. 현재 MetaTrader 5에서는 거래 포지션을 부분적으로 청산하거나 기존 포지션을 늘릴 수 있습니다. 따라서 특정 볼륨의 포지션이 열릴 때마다 같은 볼륨으로 닫히는 고전적인 해석 시스템은 과거로 사라졌습니다. 그런데 MetaTrader 5에 저장된 정보에서 복구가 정말 불가능한가요? 그래서 우선 해석을 재구성할 것입니다.
진입의 효율성
많은 사람들이 자신의 거래를 더 효과적으로 만들고 싶어하는 것은 비밀이 아니지만 이 용어를 어떻게 설명(정형화)해야 할까요? 거래가 가격에 의해 전달되는 경로라고 가정하면 해당 경로에 두 개의 극단점이 있음이 분명해집니다. 즉, 관찰된 섹션 내 가격의 최소값과 최대값입니다. 모든 사람은 가능한 한 최소값에 가깝게 시장에 진입하기 위해 노력합니다(구매 시). 이것은 모든 거래의 주요 규칙으로 간주될 수 있습니다. 낮은 가격에 구매하고 높은 가격에 판매합니다.
입력의 효율성은 구매 최소값에 얼마나 가까운지를 결정합니다. 즉, 진입의 실효성은 전체 경로에 진입하는 최대값과 가격 사이의 거리의 비율입니다. 최대값의 차이를 통해 최소값까지의 거리를 측정하는 이유는 무엇인가요? 최소 입력 시 효과가 1과 같아야 하고 최대 입력 시 0과 같아야 합니다.
이것이 우리 비율에 대해 최소값과 입구 자체 사이의 거리가 아닌 나머지 거리를 취하는 이유입니다. 여기서 우리는 판매 상황이 구매 상황과 비교하여 반영된다는 점을 지적해야 합니다.
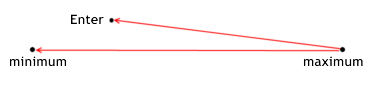
포지션 진입의 효율성은 MTS가 특정 거래 중 진입 가격에 비해 잠재적 이익을 얼마나 잘 실현하는지 보여줍니다. 다음 공식으로 계산됩니다.
for long positions enter_efficiency=(max_price_trade-enter_price)/(max_price_trade-min_price_trade); for short positions enter_efficiency=(enter_price-min_price_trade)/(max_price_trade-min_price_trade); The effectiveness of entering can have a value within the range from 0 to 1.
이탈의 효과
종료 상황은 다음과 유사합니다.
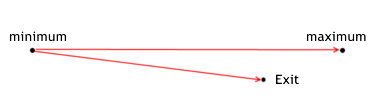
포지션 엑시트의 효율성은 MTS가 특정 거래 동안 포지션 엑시트 가격에 비해 잠재적인 이익을 얼마나 잘 실현하는지 보여줍니다. 다음 공식으로 계산됩니다.
for lone positions exit_efficiency=(exit_price - min_price_trade)/(max_price_trade - min_price_trade); for short positions exit_efficiency=(max_price_trade - exit_price)/(max_price_trade - min_price_trade); The effectiveness of exiting can have a value withing the range from 0 to 1.
거래의 효율성
전반적으로 거래의 효율성은 진입과 퇴출 모두에 의해 결정됩니다. 거래 중 최대 거리(즉, 최소값과 최대값의 차이)에 대한 진입 및 퇴장 경로의 비율로 계산할 수 있습니다. 따라서 거래의 효율성은 거래에 대한 기본 정보를 직접 사용하거나 이전에 평가된 입구 및 출구의 이미 계산된 결과(간격 이동 포함)를 사용하여 두 가지 방법으로 계산할 수 있습니다.
거래의 효율성은 MTS가 특정 거래 동안 총 잠재적 이익을 얼마나 잘 실현하는지 보여줍니다. 다음 공식으로 계산됩니다.
for long positions trade_efficiency=(exit_price-enter_price)/(max_price_trade-min_price_trade); for short positions trade_efficiency=(enter_price-exit_price)/(max_price_trade-min_price_trade); general formula trade_efficiency=enter_efficiency+exit_efficiency-1; The effectiveness of trade can have a value within the range from -1 to 1. The effectiveness of trade must be greater than 0,2. The analysis of effectiveness visually shows the direction for enhancing the system, because it allows evaluating the quality of signals for entering and exiting a position separately from each other.
해석의 변형
먼저, 혼동을 피하기 위해 해석 대상의 명칭을 명확히 해야 합니다. 주문, 거래, 포지션라는 동일한 용어가 MetaTrader 5와 Bulachev에서 사용되므로 분리해야 합니다. 내 글에서 저는 Bulachev의 해석 대상에 대해 "trade"라는 이름을 사용할 것입니다. 즉, trade는 거래입니다. 그는 또한 "주문"이라는 용어를 사용하는데, 그 맥락에서 이 용어들은 동일합니다. Bulachev는 미완성 거래를 포지션이라고 부르고 우리는 그것을 미완성 거래라고 부를 것입니다.
여기서 3가지 용어가 모두 "trade"라는 단어에 쉽게 들어맞는 것을 볼 수 있습니다. 그리고 우리는 MetaTrader 5에서 해석의 이름을 바꾸지 않을 것이며 이 세 용어의 의미는 클라이언트 터미널 개발자가 설계한 것과 동일하게 유지됩니다. 결과적으로 포지션, 거래, 주문 및 거래라는 4개의 단어를 사용할 것입니다.
Order는 포지션을 열거나 변경하기 위해 서버에 명령을 내리기 때문에 통계에 직접적으로 관련되지는 않지만 거래를 통해 간접적으로 수행합니다(그 이유는 주문을 보내는 것이 항상 지정된 수량 및 가격의 해당 거래가 실행되는 것은 아니기 때문), 그러면 주문이 아닌 거래로 통계를 수집하는 것이 옳습니다.
위의 설명을 더 명확하게 하기 위해 동일한 포지션에 대한 해석의 예를 살펴보겠습니다.
interpretation in МТ-5 deal[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 deal[ 1 ] in/out 0.2 buy 1.22261 2010.06.14 13:36 deal[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 deal[ 3 ] out 0.2 sell 1.22310 2010.06.14 13:41
interpretation by Bulachev trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 out 1.22261 2010.06.14 13:36 trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36 out 1.22310 2010.06.14 13:41 trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 out 1.22310 2010.06.14 13:41
이제 이러한 조작이 수행된 방식을 설명하겠습니다. Deal[ 0 ]이 포지션을 열면, 우리는 이것을 새로운 거래의 시작으로 씁니다.
trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33
그런 다음 반대 포지션이 옵니다. 이는 모든 이전 거래가 마감되어야 함을 의미합니다. 상응하게, 역전된 거래[ 1 ] 에 대한 정보는 새로운 거래를 체결할 때와 개시할 때 모두 고려됩니다. in/out 방향의 딜 이전에 닫히지 않은 모든 거래가 종료되면 새로운 거래를 열어야 합니다. 유형 및 볼륨이 추가로 사용되는 경우, 즉. 선택한 거래에 대한 가격 및 시간 정보만 사용하여 마감합니다. 여기서 우리는 새로운 해석에 등장하기 전에 사용된 적이 없는 용어인 거래 방향을 명확히 해야 합니다. 앞에서 우리는 "방향"이라고 말함으로써 매수 또는 매도를 의미했으며 동일한 의미에는 "유형" 용어가 있었습니다. 지금부터 유형과 방향은 다른 용어입니다.
유형은 매수 또는 매도인 반면 방향은 포지션 진입 또는 퇴장입니다. 그렇기 때문에 포지션은 항상 in 방향의 거래로 열리고 out 거래로 마감됩니다. 그러나 방향은 포지션을 열고 닫는 것만으로 제한되지 않습니다. 이 조건에는 포지션의 볼륨 증가("in" 거래가 목록의 첫 번째가 아닌 경우) 및 포지션의 부분적 청산("out" 거래가 목록의 마지막이 아닌 경우)도 포함됩니다. 부분 폐쇄가 가능해지므로 반대 포지션도 도입하는 것이 논리적입니다. 역방향은 현재 포지션보다 더 큰 크기의 반대 거래가 수행될 때 발생합니다. 즉, in/out 거래입니다.
그래서 우리는 이전에 열린 거래를 마감했습니다(포지션 반전을 위해):
trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 out 1.22261 2010.06.14 13:36
나머지 거래량은 0.1랏이며 새로운 거래를 여는 데 사용됩니다.
trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36
그런 다음 방향으로 거래[ 2 ]가 오고, 다른 거래를 엽니다.
trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39
마지막으로 포지션을 마감하는 거래 - deal[ 3 ]은 아직 마감되지 않은 포지션의 모든 거래를 마감합니다.
trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36 out 1.22310 2010.06.14 13:41 trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 out 1.22310 2010.06.14 13:41
위에 설명된 해석은 Bulachev가 사용한 해석의 요지를 보여줍니다. 각 공개 거래에는 특정 진입점 과 특정 출구점이 있습니다. 이에는 볼륨 및 유형이 있습니다. 그러나 이 해석 체계는 하나의 뉘앙스, 즉 부분 닫힘을 고려하지 않습니다. 자세히 보면 거래 수가 in 거래(in/out 거래 고려)의 수와 같다는 것을 알 수 있습니다. 이 경우 in 거래로 해석할 가치가 있지만 부분 마감 시 더 많은 out 거래가 있을 것입니다 (in과 out 거래 수는 동일하지만 양으로 서로 일치하지 않는 상황이 발생할 수 있습니다.)
모든 out 거래를 처리하려면 out 거래로 해석해야 합니다. 그리고 이 모순은 처음에는 모든 in과 out 거래를 별도로 처리하는 경우 해결되지 않는 것 같습니다. (혹은 그 반대로도). 그러나 거래를 순차적으로 처리하고 각 거래에 특수 처리 규칙을 적용하면 모순이 없습니다.
다음은 out 거래의 수가 in 거래(설명 포함)의 수보다 많은 예입니다.
interpretation in МТ-5 deal[ 0 ] in 0.3 sell 1.22133 2010.06.15 08:00 deal[ 1 ] out 0.2 buy 1.22145 2010.06.15 08:01 deal[ 2 ] in/out 0.4 buy 1.22145 2010.06.15 08:02 deal[ 3 ] in/out 0.4 sell 1.22122 2010.06.15 08:03 deal[ 4 ] out 0.1 buy 1.2206 2010.06.15 08:06
interpretation by Bulachev trade[ 0 ] in 0.2 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:01 trade[ 1 ] in 0.1 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:02 trade[ 2 ] in 0.3 buy 1.22145 2010.06.15 08:02 out 1.22122 2010.06.15 08:03 trade[ 3 ] in 0.1 sell 1.22122 2010.06.15 08:03 out 1.2206 2010.06.15 08:06
오픈 후 클로징 딜이 왔지만 전체 볼륨이 아니라 일부만 있는 상황이 있습니다(0.3 랏이 열리고 0.2). 폐쇄). 그러한 상황을 처리하는 방법은? 각 거래가 동일한 거래량으로 마감되면 상황은 단일 거래로 여러 거래가 열리는 것으로 간주할 수 있습니다. 따라서 그들은 동일한 시작 지점과 다른 마감 지점을 갖게 됩니다(각 거래의 볼륨이 마감 볼륨에 의해 결정된다는 것은 분명합니다). 예를 들어, 처리를 위해 거래[ 0 ]를 선택하고 거래를 엽니다.
trade[ 0 ] in 0.3 sell 1.22133 2010.06.15 08:00
그런 다음 deal[ 1 ]을 선택하고 미결 거래를 마감하고 그러는 동안 마감 거래량이 충분하지 않다는 것을 알게 됩니다. 이전에 열린 거래의 사본을 만들고 "볼륨" 매개변수에 볼륨 부족을 지정합니다. 그 후 거래량으로 초기 거래를 마감합니다(즉, 개시 시 지정된 초기 거래량을 마감 거래량으로 변경):
trade[ 0 ] in 0.2 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:01 trade[ 1 ] in 0.1 sell 1.22133 2010.06.15 08:00
이 trader가 아닌 다른 trader를 닫고 싶어할 수 있으므로 이러한 변환은 거래자에게 적합하지 않은 것처럼 보일 수 있습니다. 그러나 어쨌든 올바른 변환의 결과로 시스템 평가가 손상되지는 않습니다. 상처를 입을 수 있는 유일한 것은 MetaTrader 4에서 손실 없는 거래에 대한 트레이더의 자신감입니다. 이 재계산 시스템은 모든 망상을 드러낼 것입니다.
Bulachev의 책에 기술된 통계적 해석 시스템은 감정이 없고 포지션, 퇴장 및 두 비율 모두의 포지션에서 결정을 정직하게 평가할 수 있습니다. 그리고 해석의 변환 가능성(데이터 손실 없이 다른 것으로 변환) 가능성은 MetaTrader 4용으로 개발된 MTS를 MetaTrader 5의 해석 시스템용으로 다시 만들 수 없다고 말하는 것이 잘못되었음을 증명합니다. 해석을 변환할 때 유일한 손실은 볼륨이 다른 주문에 속할 수 있다는 것입니다(MetaTrader 4). 그러나 실제로 더 이상 계산할 주문(이 용어의 오래된 의미)이 없다면 그것은 단지 트레이더의 주관적인 추정일 뿐입니다.
해석 변환 코드
코드 자체를 살펴봅시다. 번역기를 준비하려면 OOP의 상속 기능이 필요합니다. 그렇기 때문에 아직 익숙하지 않은 분들에게 MQL5 사용자 가이드를 열어 학습 이론을 제안하는 것입니다. 우선, 거래 해석의 구조를 설명하겠습니다(MQL5의 표준 기능을 사용하여 해당 값을 직접 가져와서 코드 속도를 높일 수 있지만 읽기가 어렵고 혼란스러울 수 있음).
//+------------------------------------------------------------------+ //| structure of deal | //+------------------------------------------------------------------+ struct S_Stat_Deals { public: ulong DTicket; // ticket of deal ENUM_DEAL_TYPE deals_type; // type of deal ENUM_DEAL_ENTRY deals_entry; // direction of deal double deals_volume; // volume of deal double deals_price; // price of opening of deal datetime deals_date; // time of opening of deal S_Stat_Deals(){}; ~S_Stat_Deals(){}; };
이 구조는 거래에 대한 모든 주요 세부 정보를 포함하며 파생된 세부 정보는 필요한 경우 계산할 수 있으므로 포함되지 않습니다. 개발자들은 이미 전략 테스터에서 Bulachev 통계의 많은 방법을 구현했기 때문에 사용자 정의 방법으로 보완하는 일만 남았습니다. 그래서 전체적인 거래의 효율성과 개폐의 효율성과 같은 방법을 구현합시다.
그리고 이러한 값을 얻으려면 거래 중 시가/종가, 시가/마감 시간, 최소/최대 가격과 같은 기본 정보의 해석을 구현해야 합니다. 그러한 기본 정보가 있으면 많은 파생 정보를 얻을 수 있습니다. 또한 저는 아래에 설명된 거래 구조에 주의를 기울이고 싶습니다. 그것은 주요 구조이며, 해석의 모든 변형은 그것을 기반으로 합니다.
//+------------------------------------------------------------------+ //| structure of trade | //+------------------------------------------------------------------+ struct S_Stat_Trades { public: ulong OTicket; // ticket of opening deal ulong CTicket; // ticket of closing deal ENUM_DEAL_TYPE trade_type; // type of trade double trade_volume; // volume of trade double max_price_trade; // maximum price of trade double min_price_trade; // minimum price of trade double enter_price; // price of opening of trade datetime enter_date; // time of opening of trade double exit_price; // price of closing of trade/s22> datetime exit_date; // time of closing of trade double enter_efficiency;// effectiveness of entering double exit_efficiency; // effectiveness of exiting double trade_efficiency;// effectiveness of trade S_Stat_Trades(){}; ~S_Stat_Trades(){}; };
이제 두 가지 주요 구조를 만들었으므로 해석을 변환하는 새 클래스 C_Pos를 정의할 수 있습니다. 우선, 거래 및 거래의 해석 구조에 대한 포인터를 선언합시다. 정보는 상속된 함수에서 필요할 수 있으므로 public으로 선언합니다. 많은 거래와 거래가 있을 수 있으므로 배열을 변수 대신 구조에 대한 포인터로 사용하십시오. 따라서 정보는 구조화되어 어디에서나 사용할 수 있습니다.
그런 다음 히스토리를 별도의 포지션으로 나누고 완전한 거래 주기에서와 같이 포지션 내에서 모든 변환을 수행해야 합니다. 그렇게 하려면 포지션의 속성(포지션의 id, 포지션의 기호, 거래 수, 거래 수)의 해석을 위한 변수를 선언합니다.
//+------------------------------------------------------------------+ //| class for transforming deals into trades | //+------------------------------------------------------------------+ class C_Pos { public: S_Stat_Deals m_deals_stats[]; // structure of deals S_Stat_Trades m_trades_stats[]; // structure of trades long pos_id; // id of position string symbol; // symbol of position int count_deals; // number of deals int count_trades; // number of trades int trades_ends; // number of closed trades int DIGITS; // accuracy of minimum volume by the symbols of position C_Pos() { count_deals=0; count_trades=0; trades_ends=0; }; ~C_Pos(){}; void OnHistory(); // creation of history of position void OnHistoryTransform();// transformation of position history into the new system of interpretation void efficiency(); // calculation of effectiveness by Bulachev's method private: void open_pos(int c); void copy_pos(int x); void close_pos(int i,int c); double nd(double v){return(NormalizeDouble(v,DIGITS));};// normalization to minimum volume void DigitMinLots(); // accuracy of minimum volume double iHighest(string symbol_name,// symbol name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ); double iLowest(string symbol_name,// symbol name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ); };
클래스에는 포지션을 처리하는 세 가지 공용 메소드가 있습니다.
OnHistory()는 포지션 기록을 생성합니다.//+------------------------------------------------------------------+ //| filling the structures of history deals | //+------------------------------------------------------------------+ void C_Pos::OnHistory() { ArrayResize(m_deals_stats,count_deals); for(int i=0;i<count_deals;i++) { m_deals_stats[i].DTicket=HistoryDealGetTicket(i); m_deals_stats[i].deals_type=(ENUM_DEAL_TYPE)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_TYPE); // type of deal m_deals_stats[i].deals_entry=(ENUM_DEAL_ENTRY)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_ENTRY);// direction of deal m_deals_stats[i].deals_volume=HistoryDealGetDouble(m_deals_stats[i].DTicket,DEAL_VOLUME); // volume of deal m_deals_stats[i].deals_price=HistoryDealGetDouble(m_deals_stats[i].DTicket,DEAL_PRICE); // price of opening m_deals_stats[i].deals_date=(datetime)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_TIME); // time of opening } };
각 거래에 대해 메소드는 구조의 복사본을 만들고 거래에 대한 정보로 채웁니다. 그것이 바로 위에서 우리가 그것 없이도 할 수 있다고 말할 때 내가 의미한 바입니다. 그러나 그것이 더 편리합니다(시간 단축의 마이크로초를 추구하는 사람들은 이러한 구조의 호출을 평등 징후의 오른쪽에 서 있는 라인으로 대체할 수 있습니다).
OnHistoryTransform()은 포지션 기록을 새로운 해석 시스템으로 변환합니다.
- 이전에 정보를 변환하는 방법에 대해 설명했습니다. 이제 그 예를 살펴보겠습니다. 변환을 위해서는 거래량을 계산해야 하는 정확한 값이 필요합니다 (최소 용량); DigitMinLots()가 이를 처리합니다. 그러나 프로그래머가 이 코드가 다른 조건에서 실행되지 않을 것이라고 확신하는 경우 이 매개변수를 생성자에 지정할 수 있고 함수를 건너뛸 수 있습니다.
- 그런 다음 count_trades 및 trades_ends 카운터를 0으로 만듭니다. 그런 다음 거래 해석 구조에 대한 메모리를 재할당합니다. 정확한 거래 수를 모르기 때문에 포지션에 있는 거래 수에 따라 메모리를 재할당해야 합니다. 더 많은 거래가 있는 것으로 나타나면 메모리를 여러 번 다시 재할당합니다. 그러나 동시에 대부분의 거래에는 충분한 메모리가 있으며 전체 어레이에 대한 메모리 할당은 기계 시간을 크게 절약합니다.
필요할 때 어디에서나 이 방법을 사용하는 것이 좋습니다. 새로운 해석 대상이 나타날 때마다 메모리를 할당하십시오. 필요한 메모리 양에 대한 정확한 정보가 없으면 대략적인 값으로 할당해야 합니다. 어쨌든 각 단계에서 전체 어레이를 재할당하는 것보다 경제적입니다.
그런 다음 포지션의 모든 거래가 세 가지 필터를 사용하여 필터링되는 루프가 발생합니다. 거래가 in, in/out인 경우 , out. 각 변형에 대해 특정 작업이 구현됩니다. 필터는 순차적이고 중첩됩니다. 즉, 한 필터가 false를 반환하면 이 경우에만 다음 필터를 확인합니다. 이러한 건설은 불필요한 조치가 제거되기 때문에 자원이 경제적입니다. 코드 가독성을 높이기 위해 클래스에서 비공개로 선언된 함수에 많은 작업이 수행됩니다. 그건 그렇고, 이러한 기능은 개발 중에 공개했지만 코드의 다른 부분에서는 이러한 기능이 필요하지 않다는 것을 깨달았으므로 프라이빗한 것으로 다시 선언되었습니다. 이것이 OOP에서 데이터의 범위를 조작할 수 있는 방법입니다.
따라서 in 필터에서 새로운 거래의 생성이 수행됩니다(open_pos() 함수). 그로 인해 포인터 배열의 크기를 1씩 늘리고 거래 구조를 거래 구조의 해당 필드에 복사하는 것입니다. 또한 거래 구조는 가격과 시간의 필드가 2배 더 많기 때문에 거래가 열릴 때 열리는 필드만 채워지므로 미완료로 계산됩니다. count_trades 와 trades_ends의 차이로 이해할 수 있습니다. 문제는 카운터에 처음부터 0 값이 있다는 것입니다. 거래가 나타나자마자 count_trades 카운터가 증가하고 거래가 종료되면 trades_ends 카운터가 증가합니다. 따라서 count_trades 와 trades_ends의 차이는 특정 시점에 종료되지 않은 거래의 수를 알려줍니다.
open_pos() 함수는 매우 간단하며 거래만 열고 해당 카운터를 트리거합니다. 다른 유사한 기능은 그렇게 간단하지 않습니다. 따라서 거래가 in 유형이 아닌 경우 in/out 또는 아웃이 될 수 있습니다. 두 가지 변종 중에서 먼저 실행이 더 쉬운 변종을 확인하십시오(이것은 근본적인 문제는 아니지만 실행 난이도가 오름차순으로 확인을 구축했습니다).
in/out 필터를 처리하는 함수는 모든 미결 거래의 오픈 포지션을 합산합니다(count_trades과 trades_ends의 차이를 사용하여 마감되지 않은 거래를 확인하는 방법에 대해서는 이미 언급했습니다). 따라서 우리는 주어진 거래로 마감된 총 거래량을 계산합니다(그리고 나머지 거래량은 현재 거래의 유형으로 다시 열릴 것입니다). 여기서 우리는 거래가 in/out 방향을 가지고 있다는 점에 유의해야 합니다. 이는 거래량이 이전에 개설된 포지션의 총 거래량을 초과한다는 것을 의미합니다. 그렇기 때문에 재개될 새로운 거래의 양을 알기 위해 포지션과 in/out 거래 간의 차이를 계산하는 것이 논리적인 이유입니다.
거래에 외부 방향이 있으면 모든 것이 훨씬 더 복잡합니다. 우선, 포지션의 마지막 거래는 항상 외부 방향을 가지므로 여기에서 예외를 두어야 합니다. 그것이 마지막 거래인 경우 우리가 가진 모든 것을 마감해야 합니다. 그렇지 않으면(거래가 마지막 거래가 아닌 경우) 두 가지 변형이 가능합니다. 거래가 in/out이 아니라 out이므로 변형은 다음과 같습니다. 첫 번째 변형은 볼륨이 시작 볼륨과 정확히 동일합니다. 즉, 볼륨 시작 거래의 양은 마감 거래의 양과 같습니다. 두 번째 변형은 해당 볼륨이 동일하지 않다는 것입니다.
첫 번째 변형은 닫음으로 처리됩니다. 두 번째 변형은 더 복잡합니다. 두 가지 변형이 다시 가능합니다. 볼륨이 더 큰 경우와 볼륨이 오프닝보다 작을 때입니다. 거래량이 많을 때 마감 거래량이 개시 거래량과 같거나 줄어들 때까지 다음 거래를 종료합니다. 볼륨이 다음 거래 전체를 마감하기에 충분하지 않은 경우(볼륨이 적음) 부분 마감을 의미합니다. 여기서 우리는 새 거래량(이전 작업 후 남은 거래량)으로 거래를 마감해야 하지만 그 전에 누락된 거래량으로 거래 사본을 만들어야 합니다. 물론 카운터도 잊지 마세요.
거래에서 거래 재개 후 부분 청산 시 나중 거래의 대기열이 이미 있는 상황이 있을 수 있습니다. 혼동을 피하기 위해 모두 하나씩 이동하여 닫는 연대기를 유지해야 합니다.
//+------------------------------------------------------------------+ //| transformation of deals into trades (engine classes) | //+------------------------------------------------------------------+ void C_Pos::OnHistoryTransform() { DigitMinLots();// fill the DIGITS value count_trades=0;trades_ends=0; ArrayResize(m_trades_stats,count_trades,count_deals); for(int c=0;c<count_deals;c++) { if(m_deals_stats[c].deals_entry==DEAL_ENTRY_IN) { open_pos(c); } else// else in { double POS=0; for(int i=trades_ends;i<count_trades;i++)POS+=m_trades_stats[i].trade_volume; if(m_deals_stats[c].deals_entry==DEAL_ENTRY_INOUT) { for(int i=trades_ends;i<count_trades;i++)close_pos(i,c); trades_ends=count_trades; open_pos(c); m_trades_stats[count_trades-1].trade_volume=m_deals_stats[c].deals_volume-POS; } else// else in/out { if(m_deals_stats[c].deals_entry==DEAL_ENTRY_OUT) { if(c==count_deals-1)// if it's the last deal { for(int i=trades_ends;i<count_trades;i++)close_pos(i,c); trades_ends=count_trades-1; } else// if it's not the last deal { double out_vol=nd(m_deals_stats[c].deals_volume); while(nd(out_vol)>0) { if(nd(out_vol)>=nd(m_trades_stats[trades_ends].trade_volume)) { close_pos(trades_ends,c); out_vol-=nd(m_trades_stats[trades_ends].trade_volume); trades_ends++; } else// if the remainder of closed position is less than the next trade { // move all trades forward by one count_trades++; ArrayResize(m_trades_stats,count_trades); for(int x=count_trades-1;x>trades_ends;x--)copy_pos(x); // open a copy with the volume equal to difference of the current position and the remainder m_trades_stats[trades_ends+1].trade_volume=nd(m_trades_stats[trades_ends].trade_volume-out_vol); // close the current trade with new volume, which is equal to remainder close_pos(trades_ends,c); m_trades_stats[trades_ends].trade_volume=nd(out_vol); out_vol=0; trades_ends++; } }// while(out_vol>0) }// if it's not the last deal }// if out }// else in/out }// else in } };
유효성 계산
해석 체계가 바뀌면 우리는 Bulachev의 방법론으로 거래의 효율성을 평가할 수 있습니다. 이러한 평가에 필요한 기능은 efficiency() 메소드에 있으며, 계산된 데이터로 거래 구조를 채우는 작업도 거기에서 수행됩니다. 진입 및 퇴장 효과는 0 ~ 1까지 측정되며, 전체 거래에 대해서는 -1 ~ 1까지 측정됩니다.
//+------------------------------------------------------------------+ //| calculation of effectiveness | //+------------------------------------------------------------------+ void C_Pos::efficiency() { for(int i=0;i<count_trades;i++) { m_trades_stats[i].max_price_trade=iHighest(symbol,PERIOD_M1,m_trades_stats[i].enter_date,m_trades_stats[i].exit_date); // maximal price of trade m_trades_stats[i].min_price_trade=iLowest(symbol,PERIOD_M1,m_trades_stats[i].enter_date,m_trades_stats[i].exit_date); // minimal price of trade double minimax=0; minimax=m_trades_stats[i].max_price_trade-m_trades_stats[i].min_price_trade;// difference between maximum and minimum if(minimax!=0)minimax=1.0/minimax; if(m_trades_stats[i].trade_type==DEAL_TYPE_BUY) { //Effectiveness of entering a position m_trades_stats[i].enter_efficiency=(m_trades_stats[i].max_price_trade-m_trades_stats[i].enter_price)*minimax; //Effectiveness of exiting from a position m_trades_stats[i].exit_efficiency=(m_trades_stats[i].exit_price-m_trades_stats[i].min_price_trade)*minimax; //Effectiveness of trade m_trades_stats[i].trade_efficiency=(m_trades_stats[i].exit_price-m_trades_stats[i].enter_price)*minimax; } else { if(m_trades_stats[i].trade_type==DEAL_TYPE_SELL) { //Effectiveness of entering a position m_trades_stats[i].enter_efficiency=(m_trades_stats[i].enter_price-m_trades_stats[i].min_price_trade)*minimax; //Effectiveness of exiting from a position m_trades_stats[i].exit_efficiency=(m_trades_stats[i].max_price_trade-m_trades_stats[i].exit_price)*minimax; //Effectiveness of trade m_trades_stats[i].trade_efficiency=(m_trades_stats[i].enter_price-m_trades_stats[i].exit_price)*minimax; } } } }
이 메소드는 두 개의 private 메소드인 iHighest() 및 iLowest()를 사용하며 유사하며 유일한 차이점은 요청된 데이터와 검색 기능 fmin 또는 fmax입니다.
//+------------------------------------------------------------------+ //| searching maximum within the period start_time --> stop_time | //+------------------------------------------------------------------+ double C_Pos::iHighest(string symbol_name,// symbols name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ) { double buf[]; datetime start_t=(start_time/60)*60;// normalization of time of opening datetime stop_t=(stop_time/60+1)*60;// normaliztion of time of closing int period=CopyHigh(symbol_name,timeframe,start_t,stop_t,buf); double res=buf[0]; for(int i=1;i<period;i++) res=fmax(res,buf[i]); return(res); }
이 메소드는 지정된 두 날짜 사이의 기간 내에서 최대값을 검색합니다. 날짜는 start_time 및 stop_time 매개변수로 함수에 전달됩니다. 거래 날짜는 함수에 전달되고 1분 바 중간에도 거래 요청이 올 수 있으므로 함수 내부에서 가장 가까운 바 값으로 날짜 정규화를 수행합니다. iLowest() 함수에서도 마찬가지입니다. 개발된 메소드 효율성()을 사용하여 포지션 작업을 위한 전체 기능을 사용할 수 있습니다. 그러나 아직 포지션 자체에 대한 처리는 없습니다. 이전의 모든 방법을 사용할 수 있는 새 클래스를 결정하여 이를 따라잡아 보겠습니다. 즉, C_Pos의 파생으로 선언합니다.
파생 클래스(엔진 클래스)
class C_PosStat:public C_Pos
통계 정보를 고려하려면 새 클래스에 제공될 구조를 만드십시오.
//+------------------------------------------------------------------+ //| structure of effectiveness | //+------------------------------------------------------------------+ struct S_efficiency { double enter_efficiency; // effectiveness of entering double exit_efficiency; // effectiveness of exiting double trade_efficiency; // effectiveness of trade S_efficiency() { enter_efficiency=0; exit_efficiency=0; trade_efficiency=0; }; ~S_efficiency(){}; };
그리고 클래스 자체의 본문:
//+------------------------------------------------------------------+ //| class of statistics of trade in whole | //+------------------------------------------------------------------+ class C_PosStat:public C_Pos { public: int PosTotal; // number of positions in history C_Pos pos[]; // array of pointers to positions int All_count_trades; // total number of trades in history S_efficiency trade[]; // array of pointers to the structure of effectiveness of entering, exiting and trades S_efficiency avg; // pointer to the structure of average value of effectiveness of entering, exiting and trades S_efficiency stdev; // pointer to the structure of standard deviation from // average value of effectiveness of entering, exiting and trades C_PosStat(){PosTotal=0;}; ~C_PosStat(){}; void OnPosStat(); // engine classes void OnTradesStat(); // gathering information about trades into the common array // functions of writing information to a file void WriteFileDeals(string folder="deals"); void WriteFileTrades(string folder="trades"); void WriteFileTrades_all(string folder="trades_all"); void WriteFileDealsHTML(string folder="deals"); void WriteFileDealsHTML2(string folder="deals"); void WriteFileTradesHTML(string folder="trades"); void WriteFileTradesHTML2(string folder="trades"); string enum_translit(ENUM_DEAL_ENTRY x,bool latin=true);// transformation of enumeration into string string enum_translit(ENUM_DEAL_TYPE x,bool latin=true); // transformation of enumeration into string (overloaded) private: S_efficiency AVG(int count); // arithmetical mean S_efficiency STDEV(const S_efficiency &mo,int count); // standard deviation S_efficiency add(const S_efficiency &a,const S_efficiency &b); //add S_efficiency take(const S_efficiency &a,const S_efficiency &b); //subtract S_efficiency multiply(const S_efficiency &a,const S_efficiency &b); //multiply S_efficiency divided(const S_efficiency &a,double b); //divide S_efficiency square_root(const S_efficiency &a); //square root string Head_style(string title); };
이 클래스를 처음부터 끝까지 역방향으로 분석하는 것이 좋습니다. 모든 것은 거래 테이블을 작성하고 파일로 거래하는 것으로 끝납니다. 이를 위해 함수 행이 작성되었습니다(이름에서 서로의 목적을 이해할 수 있음). 이 함수는 거래 및 거래에 대한 csv 보고서와 두 가지 유형의 html 보고서를 만듭니다(시각적으로만 다르지만 내용은 동일함).
void WriteFileDeals(); // writing csv report on deals void WriteFileTrades(); // writing csv report on trade void WriteFileTrades_all(); // writing summary csv report of fitness functions void WriteFileDealsHTML2(); // writing html report on deals, 1 variant void WriteFileTradesHTML2();// writing html report on trades, 2 variant
enum_translit() 함수는 enumerations의 값을 로그 파일에 쓰기 위해 string 유형으로 변환하기 위한 것입니다. private 섹션에는 S_efficiency 구조의 여러 기능이 포함되어 있습니다. 모든 함수는 언어의 단점, 특히 구조를 사용한 산술 연산을 보완합니다. 이러한 방법의 구현에 대한 의견이 다르기 때문에 다른 방식으로 구현될 수 있습니다. 나는 그것들을 구조 분야의 산술 연산 방법으로 깨달았습니다. 누군가는 개별적인 방법을 사용하여 구조의 각 필드를 처리하는 것이 더 낫다고 말할 수 있습니다. 요약하자면 프로그래머만큼 의견이 많다고 말씀드리고 싶습니다. 미래에는 내장된 메소드를 사용하여 이러한 작업을 수행할 수 있기를 바랍니다.
AVG() 메소드는 전달된 배열의 산술 평균값을 계산하지만 전체 분포를 보여주지 않기 때문에 표준 편차 STDEV()를 계산하는 다른 메서드가 제공됩니다. OnTradesStat() 함수는 효율성 값(이전에 OnPosStat()에서 계산됨)을 가져와 통계적 방법으로 처리합니다. 마지막으로 클래스의 주요 기능인 OnPosStat()입니다.
이 기능을 자세히 고려해야 합니다. 두 부분으로 구성되어 있어 쉽게 나눌 수 있습니다. 첫 번째 부분은 모든 포지션을 검색하고 임시 배열 id_pos에 저장하여 id를 처리합니다. 단계별: 사용 가능한 전체 내역을 선택하고 거래 수를 계산하고 거래 처리 주기를 실행합니다. 주기: 거래 유형이 잔액이면 건너뛰고(시작 거래를 해석할 필요가 없음), 그렇지 않으면 - 포지션의 id 를 변수에 저장하고 검색을 수행합니다. 동일한 id가 이미 기본(id_po 배열)에 존재하는 경우 다음 거래로 이동하고, 그렇지 않으면 기본에 id 를 씁니다. 이러한 방식으로 모든 거래를 처리한 후 배열은 기존의 모든 id 포지션와 포지션 수로 채워집니다.
long id_pos[];// auxiliary array for creating the history of positions if(HistorySelect(0,TimeCurrent())) { int HTD=HistoryDealsTotal(); ArrayResize(id_pos,PosTotal,HTD); for(int i=0;i<HTD;i++) { ulong DTicket=(ulong)HistoryDealGetTicket(i); if((ENUM_DEAL_TYPE)HistoryDealGetInteger(DTicket,DEAL_TYPE)==DEAL_TYPE_BALANCE) continue;// if it's a balance deal, skip it long id=HistoryDealGetInteger(DTicket,DEAL_POSITION_ID); bool present=false; // initial state, there's no such position for(int j=0;j<PosTotal;j++) { if(id==id_pos[j]){ present=true; break; } }// if such position already exists break if(!present)// write id as a new position appears { PosTotal++; ArrayResize(id_pos,PosTotal); id_pos[PosTotal-1]=id; } } } ArrayResize(pos,PosTotal);
두 번째 부분에서는 이전에 기본 클래스 C_Pos에 설명된 모든 메소드를 구현합니다. 포지션을 넘어 해당 포지션 처리 방법을 실행하는 주기로 구성됩니다. 방법에 대한 설명은 아래 코드에 나와 있습니다.
for(int p=0;p<PosTotal;p++) { if(HistorySelectByPosition(id_pos[p]))// select position { pos[p].pos_id=id_pos[p]; // assigned id of position to the corresponding field of the class C_Pos pos[p].count_deals=HistoryDealsTotal();// assign the number of deal in position to the field of the class C_Pos pos[p].symbol=HistoryDealGetString(HistoryDealGetTicket(0),DEAL_SYMBOL);// the same actions with symbol pos[p].OnHistory(); // start filling the structure sd with the history of position pos[p].OnHistoryTransform(); // transformation of interpretation, filling the structure st. pos[p].efficiency(); // calculation of the effectiveness of obtained data All_count_trades+=pos[p].count_trades;// save the number of trades for displaying the total number } }
클래스의 메소드 호출
그래서 우리는 전체 클래스를 고려했습니다. 부름의 예를 들어주는 것이 남았습니다. 구성 가능성을 유지하기 위해 하나의 함수에서 명시적으로 호출을 선언하지 않았습니다. 또한 필요에 따라 클래스를 향상시키고 새로운 데이터 통계 처리 방법을 구현할 수 있습니다. 다음은 스크립트에서 클래스의 메소드를 호출하는 예입니다.
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ #include <Bulaschev_Statistic.mqh> void OnStart() { C_PosStat start; start.OnPosStat(); start.OnTradesStat(); start.WriteFileDeals(); start.WriteFileTrades(); start.WriteFileTrades_all(); start.WriteFileDealsHTML2(); start.WriteFileTradesHTML2(); Print("cko tr ef=" ,start.stdev.trade_efficiency); Print("mo tr ef=" ,start.avg.trade_efficiency); Print("cko out ef=",start.stdev.exit_efficiency); Print("mo out ef=",start.avg.exit_efficiency); Print("cko in ef=" ,start.stdev.enter_efficiency); Print("mo in ef=" ,start.avg.enter_efficiency); }
스크립트는 Files\OnHistory 디렉토리의 파일에 데이터를 쓰는 함수의 양에 따라 5개의 보고서 파일을 생성합니다. 다음 주요 기능이 여기에 있습니다. OnPosStat() 및 OnTradesStat(), 필요한 모든 메소드를 호출하는 데 사용됩니다. 스크립트는 얻은 거래의 효율성 값을 전체적으로 프린트하는 것으로 끝납니다. 이러한 각 값은 유전자 최적화에 사용할 수 있습니다.
최적화하는 동안 각 보고서를 파일에 작성할 필요가 없기 때문에 Expert Advisor에서 클래스 호출이 약간 다르게 보입니다. 첫째, 스크립트와 달리 Expert Advisor는 테스터에서 실행할 수 있습니다(이를 위해 준비했습니다). 전략 테스터에서 일하는 것은 그 특징이 있습니다. 최적화할 때 OnDeinit() 함수가 실행되기 전에 실행이 수행되는 OnTester() 함수에 액세스할 수 있습니다. 따라서 주요 변환 방법의 호출을 분리할 수 있습니다. Expert Advisor의 매개변수에서 피트니스 함수를 수정하기 쉽도록 클래스의 일부가 아닌 전역적으로 열거형을 선언했습니다. 열거는 C_PosStat 클래스의 메소드와 동일한 시트에 있습니다.
//+------------------------------------------------------------------+ //| enumeration of fitness functions | //+------------------------------------------------------------------+ enum Enum_Efficiency { avg_enter_eff, stdev_enter_eff, avg_exit_eff, stdev_exit_eff, avg_trade_eff, stdev_trade_eff };
이것은 Expert Advisor의 제목에 추가되어야 하는 내용입니다.
#include <Bulaschev_Statistic.mqh> input Enum_Efficiency result=0;// Fitness function
이제 switch 연산자를 사용하여 필요한 매개변수의 전달을 설명할 수 있습니다.
//+------------------------------------------------------------------+ //| Expert optimization function | //+------------------------------------------------------------------+ double OnTester() { start.OnPosStat(); start.OnTradesStat(); double res; switch(result) { case 0: res=start.avg.enter_efficiency; break; case 1: res=-start.stdev.enter_efficiency; break; case 2: res=start.avg.exit_efficiency; break; case 3: res=-start.stdev.exit_efficiency; break; case 4: res=start.avg.trade_efficiency; break; case 5: res=-start.stdev.trade_efficiency; break; default : res=0; break; } return(res); }
커스텀 함수의 극대화를 위해 OnTester() 함수를 사용한다는 사실에 주목하고 싶습니다. 사용자 정의 함수의 최소값을 찾아야 하는 경우 -1을 곱하여 함수 자체를 반대로 하는 것이 좋습니다. 표준편차가 있는 예와 같이 stdev가 작을수록 거래의 실효성 차이가 작아 거래의 안정성이 높다는 것은 누구나 알고 있습니다. 그렇기 때문에 stdev를 최소화해야 합니다. 이제 클래스 메소드 호출을 다루었으므로 보고서를 파일에 작성하는 것을 고려해 보겠습니다.
이전에 보고서를 생성하는 클래스 메소드에 대해 언급했습니다. 이제 어디서, 언제 호출해야 하는지 알아보겠습니다. 보고서는 Expert Advisor가 단일 실행에 대해 시작된 경우에만 생성되어야 합니다. 그렇지 않으면 Expert Advisor가 최적화 모드에서 파일을 생성합니다. 즉, 하나의 파일 대신 많은 파일(매번 다른 파일 이름이 전달되는 경우) 또는 하나를 생성하지만 모든 실행에 대해 동일한 이름을 가진 마지막 파일은 정보를 위한 리소스를 낭비하기 때문에 절대적으로 의미가 없습니다. 더 지워지는 것입니다.
어쨌든 최적화 중에는 보고서 파일을 생성해서는 안 됩니다. 이름이 다른 파일이 많이 있으면 대부분 열지 않을 것입니다. 두 번째 변종은 즉시 삭제되는 정보를 얻기 위해 리소스를 낭비합니다.
그렇기 때문에 가장 좋은 변형은 필터를 만드는 것입니다(최적화[비활성화] 모드에서만 보고서 시작). 따라서 HDD는 본 적이 없는 보고서로 가득 차 있지 않습니다. 또한 최적화 속도가 증가합니다(가장 느린 작업이 파일 작업이라는 것은 비밀이 아닙니다). 또한 필요한 매개변수가 포함된 보고서를 빠르게 얻을 수 있는 가능성이 유지됩니다. 사실, OnTester 또는 OnDeinit 함수에서 필터를 배치할 포지션는 중요하지 않습니다. 중요한 것은 보고서를 생성하는 클래스 메소드가 변환을 수행하는 주요 메소드 다음에 호출되어야 한다는 것입니다. 코드에 과부하가 걸리지 않도록 OnDeinit()에 필터를 배치했습니다.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(!(bool)MQL5InfoInteger(MQL5_OPTIMIZATION)) { start.WriteFileDeals(); // writing csv report on deals start.WriteFileTrades(); // writing csv report on trades start.WriteFileTrades_all(); // writing summary csv report on fitness functions start.WriteFileDealsHTML2(); // writing html report on deals start.WriteFileTradesHTML2();// writing html report on trades } } //+------------------------------------------------------------------+
메소드 호출 순서는 중요하지 않습니다. 보고서 작성에 필요한 모든 것은 OnPosStat 및 OnTradesStat 메소드에 준비되어 있습니다. 또한 보고서 작성의 모든 방법을 호출하든 일부만 호출하든 상관 없습니다. 각각의 작동은 개별적입니다. 그것은 클래스에 이미 저장된 정보의 해석입니다.
전략 테스터 확인
전략 테스터의 단일 실행 결과는 다음과 같습니다.
거래 보고서 이동 평균 통계 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # | 티켓 | 유형 | 용량 | 열기 | 닫기 | 가격 | 능률 | ||||||
| 열기 | 닫기 | 가격 | 시각 | 가격 | 시각 | 최대 | 최소 | 출구 | 거래 | trade | |||
| 포지션[0] | id 2 | EURUSD | |||||||||||
| 0 | 2 | 3 | 구입 | 0.1 | 1.37203 | 2010.03.15 13:00:00 | 1.37169 | 2010.03.15 14:00:00 | 1.37236 | 1.37063 | 0.19075 | 0.61272 | -0.19653 |
| 포지션[1] | id 4 | EURUSD | |||||||||||
| 1 | 4 | 5 | 팔다 | 0.1 | 1.35188 | 2010.03.23 08:00:00 | 1.35243 | 2010.03.23 10:00:00 | 1.35292 | 1.35025 | 0.61049 | 0.18352 | -0.20599 |
| 포지션[2] | id 6 | EURUSD | |||||||||||
| 2 | 6 | 7 | 팔다 | 0.1 | 1.35050 | 2010.03.23 12:00:00 | 1.35343 | 2010.03.23 16:00:00 | 1.35600 | 1.34755 | 0.34911 | 0.30414 | -0.34675 |
| 포지션[3] | id 8 | EURUSD | |||||||||||
| 3 | 8 | 9 | 팔다 | 0.1 | 1.35167 | 2010.03.23 18:00:00 | 1.33343 | 2010.03.26 05:00:00 | 1.35240 | 1.32671 | 0.97158 | 0.73842 | 0.71000 |
| 포지션[4] | id 10 | EURUSD | |||||||||||
| 4 | 10 | 11 | 팔다 | 0.1 | 1.34436 | 2010.03.30 16:00:00 | 1.33616 | 2010.04.08 23:00:00 | 1.35904 | 1.32821 | 0.52384 | 0.74213 | 0.26597 |
| 포지션[5] | id 12 | EURUSD | |||||||||||
| 5 | 12 | 13 | 구입 | 0.1 | 1.35881 | 2010.04.13 08:00:00 | 1.35936 | 2010.04.15 10:00:00 | 1.36780 | 1.35463 | 0.68261 | 0.35915 | 0.04176 |
| 포지션[6] | id 14 | EURUSD | |||||||||||
| 6 | 14 | 15 | 팔다 | 0.1 | 1.34735 | 2010.04.20 04:00:00 | 1.34807 | 2010.04.20 10:00:00 | 1.34890 | 1.34492 | 0.61055 | 0.20854 | -0.18090 |
| 포지션[7] | id 16 | EURUSD | |||||||||||
| 7 | 16 | 17 | 팔다 | 0.1 | 1.34432 | 2010.04.20 18:00:00 | 1.33619 | 2010.04.23 17:00:00 | 1.34491 | 1.32016 | 0.97616 | 0.35232 | 0.32848 |
| 포지션[8] | id 18 | EURUSD | |||||||||||
| 8 | 18 | 19 | 팔다 | 0.1 | 1.33472 | 2010.04.27 10:00:00 | 1.32174 | 2010.04.29 05:00:00 | 1.33677 | 1.31141 | 0.91916 | 0.59267 | 0.51183 |
| 포지션[9] | id 20 | EURUSD | |||||||||||
| 9 | 20 | 21 | 팔다 | 0.1 | 1.32237 | 2010.05.03 04:00:00 | 1.27336 | 2010.05.07 20:00:00 | 1.32525 | 1.25270 | 0.96030 | 0.71523 | 0.67553 |
유효성 보고서 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 피트니스 기능 | 평균값 | 표준 편차 | |||||||||||
| 입력하다 | 0.68 | 0.26 | |||||||||||
| 출구 | 0.48 | 0.21 | |||||||||||
| 거래 | 0.16 | 0.37 | |||||||||||
그리고 잔액 그래프는 다음과 같습니다.
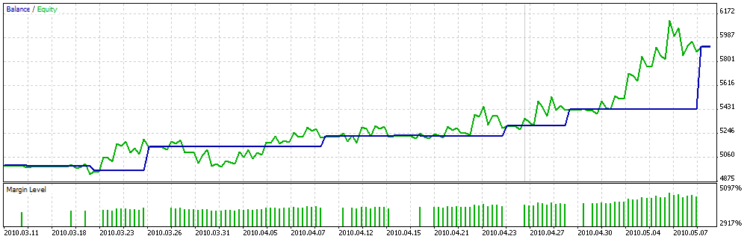
차트에서 최적화의 사용자 정의 기능이 더 많은 양의 거래가 있는 매개변수를 선택하려고 하지 않고 거래가 거의 동일한 이익을 갖는 긴 기간의 거래를 선택하려고 한다는 것을 분명히 볼 수 있습니다. 즉, 분산이 높지 남ㄹ자믐 쯕니 죄 미자.
이동평균의 코드에는 포지션의 볼륨을 늘리거나 부분적으로 닫는 기능이 포함되어 있지 않기 때문에 변환 결과는 위에서 설명한 것과 비슷하지 않은 것 같습니다. 아래에서 특히 코드 테스트를 위해 개설한 계정에서 스크립트를 실행한 다른 결과를 찾을 수 있습니다.
| 포지션[286] | id 1019514 | EURUSD | |||||||||||
| 944 | 1092288 | 1092289 | 구입 | 0.1 | 1.26733 | 2010.07.08 21:14:49 | 1.26719 | 2010.07.08 21:14:57 | 1.26752 | 1.26703 | 0.38776 | 0.32653 | -0.28571 |
| 포지션[287] | id 1019544 | EURUSD | |||||||||||
| 945 | 1092317 | 1092322 | 팔다 | 0.2 | 1.26761 | 2010.07.08 21:21:14 | 1.26767 | 2010.07.08 21:22:29 | 1.26781 | 1.26749 | 0.37500 | 0.43750 | -0.18750 |
| 946 | 1092317 | 1092330 | 팔다 | 0.2 | 1.26761 | 2010.07.08 21:21:14 | 1.26792 | 2010.07.08 21:24:05 | 1.26782 | 1.26749 | 0.36364 | -0.30303 | -0.93939 |
| 947 | 1092319 | 1092330 | 팔다 | 0.3 | 1.26761 | 2010.07.08 21:21:37 | 1.26792 | 2010.07.08 21:24:05 | 1.26782 | 1.26749 | 0.36364 | -0.30303 | -0.93939 |
| 포지션[288] | id 1019623 | EURUSD | |||||||||||
| 948 | 1092394 | 1092406 | 구입 | 0.1 | 1.26832 | 2010.07.08 21:36:43 | 1.26843 | 2010.07.08 21:37:38 | 1.26882 | 1.26813 | 0.72464 | 0.43478 | 0.15942 |
| 포지션[289] | id 1019641 | EURUSD | |||||||||||
| 949 | 1092413 | 1092417 | 구입 | 0.1 | 1.26847 | 2010.07.08 21:38:19 | 1.26852 | 2010.07.08 21:38:51 | 1.26910 | 1.26829 | 0.77778 | 0.28395 | 0.06173 |
| 950 | 1092417 | 1092433 | 팔다 | 0.1 | 1.26852 | 2010.07.08 21:38:51 | 1.26922 | 2010.07.08 21:39:58 | 1.26916 | 1.26829 | 0.26437 | -0.06897 | -0.80460 |
| 포지션[290] | id 1150923 | EURUSD | |||||||||||
| 951 | 1226007 | 1226046 | 구입 | 0.2 | 1.31653 | 2010.08.05 16:06:20 | 1.31682 | 2010.08.05 16:10:53 | 1.31706 | 1.31611 | 0.55789 | 0.74737 | 0.30526 |
| 952 | 1226024 | 1226046 | 구입 | 0.3 | 1.31632 | 2010.08.05 16:08:31 | 1.31682 | 2010.08.05 16:10:53 | 1.31706 | 1.31611 | 0.77895 | 0.74737 | 0.52632 |
| 953 | 1226046 | 1226066 | 팔다 | 0.1 | 1.31682 | 2010.08.05 16:10:53 | 1.31756 | 2010.08.05 16:12:49 | 1.31750 | 1.31647 | 0.33981 | -0.05825 | -0.71845 |
| 954 | 1226046 | 1226078 | 팔다 | 0.2 | 1.31682 | 2010.08.05 16:10:53 | 1.31744 | 2010.08.05 16:15:16 | 1.31750 | 1.31647 | 0.33981 | 0.05825 | -0.60194 |
| 포지션[291] | id 1155527 | EURUSD | |||||||||||
| 955 | 1230640 | 1232744 | 팔다 | 0.1 | 1.31671 | 2010.08.06 13:52:11 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.31648 | 0.01370 | 0.24062 | -0.74568 |
| 956 | 1231369 | 1232744 | 팔다 | 0.1 | 1.32584 | 2010.08.06 14:54:53 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.32518 | 0.08158 | 0.49938 | -0.41904 |
| 957 | 1231455 | 1232744 | 팔다 | 0.1 | 1.32732 | 2010.08.06 14:58:13 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.32539 | 0.24492 | 0.51269 | -0.24239 |
| 958 | 1231476 | 1232744 | 팔다 | 0.1 | 1.32685 | 2010.08.06 14:59:47 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.32539 | 0.18528 | 0.51269 | -0.30203 |
| 959 | 1231484 | 1232744 | 팔다 | 0.2 | 1.32686 | 2010.08.06 15:00:20 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.32539 | 0.18655 | 0.51269 | -0.30076 |
| 960 | 1231926 | 1232744 | 팔다 | 0.4 | 1.33009 | 2010.08.06 15:57:32 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.32806 | 0.38964 | 0.77543 | 0.16507 |
| 961 | 1232591 | 1232748 | 팔다 | 0.4 | 1.33123 | 2010.08.06 17:11:29 | 1.32850 | 2010.08.06 17:40:40 | 1.33129 | 1.32806 | 0.98142 | 0.86378 | 0.84520 |
| 962 | 1232591 | 1232754 | 팔다 | 0.4 | 1.33123 | 2010.08.06 17:11:29 | 1.32829 | 2010.08.06 17:42:14 | 1.33129 | 1.32796 | 0.98198 | 0.90090 | 0.88288 |
| 963 | 1232591 | 1232757 | 팔다 | 0.2 | 1.33123 | 2010.08.06 17:11:29 | 1.32839 | 2010.08.06 17:43:15 | 1.33129 | 1.32796 | 0.98198 | 0.87087 | 0.85285 |
| 포지션[292] | id 1167490 | EURUSD | |||||||||||
| 964 | 1242941 | 1243332 | 팔다 | 0.1 | 1.31001 | 2010.08.10 15:54:51 | 1.30867 | 2010.08.10 17:17:51 | 1.31037 | 1.30742 | 0.87797 | 0.57627 | 0.45424 |
| 965 | 1242944 | 1243333 | 팔다 | 0.1 | 1.30988 | 2010.08.10 15:55:03 | 1.30867 | 2010.08.10 17:17:55 | 1.31037 | 1.30742 | 0.83390 | 0.57627 | 0.41017 |
| 포지션[293] | id 1291817 | EURUSD | |||||||||||
| 966 | 1367532 | 1367788 | 팔다 | 0.4 | 1.28904 | 2010.09.06 00:24:01 | 1.28768 | 2010.09.06 02:53:21 | 1.28965 | 1.28710 | 0.76078 | 0.77255 | 0.53333 |
변환된 정보는 다음과 같습니다. 독자들에게 모든 것을 의도적으로 고려할 수 있는 가능성을 제공하기 위해(그리고 인지는 비교를 통해 온다), 거래의 원래 이력을 별도의 파일에 저장합니다. 이것은 MetaTrader 4의 [결과] 섹션에서 보는 데 익숙한 많은 trader들이 놓치고 있는 기록입니다.
결론
결론적으로 저는 개발자들에게 Expert Advisors를 사용자 정의 매개변수로 최적화할 수 있는 가능성을 추가할 뿐만 아니라 다른 최적화 기능과 마찬가지로 표준 매개변수와 조합하여 만들 수 있는 가능성을 추가할 것을 제안하고 싶습니다. 이 글을 요약하면 이 글에는 기본, 즉 초기 잠재력만 포함되어 있다고 말할 수 있습니다. 그리고 독자들이 자신의 필요에 따라 클래스를 향상시킬 수 있기를 바랍니다. 행운을 빕니다!
MetaQuotes 소프트웨어 사를 통해 러시아어가 번역됨.
원본 기고글: https://www.mql5.com/ru/articles/137
 Bill Williams의 "New Trading Dimensions"에 기반한 Expert Advisor
Bill Williams의 "New Trading Dimensions"에 기반한 Expert Advisor
 MQL5에서 추세를 찾는 여러 방법
MQL5에서 추세를 찾는 여러 방법
 적응형 거래 시스템과 MetaTrader 5 클라이언트 터미널에서의 사용
적응형 거래 시스템과 MetaTrader 5 클라이언트 터미널에서의 사용
 MQL5에서 다중 색상 표시기 만들기
MQL5에서 다중 색상 표시기 만들기