
Expert Advisor 개발 기초부터 (파트 15): 웹에서 데이터 액세스 하기(I)

소개
MetaTrader 5는 트레이더가 원하는 가장 다재다능 하고 완벽한 플랫폼입니다. 이 플랫폼은 단순히 차트를 관찰하는 것 외에 바로 매수 및 매도 작업을 할 수 있기 때문에 매우 효과적이고 강력합니다.
이 모든 힘은 이 플랫폼이 현재 존재하는 가장 강력한 언어와 거의 동일한 언어를 사용한다는 사실에서 비롯됩니다 - C/C ++에 대해 이야기하는 것입니다 이 언어가 제공하는 가능성은 프로그래밍 기술이 없는 일반 거래자가 수행하거나 이해할 수 있는 것보다 훨씬 더 많고 뛰어납니다.
시장에서 운영하는 동안 우리는 글로벌 수준에서 관련된 다양한 문제와 어떻게든 연결될 필요가 있습니다. 우리는 차트에만 집착할 수 없습니다 - 다른 관련된 정보를 고려하는 것이 중요합니다. 이 정보는 결정적인 요인이 될 수 있고 거래에서 승패를 가르는 차이가 될 수 있습니다.
웹에는 엄청난 양의 정보를 제공하는 많은 웹사이트가 있습니다. 여러분이 알아야 할 것은 어디에서 이 정보를 찾고 가장 잘 사용할 수 있을까 하는 점입니다. 적절한 기간 동안 더 나은 정보를 얻을수록 거래에 더 좋습니다. 그러나 브라우저를 사용하게 된다면 그것이 무엇이든 특정 정보를 잘 필터링하기가 매우 어렵다는 점, 많은 화면과 모니터를 보아야 한다는 점 등 정보는 존재 하지만 정보를 사용하는 것은 불가능합니다.
그러나 C/C++에 매우 가까운 MQL5 덕분에 프로그래머는 차트를 그대로 사용하는 것 이상을 수행할 수 있습니다: 우리는 웹에서 데이터를 찾고 필터링하고 분석할 수 있습니다. 우리는 컴퓨팅 성능을 우리에게 최대한 유리하게 사용할 것입니다.
1.0. 계획
계획 부분이 중요합니다. 첫째, 사용하려는 정보를 어디서 얻을 수 있는지 찾아야 합니다. 정보 출처가 좋은 곳이면 우리에게 올바른 방향을 알려줄 것이기 때문에 실제로는 보이는 것보다 훨씬 더 주의를 기울여 수행해야 합니다. 거래자는 서로 다른 시간에 일부 특정 데이터가 필요할 수 있으므로 모든 사람이 개별적으로 이 단계를 수행해야 합니다.
어떤 소스를 선택하든 기본적으로 모든 사람이 다음에 할 작업은 동일하므로 이 기사는 외부 툴 없이 MQL5에서 제공하는 방법과 도구를 사용하려는 사람들에게 좋은 학습 자료가 될 수 있습니다.
전체 프로세스를 설명하고 전체가 어떻게 작동하는지 보여주기 위해 시장 정보 웹 페이지를 사용할 것입니다. 프로세스의 모든 단계를 거치면서 여러분은 이 방법을 여러분들 자신의 요구 사항에 맞게 조정할 수 있을 것입니다.
1.0.1. 캡처 프로그램 개발
데이터 작업을 시작하려면 데이터를 수집하고 데이터를 효율적이고 정확하게 분석할 수 있는 작은 프로그램을 만들어야 합니다. 이를 위해 우리는 아래와 같은 매우 간단한 프로그램을 사용할 것입니다:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { Print(GetDataURL("https://tradingeconomics.com/stocks")); } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 750) { string headers; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; if ((handle = FileOpen("url.txt", FILE_WRITE | FILE_BIN)) != INVALID_HANDLE) { FileWriteArray(handle, charResultPage, 0, ArraySize(charResultPage)); FileClose(handle); }else return "Error saving file ..."; return "File saved successfully..."; }
이 프로그램은 매우 간단합니다. 이보다 더 간단할 수는 없습니다.
우리는 다음을 수행할 것입니다: 강조 표시된 부분에서 우리는 정보를 받으려는 사이트를 나타낼 것입니다. 브라우저를 사용하지 않는 이유는 무엇일까요? 브라우저에서 정보를 캡처할 수 있는 것은 사실이지만 우리는 데이터를 다운로드한 후 정보를 찾는 데 도움이 되도록 사용할 것입니다.
그러나 이 프로그램을 타이핑하고 컴파일하는 것은 아무 소용이 없습니다. 또 해야 할 일이 있습니다. 그렇지 않으면 프로그램은 작동하지 않을 것입니다.
MetaTrader 플랫폼에서 이 스크립트를 실행하기 전에 여러분이 원하는 사이트로부터 플랫폼이 데이터를 수신하도록 허용해야 합니다. MetaTrader 플랫폼을 설치해야 할 때마다 이 작업을 수행하지 않으려면 모든 것을 설정한 후 이 데이터의 백업 사본을 저장할 수 있습니다. 파일은 다음 경로에 저장해야 합니다.
C:\Users\< USER NAME >\AppData\Roaming\MetaQuotes\Terminal\< CODE PERSONAL >\config\common.ini
USER NAME은 운영 체제의 사용자 이름입니다. CODE PERSONAL은 플랫폼이 설치 중에 생성하는 값입니다. 따라서 백업을 만들거나 새로 설치한 후 교체할 파일을 쉽게 찾을 수 있습니다. 한 가지만 말씀드리면 이 장소는 WINDOWS 시스템에 속합니다.
이제 우리가 만든 스크립트로 돌아가 봅시다. 사전 설정 없이 사용하면 메시지 상자에 다음과 같이 표시됩니다.
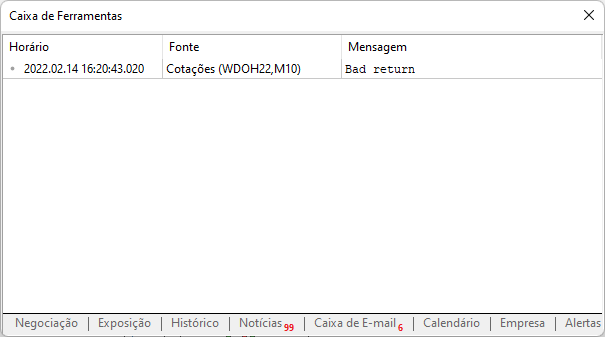
이 메시지는 MetaTrader 플랫폼에서 웹사이트를 허용하지 않았기 때문에 표시되었습니다. 이 부분은 아래 그림과 같이 구현해야 합니다. 추가된 내용에 주목하세요. 추가된 내용은 MetaTrader 거래 플랫폼을 통해 우리가 액세스할 사이트 루트 주소라는 점에 유의하십시오.
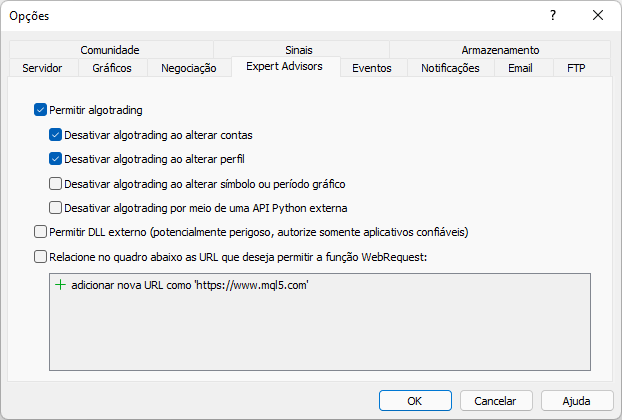

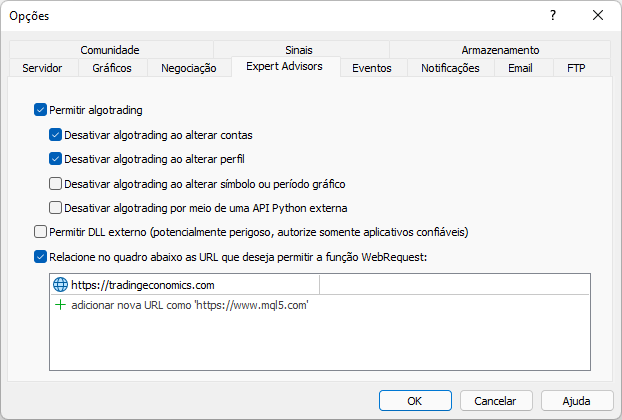
이제 동일한 스크립트를 다시 실행하면 플랫폼에서 보고한 다음과 같은 출력 내용이 표시됩니다.
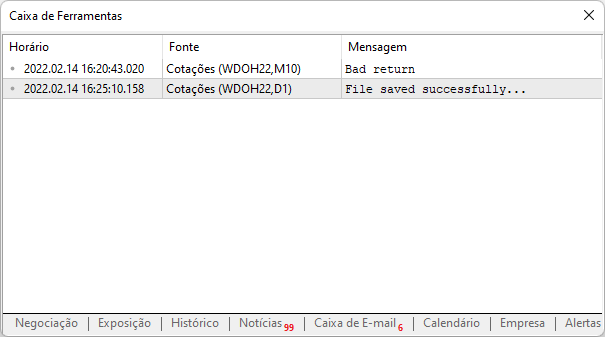
이는 사이트에 성공적으로 액세스했고 데이터가 컴퓨터에 다운로드 되었으며 이제 분석할 수 있다는 것을 의미합니다. 이는 이제 동일한 사이트를 플랫폼에 다시 추가하는 것에 대해 걱정할 필요가 없다는 것을 말합니다. 물론 위에 표시된 경로에서 이 파일의 백업을 생성하여야 가능합니다.
여기에서 모든 것이 어떻게 작동하는지 이해하고 더 자세한 정보를 얻으려면 문서에서WebRequest 함수에 대해 알아 볼 수 있습니다. 네트워크 통신 프로토콜에 대해 더 자세히 알아보려면 MQL5에 제시된 다른 네트워크 함수를 살펴보는 것이 좋습니다. 이러한 기능을 알게 되면 많은 수고를 덜 수 있습니다.
우리는 작업의 첫 번째 부분을 완료했습니다. - 원하는 사이트에서 데이터를 다운로드했습니다. 이제 우리는 중요한 다음 단계를 거쳐야 합니다.
1.0.2. 데이터 검색
웹 사이트 내에서 MetaTrader 5 플랫폼으로 캡처할 데이터를 검색하는 방법을 모르는 분들을 위해 이 검색을 진행하는 방법에 대해 알려주는 짧은 비디오를 만들었습니다.
여기서는 브라우저를 사용하여 데이터를 가져오려는 웹사이트의 코드를 구문 분석하는 방법을 아는 것이 중요합니다. 브라우저 자체가 이 작업에 많은 도움을 주기 때문에 어렵지 않습니다. 그러나 모르는 분은 배워야 합니다. 방법을 이해하면 여러분에게 많은 가능성이 열릴 것입니다.
저는 검색을 위해 Chrome을 사용할 것이지만 개발자 도구를 사용하여 코드에 대한 액세스를 제공하는 다른 브라우저를 사용할 수 있습니다.
우리는 아래 표시된 블록에서 데이터를 얻는 데 관심이 있습니다. 이 블록은 위의 비디오에서 찾고 있던 동일한 블록입니다. 브라우저를 사용하여 항목을 찾는 방법을 아는 것이 정말 중요합니다. 그렇지 않으면 다운로드한 이 모든 정보에서 헤매게 될 것입니다.
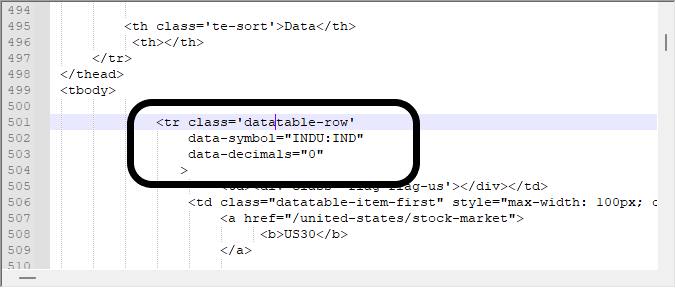
그러나 어떤 경우에는 이러한 방식으로 데이터를 보는 것만으로는 충분하지 않을지 모릅니다. 우리가 무엇을 다루고 있는지 정확히 알기 위해서는 16 진수 편집기를 사용해야 합니다. 어떤 경우에는 데이터 모델링이 상대적으로 단순하지만 데이터가 이미지나 링크 및 기타 항목을 포함하는 경우에는 훨씬 더 복잡할 수 있습니다. 이러한 것들은 일반적으로 거짓 긍정을 제공하기 때문에 검색을 어렵게 만들 수 있으므로 우리가 무엇을 다루고 있는지를 알아야 합니다. 16 진수 편집기에서 동일한 데이터를 찾으면 다음과 같은 값을 얻게 됩니다.
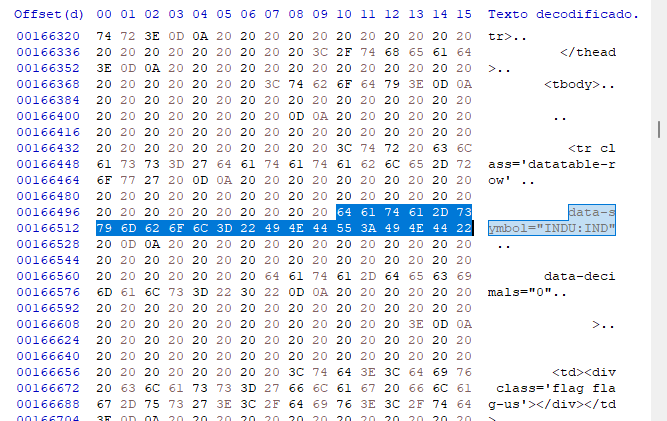
동적 페이지의 경우 변경될 수 있으므로 이 첫 번째 단계에서 오프셋을 신경 쓸 필요 없지만 어떤 종류의 모델링이 사용되는지는 흥미롭습니다. 이 경우 매우 명확하며 이 16진수 편집기에서 찾을 수 있는 이러한 유형의 정보를 기반으로 검색 시스템을 사용하면 됩니다. 이렇게 하면 처음에는 효율적인 시스템이 아니더라도 프로그램에서 검색을 구현하기가 더 간단해 집니다. 검색 데이터베이스는 액세스하기가 더 쉽습니다. - 우리는 입력을 사용하고 CARRIAGE 또는 RETURN과 같은 추가 문자를 사용하지 않습니다. 따라서 프로그램 코드는 다음과 같습니다.
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks")); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 100) { string headers, szInfo; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; szInfo = ""; for (int c0 = 0, c1 = ArraySize(charResultPage); c0 < c1; c0++) szInfo += CharToString(charResultPage[c0]); if ((handle = StringFind(szInfo, "data-symbol=\"INDU:IND\"", 0)) >= 0) { handle = StringFind(szInfo, "<td id=\"p\" class=\"datatable-item\">", handle); for(; charResultPage[handle] != 0x0A; handle++); for(handle++; charResultPage[handle] != 0x0A; handle++); szInfo = ""; for(handle++; charResultPage[handle] == 0x20; handle++); for(; (charResultPage[handle] != 0x0D) && (charResultPage[handle] != 0x20); handle++) szInfo += CharToString(charResultPage[handle]); } return szInfo; }
스크립트가 하는 것은 페이지의 값을 캡처하는 것입니다. 위에 표시된 방법의 장점은 오프셋으로 인해 정보의 위치가 변경되더라도 모든 명령 중에서 정보를 여전히 찾을 수 있다는 것입니다. 그러나 모든 것이 이상적으로 보이더라도 정보에 약간의 지연이 있습니다. 그러므로 위의 스크립트가 실행될 때 캡처된 데이터로 어떻게 작업할지를 정해야 합니다. 실행 결과는 아래에서 볼 수 있습니다.
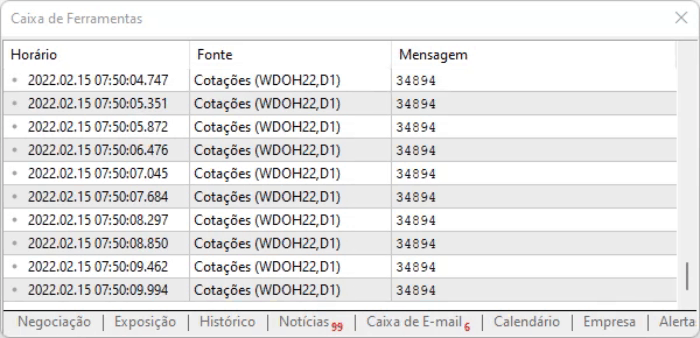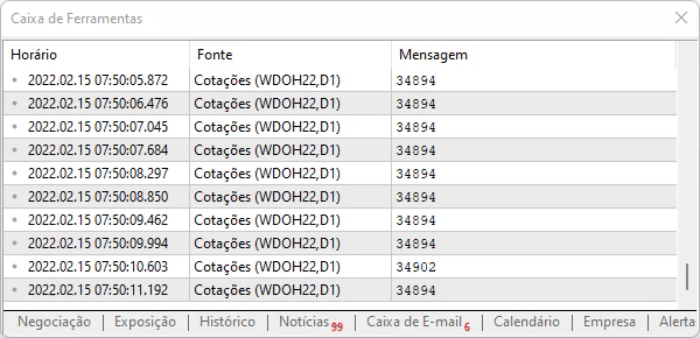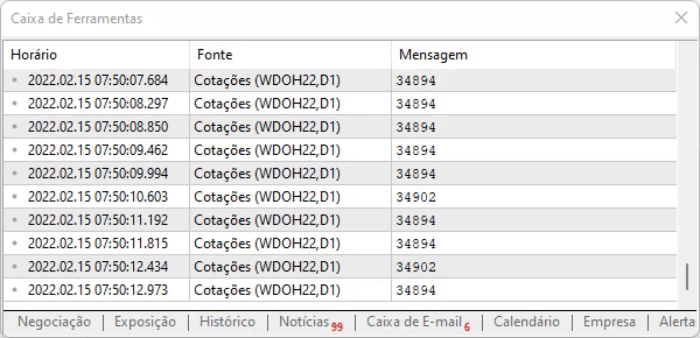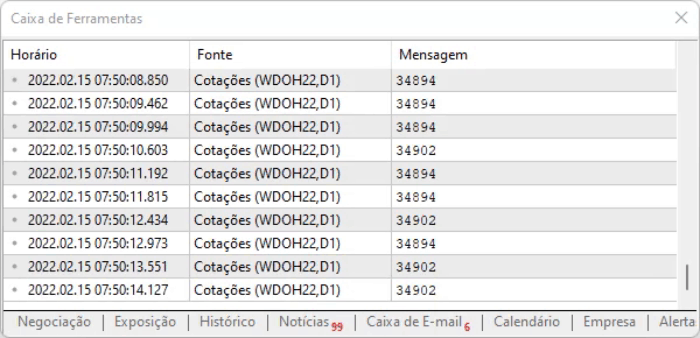
텍스트 형식으로 설명하기 쉽지 않은 세부적인 사항을 아는 것이 중요하기 때문에 여러분 스스로 분석하고 정보가 어떻게 기록되는지를 확인하는 것이 좋습니다.
이제 아래 내용에 대해 생각해 봅시다. 위의 스크립트는 정적 모델이 있는 페이지를 사용할 때 실제로는 필요하지 않은 부분적인 조작을 하기 때문에 실행 측면에서 그다지 효율적이지 않습니다. 그러나 우리가 만들려는 페이지의 경우와 같이 동적 콘텐츠에는 사용됩니다. 이러한 경우에는 오프셋을 사용하여 더 빠르게 구문을 분석하고 데이터를 좀 더 효율적으로 캡처할 수 있습니다. 시스템이 몇 초 동안 정보를 캐시에 보관할 수 있음을 기억하십시오. 따라서 캡처되는 정보는 브라우저에서 관찰되는 데이터와 비교할 때 최신 정보가 아닐 수 있습니다. 이 경우 이를 수정하기 위해 시스템에서 내부적인 조정이 필요합니다. 그러나 이는 이 글의 목적이 아닙니다.
따라서 검색을 수행하기 위해 오프셋을 사용하여 위의 스크립트를 수정하면 다음과 같은 코드를 얻게 됩니다. 전체 내용은 아래에 나와 있습니다.
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo; }
그러면 스크립트 실행 결과를 더 자세히 볼 수 있습니다. 보그 변경은 없고 오프셋 모델을 적용하여 계산 시간을 단축한 것 뿐입니다. 이 모든 것이 전체 시스템의 성능을 다소 향상시킵니다.
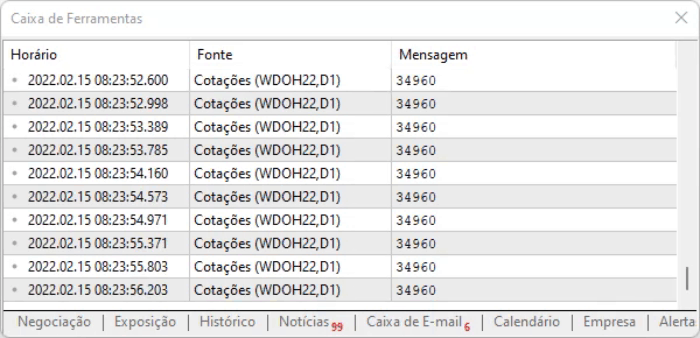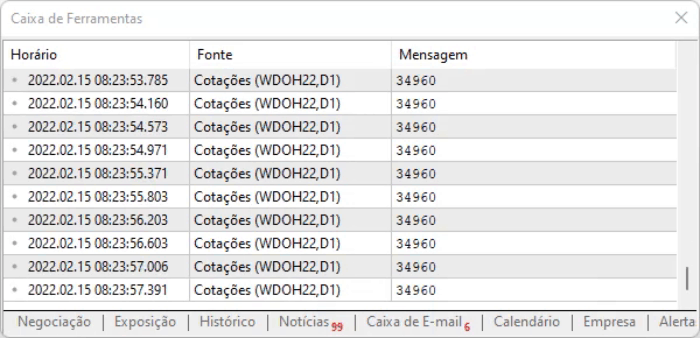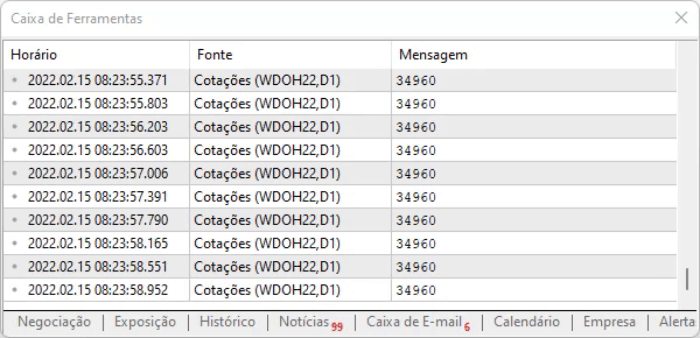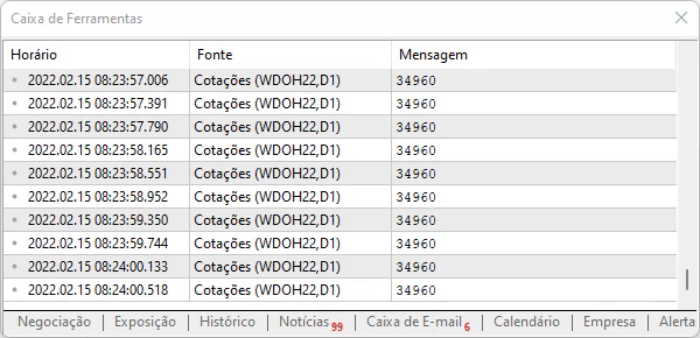
위의 코드는 페이지에 정적 모델이 있기 때문에 작동했다는 점에 유의하십시오: 콘텐츠가 동적으로 변경되었지만 디자인은 변경되지 않았으므로 16진수 편집기를 사용하여 정보의 위치를 조회하고 오프셋 값을 가져올 수 있습니다. 그리고 이러한 위치로 바로 이동합니다. 그러나 오프셋이 여전히 유효한지 확인하기 위해 다음 줄에서 수행되는 간단한 테스트를 수행합니다:
for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position";
이것은 매우 간단하지만 오프셋을 기반으로 캡처되는 정보에 대한 최소한의 보안을 유지하기 위해 필요합니다. 이를 위해서는 페이지를 분석하고 오프셋 메서드를 사용하여 데이터를 캡처할 수 있는지 확인해야 합니다. 그것이 가능하다면 처리 시간을 단축할 수 있습니다.
1.0.3. 해결해야 할 문제
시스템이 잘 작동하는 경우가 많지만 서버에서 다음과 같은 응답을 받는 경우가 있습니다.
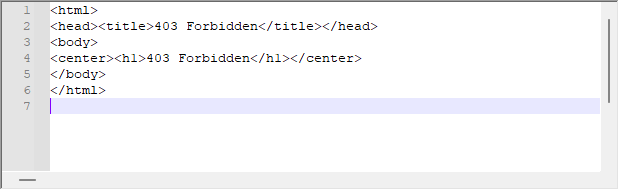
이것은 우리의 요청에 대한 서버 응답입니다. WebRequest가 플랫폼 측에서 오류를 나타내지 않더라도 서버는 이 메시지를 반환할 수 있습니다. 이 경우 반환 메시지의 헤더를 분석하여 문제가 왜 발생하는지를 이해해야 합니다. 이 문제를 해결하려면 아래에 있는 오프셋 스크립트를 약간 변경해야 합니다.
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "<!doctype html>", 2, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szTest, int iTest, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1 return "Bad"; for (int c0 = 0, c1 = StringLen(szTest); c0 < c1; c0++) if (szTest[c0] != charResultPage[iTest + c0]) return "Failed"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo;
강조 표시된 줄에서 테스트가 수행됩니다. 서버에서 반환된 메시지가 더 복잡할 때 이 테스트를 수행한다는 사실만으로도 우리가 분석하고 있는 데이터에 대한 충분한 안전 마진을 이미 보장할 수 있기 때문입니다. 시스템이 이전 코드에 이미 존재하는 첫 번째 테스트를 통과하는 경우 팬텀 데이터 또는 메모리 가비지 분석을 하지 않도록 해 줍니다. 이런 일은 거의 발생하지 않지만 일어날 가능성을 과소평가해서는 안 됩니다.
결과가 다르지 않다는 것을 아래에서 확인할 수 있습니다. 이는 시스템이 예상대로 작동하고 있음을 의미합니다.
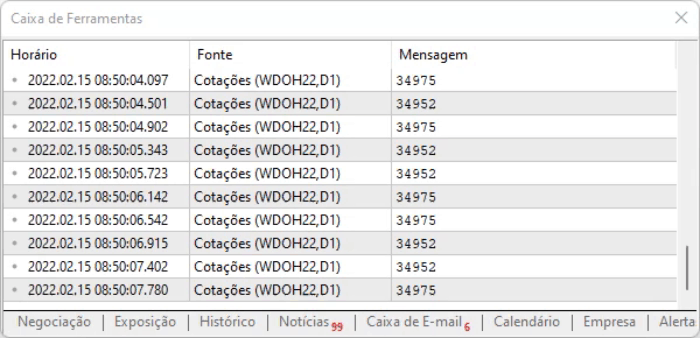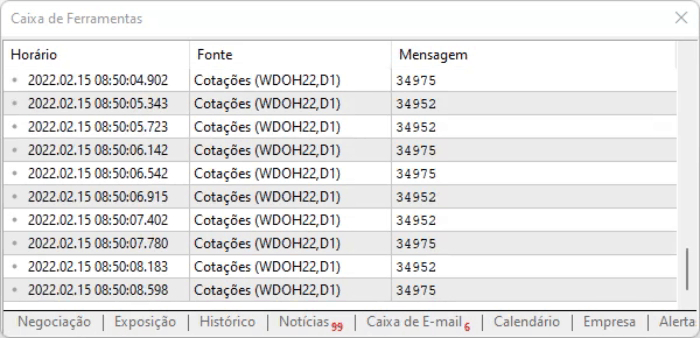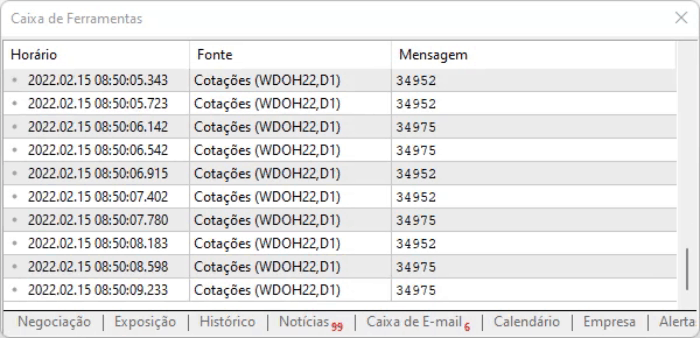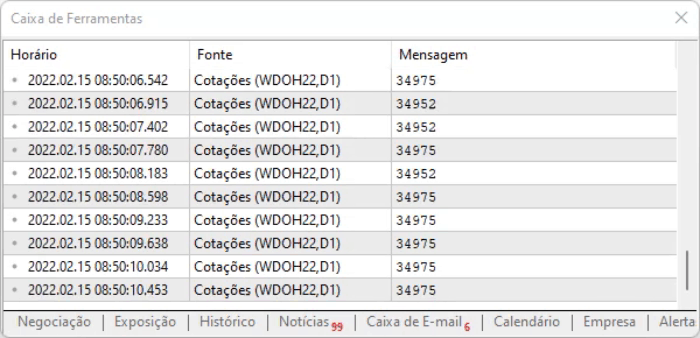
지금까지 우리는 많은 작업을 하지는 않았습니다. - 우리는 웹 페이지에서 값을 읽는 것일 뿐이며 그것이 어떻게 수행되는지를 이해하고 지켜 보는 것이 꽤 흥미롭기는 하지만 그다지 유용하지는 않습니다. 하지만 실제로 거래를 하려는 트레이더들에게는 그다지 유용하지 않습니다. 트레이더들은 지금 이 순간부터 모델링을 하게 될 정보를 캡쳐 해서 다른 방식으로 보여주려 하기 때문입니다. 따라서 우리는 더 넓은 시스템적 측면에서 의미가 있도록 무언가를 해야 합니다. 우리는 이 캡처된 정보를 EA로 가져갈 것입니다. 이렇게 하면 훨씬 더 인상적인 일을 할 수 있고 MetaTrader 5를 놀라운 플랫폼으로 만들 수 있습니다.
결론
자, 아직 끝이 아닙니다. 다음 기사에서는 WEB에서 수집한 이 정보를 EA로 가져오는 방법을 보여줄 것입니다. 이것은 정말 인상적인 작업일 것입니다: MetaTrader 플랫폼 내에서 거의 사용되지 않는 리소스를 사용해야 합니다. 그러므로 이 시리즈의 다음 기사를 놓치지 마십시오.
기사에 사용된 모든 코드는 아래에 첨부되어 있습니다.
MetaQuotes 소프트웨어 사를 통해 포르투갈어가 번역됨
원본 기고글: https://www.mql5.com/pt/articles/10430
 일목균형 지표로 트레이딩 시스템을 설계하는 방법 알아보기
일목균형 지표로 트레이딩 시스템을 설계하는 방법 알아보기
 MFI로 거래 시스템을 설계하는 방법 알아보기
MFI로 거래 시스템을 설계하는 방법 알아보기
 Williams PR로 트레이딩 시스템을 설계하는 방법 알아보기
Williams PR로 트레이딩 시스템을 설계하는 방법 알아보기
 Expert Advisor 개발 기초부터 (파트 14): 가격에 볼륨 추가 (II)
Expert Advisor 개발 기초부터 (파트 14): 가격에 볼륨 추가 (II)