
Sistema secuencial de Tom DeMark (TD SEQUENTIAL) con uso de inteligencia artificial

1. Introducción
Los sistemas de inteligencia artificial envuelven de telaraña la vida cotidiana de las personas. Los traders fueron unos de los primeros en instrumentalizar estos sistemas. Yo propongo discutir sobre cómo se puede utilizar un sistema de la inteligencia artificial a base de las redes neuronales en el trading.
Primero, vamos a aclarar que una red neuronal no es capaz de tradear por sí misma. Es decir, si la tenemos, podemos «alimentarla» con el precio, indicadores y con otras cositas sabrosas cuanto queramos, pero no conseguiremos de ella ningún resultado final, se puede abandonar esta idea desde el principio. La red neuronal sólo pude «acompañar» a la estrategia, o sea, «servirle»: ayudar a tomar decisiones, filtrar, pronosticar. La red neuronal que por sí misma representa una estrategia hecha es un non-sens (por lo menos, yo las he visto).
En este artículo voy a contar sobre cómo se puede tradear con éxito aplicando la «hibridación» de una estrategia muy famosa y una red neuronal. Se tratará de la estrategia de Tom DeMark «Sistema secuencial» (TD Sequential), con aplicación de la inteligencia artificial. El «TD Sequential» está muy bien descrito por DeMark en su libro «El análisis técnico: nueva ciencia», que será muy útil para cualquier trader. Para familiarizarse con su trabajo, se puede usar, por ejemplo, este enlace.
Primero, diremos algunas palabras sobre la estrategia. La metodología «TD Sequential» es una estrategia contratendencial. Las señales que aparecen en ella no dependen una de otra. En otras palabras, las señales de compra y de venta pueden llegar seguidamente, lo que complica considerablemente el uso del «Sistema secuencial». Como cualquier estrategia, ella incluye señales falsas, las que vamos a buscar. El principio de la construcción de la señal según el «TD Sequential» está bien descrito por el autor, pero nosotros introduciremos pequeñas modificaciones en su interpretación. Nosotros vamos a trabajar SÓLO con la primera parte de la estrategia, usando las señales «Disposición» y «Intersección». Las he elegido por dos razones: primero, estas señales se encuentran en los piques y los valles; segundo, aparecen con más frecuencia que las señales «Cuenta atrás» y «Entrada».
Quiero hacer reservas desde el principio: la estrategia comercial para insertar la inteligencia artificial puede ser absolutamente cualquiera, incluso una intersección habitual de la MA. En cualquier caso, lo importante en cada estrategia será el momento de toma de la decisión. La cosa es que el analizar cada barra es una utopía, y por eso hay que determinar en qué momentos y en qué barras nosotros vamos a estudiar la situación en el mercado. Precisamente para eso nos sirve la estrategia comercial. Me repito, no importa en absoluto cuáles sean los métodos del análisis (desde la intersección de la MA hasta las construcciones fractales), lo importante para nosotros es recibir una señal. En nuestro caso, en el «TD Sequential» nos interesa la ventana de puntos verdes durante la que vamos a determinar el comportamiento del mercado y hacer conclusiones sobre la veracidad y la falsedad de esta señal.
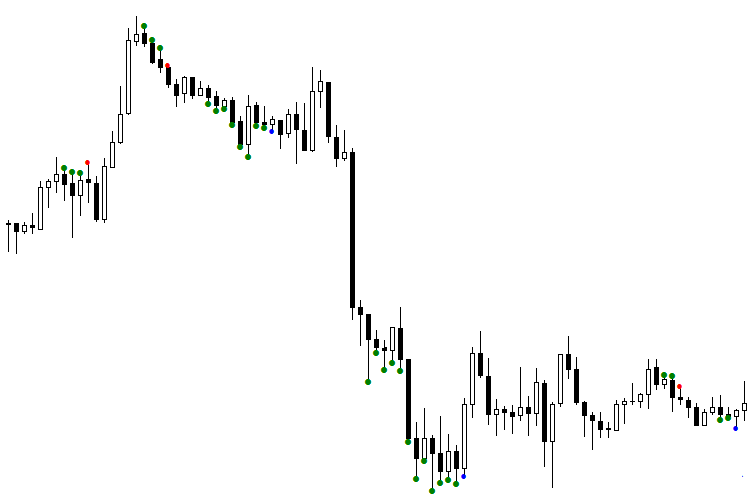
Fig. 1. Indicador TDSEQUENTA by nikelodeon.mql5
Vamos a analizar el trabajo de la estrategia comercial «TD Sequential» sin usar la red neuronal. En la imagen se puede observar la aparición de puntos verdes. Aquí se muestra la versión adaptable de la construcción de la estrategia, es decir, cuando no cogemos una determinada cantidad de barras (por ejemplo, 9 barras seguidas), sino mientras vaya cumpliéndose la condición. En cuanto la condición de la construcción deje de cumplirse, aparece una señal. De esta manera, cada señal aparece después de su propio número de puntos, dependiendo del comportamiento actual del mercado. Precisamente aquí ocurre la adopción del «TD Sequential» al mercado. Este efecto da la posibilidad de seleccionar para el análisis la ventana que se compone de puntos verdes. Esta ventana tiene una duración diferente para cada señal. Al usar la inteligencia artificial (IA), eso supone una determinada ventaja. He seleccionado los siguientes colores: el punto azul tras los puntos verdes significa una señal de compra, el rojo, de venta.
Vemos que la primera señal de compra (punto rojo) fue falsa, porque la siguiente señal estuvo por encima de ella. Con estar trabajando de señal a señal, si entráramos en el mercado por este punto rojo, perderíamos sin falta los fondos. El primer punto azul también nos engañó: si compráramos según este punto, sufriríamos unas pérdidas considerables. ¿Pues cómo se puede separar las señales en falsas y verdaderas? En eso nos ayudará la inteligencia artificial, para ser más exacto, la red neuronal (RN).
2. Contexto del mercado
Anteayer su sistema de trading funcionaba perfectamente. Ayer fue de mal en peor. Hoy es una molestia llevadera. ¿Conoce esta situación? Desde luego, cada trader se encuentra con la situación cuando la calidad de trabajo del sistema comercial cambia de día en día. Aquí no se trata del sistema en sí. La culpa tiene así llamado el contexto del día de trading. Se forma a base del cambio anterior del volumen de la negociación, interés abierto y el cambio del precio. Hablando más claro, el fondo del trading se determina precisamente por estos datos, que en el momento del cierre de cada sesión son diferentes. Así, llegamos a una recomendación importante: por favor, optimice sus robots durante los días con condiciones semejantes a los días cuando ellos van a tradear. El problema más complicado a la hora de optimizar una red neuronal es hacer que los patrones que serán formados durante el día actual entren en la muestra de aprendizaje. Uno de los modos de esta entrada es el «Contexto del día».
Vamos a ver un ejemplo. Supongamos que hoy el volumen del trading y el interés abierto han caído, mientras que la cotización ha subido. Al paso que van las cosas, el mercado se hace débil y estamos a la espera de una reversa hacia abajo. Después de entrenar la red neuronal SOLAMENTE en estos días, cuando el volumen y el interés abierto se reducían con el crecimiento simultáneo de la cotización, nosotros pondremos con mayor probabilidad en la entrada de la RN los patrones que tenemos la posibilidad de ver durante el día. Es decir, resulta que la RN se ha entrenado de acuerdo al «Contexto del mercado». Lo más probable que la reacción del mercado sea la misma que el día con los parámetros semejantes. No es difícil de calcular que las opciones globales de la combinación del volumen, precio y el interés abierto son nueve. Al entrenar la red para cada contexto separadamente, abarcaremos todo el mercado. En promedio, nueve modelos entrenados trabajan unas dos semanas, en algunas ocasiones, más tiempo.
Es muy fácil organizar el trabajo según el contexto usando el indicador eVOLution-dvoid.1.3 (1). En realidad, este indicador lee los datos del archivo csv ubicado en el directorio ...\Files\evolution-dvoid\dvoid-BP.csv. Como vemos, aquí se utiliza la cotización de la libra esterlina en relación al dólar estadounidense. Para mostrar los datos correctamente y luego poder usarlos precisamente en el contexto del día, es necesario visitar la web de la Bolsa de valores de Chicago cada mañana, aproximadamente a las 7:30 hora de Moscú. Ahí, descargamos el boletín diario (para la libra es el boletín 27) en el que se indica el volumen y el interés abierto para el momento del cierre del día de ayer. Cada día antes de la sesión de trading, introducimos estos datos en el archivo "dvoid-BP.csv", y en el transcurso del día el indicador va a mostrar el cambio del volumen en comparación con el valor anterior. Es decir, no nos interesa el valor real del volumen de mercado, sino su cambio. Lo mismo ocurre con el interés abierto: importa su movimiento relativo.
3. Enfoque sobre el modelo de organización
Para aumentar la muestra de aprendizaje y garantizar el nivel debido de la generalización, vamos a introducir una condición importante. Vamos a dividir las señales en verdaderas y falsas para la compra y la venta por separado. De esta manera, los recursos de la RN no van a gastarse para el ordenamiento de señales. Nosotros mismos separaremos estas señales y construiremos dos modelos: un modelo se encargará de las señales de compra, otro, de las señales de venta. De esta simple manera, doblaremos el tamaño de la futura muestra de aprendizaje. Además, se sabe que cuanto más grande sea la muestra de aprendizaje y cuanto más alto sea el nivel de generalización, este modelo será adecuado al mercado más tiempo.
Introduciremos el concepto intervalo de confianza: es un intervalo durante el que nosotros confiamos en el modelo y lo consideramos apto para el uso. Supongamos que el intervalo de confianza para el modelo calculado es 1/3 del intervalo del aprendizaje. O sea, después de entrenar el modelo en 30 señales, suponemos que el período de su trabajo adecuado será de 10 señales. Sin embargo, los casos cuando el modelo trabaja durante un período tres veces más duradero que el intervalo de aprendizaje tampoco es una singularidad.
Se ha notado (y es absolutamente natural) que cuando el intervalo de aprendizaje se aumenta, la capacidad generalizadora del modelo se disminuye. Eso confirma la teoría de que los Griales no existen. Es que si imaginamos que hemos podido entrenar a una RN abarcando el historial completo, con el 100% del nivel de generalización, conseguiríamos un modelo ideal que funcionaría siempre. Pues, la práctica demuestra que es una utopía. No obstante, un buen modelo que juega a la larga si que lo podemos construir. El secreto se oculta en los datos que se ponen en la entrada de la red. Si ellos reflejan la esencia de la variable de salida y sirven de la causa para ella, no será difícil de construir el modelo.
Por cierto, hablando de la variable de salida. Su selección es igual de difícil que la búsqueda de los datos de entrada para construir una red. Observando los datos históricos de las señales, podemos identificar exactamente cuál de ellas ha sido verdadera y cuál ha sido falsa. Generalmente, al construir una variable de salida, interpretamos unívocamente cada señal, haciendo que la salida de la red sea perfecta. Es decir, en nuestra salida no hay errores, y eso empuja a la RN a tender a las mismas salidas perfectas durante el aprendizaje. Naturalmente, así es prácticamente imposible conseguir un modelo con nivel de generalización de 100% para un intervalo largo. Es que es poco probable que se encuentren los datos que podrían interpretar sin falta las señales de la variable de salida durante un tiempo prolongado. Es más, su presencia reduce por completo la necesidad de usar la RN.
Por eso, es necesario formar la variable de salida con unos pequeños errores, cuando las pequeñas pérdidas por causa de las señales se cubran con unos beneficios importantes. Como resultado, tenemos una variable de salida que no es ideal pero dispone del potencial de aumentar el depósito. En otras palabras, los errores producen pequeñas pérdidas que se cubren crecidamente con otras señales rentables. Eso da la posibilidad de obtener un modelo con alto nivel de generalización respecto a la variable de salida. En este caso es muy importante que sabemos el grado del error de este modelo. Por consiguiente, la confianza en la señal va a contener este ajuste.
Y por último, el momento más importante durante la construcción de modelos es la elección de la carga semántica sobre la variable de salida. Por supuesto, en primer lugar recordaremos el beneficio. Vamos a marcar las señales rentables en el pasado con 1, y las de pérdidas, con 0. Sin embargo, existe un montón de otras variables semánticas para la salida que van a proporcionar una valiosa información sobre el mercado. Por ejemplo, ¿habrá un retroceso después de la señal, se producirá algún beneficio, será alcista o bajista la barra que sigue la señal? Así que podemos asignar el significado a la variable de salida en sentidos diferentes, y con eso se utilizan los mismos datos de entrada. De esa manera, conseguimos la información más completa sobre el mercado, y si varios modelos confirman uno a otro, la posibilidad del beneficio se aumenta.
He visto con frecuencia a los traders intentar obtener 100 y más señales en un intervalo largo. Pues, yo no comparto esta ambición. En mi opinión, para ganar, serán suficientes 10-15 señales, pero su error no debe superar a un 20%. Eso está relacionado con el hecho de que si dos señales de diez dan la pérdida máxima, nos quedarán ocho señales correctos. Por lo menos dos de ellas nos traerán una ganancia que cubre la pérdida.
¿Entonces, cómo podemos hacer un modelo que trabaje durante un tiempo bastante largo? Por ejemplo, estamos interesados en un trabajo estable del sistema en 5M durante una o dos semanas, tendríamos un buen resultado si se trabaja sin re-optimización. Supongamos que nuestro indicador principal, nuestro sistema de trading principal (en nuestro caso se trata del «TD Sequential») nos da una media de 5 señales al día. Para cada uno de nueve modelos del contexto de mercado, vamos a coger 10 señales. Tenemos cinco sesiones de trading en una semana. Es decir, resulta que algunos modelos se quedaran sin funcionar, y otros sí. Como muestra la práctica, un modelo funciona no más de dos veces a la semana, y muy raramente, tres veces. Por tanto, un sistema de trading generalizado va a trabajar incluso más de una semana, teniendo en cuenta el intervalo de confianza en el período fuera de la muestra de 10 señales.
4. Teoría de redes neuronales
Ahora, pasaremos a la teoría de redes neuronales. ¿Seguramente Usted haya pensado que voy a enseñarle las topologías, denominaciones y métodos de aprendizaje? Pues, se equivoca.
Vamos a hablar de lo siguiente. Hay dos tendencias en el uso de las redes neuronales de topologías diferentes. Una de ellas es de previsión y la otra es de clasificación.
La red de previsión da el valor futuro de la variable de salida. Se considera que aparte de la dirección de la cotización (arriba o abajo), ella emite también el grado de esta dirección. Por ejemplo, ahora la cotización del euro se fija en 1,0600, y la red muestra que dentro de una hora el cambio subirá a 1,0700 —es decir, ella predice estos 100 puntos adicionales. Quiero mencionar desde el principio que no comparto este enfoque en las redes neuronales, ya que el futuro no está definido. Personalmente para mí, este argumento filosófico es suficiente para rechazar este método de trabajo con redes neuronales. Desde luego, yo entiendo que es una cuestión del gusto, y para ser justo diré que las redes de previsión cumplen bien con las tareas planteadas.
No obstante, yo utilizo las redes de clasificación. Ellas nos dan una idea sobre el estado actual del mercado, y cuanto más precisas sean nuestras definiciones, mejor será nuestra negociación. La recepción de la respuesta de la red, en ambos casos nos lleva a realizar alguna acción. En primer caso, compramos en el punto 1,0600 y vendemos cuando el precio alcanza 1,0700. En segundo caso, simplemente compramos y salimos de la operación en la siguiente señal, pero no podemos predecir en qué nivel del precio ocurrirá eso.
Para revelar la esencia de este enfoque, voy a contar un chiste. Un día, al campeón del mundo Garry Casparov le preguntaron a cuántos movimientos pensaba por delante durante el partido mientras planteaba la siguiente jugada. Todos pensaban que Casparov iba a decir una cifra enorme. Sin embargo, lo que dijo el ajedrecista confirmaba que no todo el mundo siquiera entendía la esencia del juego: «La cosa más importante en el ajedrez no consiste en cuántos movimientos adelante vas pensando, sino en qué bien estás analizando la situación actual». Lo mismo ocurre en el mercado de divisas: para entender la esencia del juego, no es necesario mirar a varias barras adelante. Basta con definir el estado actual del mercado en un determinado momento y hacer un movimiento correcto.
Precisamente esta ideología es congenial para mí, pero repito que se trata de una cuestión del gusto. Las redes neuronales de previsión también son muy populares, y no se puede negarles el derecho a la existencia.
5. Organización interna del sistema de inteligencia artificial
Junto con dos enfoques para la construcción y el uso de las redes neuronales (previsión y clasificación), en este campo hay dos tipos de especialistas: desarrolladores de los sistemas de IA y sus usuarios. Estoy seguro de que Stradivari tocaba muy bien sus violines, pero no adquirió fama como un gran virtuoso. Sin duda alguna, el creador de un instrumento sabe usarlo, pero no siempre el maestro es capaz de descubrir todo el potencial de lo que ha creado. Por desgracia, no he conseguido ponerse en contacto con el autor del optimizador que se adjunta aquí, es que no responde a mis mensajes. No obstante, es conocido por muchos frecuentadores del foro. Se trata de Yuri Rechetov.
He usado su enfoque en el trabajo, y como resultado de la comunicación con él, he aclarado la estructura interna del optimizador sobre la que me gustaría contar a Ustedes. Espero que el autor no tenga nada en contra: ya que el producto fue publicado como un código abierto. Yo, como usuario de los sistemas de IA, no tengo que entender necesariamente el código del programa, pero es necesario conocer la estructura interna del optimizador. Me fijé precisamente en este producto, en primer lugar porque en el optimizador se utilizaba el método de aprendizaje diferente de los métodos clásicos. El talón de Aquiles durante el aprendizaje de las redes neuronales es su reentrenamiento. Es prácticamente imposible detectar si ha tenido lugar y cuál es su grado. En el optimizador de Rechetov se utiliza otro enfoque: es imposible volver a entrenar la red, sólo se puede no entrenarla de todo. Este enfoque permite evaluar la calidad del entrenamiento de la red expresada en por cientos. Tenemos el límite superior del aprendizaje de 100% al que aspiramos (es complicado alcanzar este resultado). Después de entrenar la red, digamos a un 80%, sabremos que en 20% de ocasiones la red saltará un error, y podremos estar preparados para eso. Esta es una de las principales ventajas del método.
El resultado del trabajo del optimizador es el archivo con el código. Ahí se ubican dos redes, cada una de las cuales representa una ecuación no lineal. En cada una de las funciones, primero se utiliza la normalización de los datos que luego llegan a la entrada de la ecuación no lineal. Para aumentar la capacidad de generalización, fue implementado el «círculo» de dos redes. Si las dos dicen un «sí», la señal es verdadera, si las dos dicen un «no», la señal es falsa. Si las lecturas de las redes se diferencian, obtenemos la respuesta «no sé». Obsérvese que en el pasado no existe el estado «no lo sé», porque en los datos pasados siempre podemos determinar cuál fue la señal. De esta manera, aquí «no sé» supone la existencia simultánea de la posibilidad de una señal falsa y verdadera. Obtenemos un cierto traspaso de los cálculos bidimensionales a los cuánticos. Como analogía, podemos dar un ejemplo con el cúbit (bit cuántico): puede adquirir los valores 1 y 0. Lo mismo pasa con «no sé», esta respuesta puede ser un 1 o un 0 en las páginas del historial. Más tarde hablaremos de un pequeño truco oculto aquí, y el que vamos a usar en la negociación.
Procedemos a la preparación de los datos. Los datos están representados en forma de una tabla Excel. Las columnas serán las entradas de la red. La última columna es la variable de salida. De acuerdo con su objetivo, en esta columna se escriben unos y ceros. En mi caso, la señal que obtiene una ganancia se marca con 1, y la que obtiene una pérdida, 0. Las filas de esta tabla son los datos que guardamos en el momento de la llegada de la señal. Al ser cargada en el optimizador, la tabla se divide en dos muestras: una de aprendizaje y otra de prueba, con particularidad de que dos redes se entrenan de forma cruzada. Pero el cálculo y la optimización se realizan con el círculo de estas redes. De esta manera, el aprendizaje de cada red se realiza por separado, pero tomando en cuenta el resultado común.
Al final de esta sección quiero subrayar que no importa el sistema de IA o el entorno de programación que se utiliza. Incluso el perceptrón más primitivo puede ser entrenado con el método de retropropagación de errores, y no volver a entrenarlo gracias a unos buenos datos en la entrada de la red. La cuestión no consiste en el sistema de IA, sino en la calidad de los datos utilizados. Precisamente por esta razón, los datos primero se normalizan en el optimizador, y luego todo se pasa en una ecuación no lineal muy común. Y si los datos de entrada son la razón para la variable de salida, esta ecuación simple con unas 20 coeficientes le dará en breve 10 señales con el error de 20%. Se ha notado repetidamente que cualquier transformación del precio provoca un retardo. Por tanto, como regla, cualquier indicador muestra un retardo, lo que influye en el trabajo de los sistemas de IA. En el siguiente artículo hablaremos con más detalles sobre las variables de entrada y de salida.
6. TD «Sequential» y RN
Ahora pasamos al uso práctico de la teoría descrita.
Realizamos el análisis en la sección del trading real. Las flechas azules van a demostrar el trabajo de la RN. Cuando la flecha muestra hacia abajo en un punto rojo, eso significa que la señal de venta es verdadera, cuando la flecha muestra hacia arriba, es falsa. Si no hay flecha, obtenemos la respuesta «No sé». Con las señales de compra (punto azul) todo pasa al revés: la flecha hacia arriba, la compra es verdadera, la flecha hacia abajo, es falsa.
Vamos a considerar el trabajo del modelo durante el día. A primera vista, sería difícil de ganar dinero, pero es sólo a primera vista. Aquí el entendimiento de la esencia de la separación llega a nuestra ayuda. Supongamos que tenemos dos señales que se diferencian una de otra. Una de ellas, en opinión de IA, es falsa para la venta, pero en realidad ha sido rentable. Una vez recibida la siguiente señal «falsa» para la venta de parte de IA, es necesario vigilar si ambas señales pertenecen a la misma área de la separación, o si simplemente son iguales. Si es así, para que la señal traiga la ganancia, tenemos que orientar el indicador de tal manera que la flecha apunte en dirección del mercado, es decir en dirección del beneficio de la señal.
Eche un vistazo a la imagen. La primera señal de venta (punto rojo) ha resultado no rentable, pero después de invertir la flecha hacia abajo, ha resultado rentable, porque la señal №2 de venta ha entrado en la misma área con la señal №1. Una vez invertida la flecha, hemos hecho rentable la segunda señal, en la que ya se puede tradear. Ahora vamos a considerar la señal de compra. Como podemos ver, en este caso la IA se ha equivocado de nuevo y ha registrado la señal rentable como la falsa. Sólo nos queda corregir la situación y dar la vuelta a la flecha de la señal №3 para la compra. Como resultado, la señal №4 ha comenzado a apuntar en dirección correcta. Pero la señal №5 ha entrado en otra área distinta de la señal anterior, y ha provocado la vuelta del mercado en su totalidad.
En otras palabras, hemos conseguido un buen antimodelo que genera las pérdidas, después lo hemos invertido y ¡hemos conseguido un modelo rentable! Este método lo llamo «Orientación del modelo». Generalmente, se realiza durante una señal. Basta con esperar la aparición de una señal al comienzo del día para la compra y otra señal para la venta, orientarlos, y se puede ponerse a trabajar. De esta manera, en un día recibiremos como mínimo 3-4 señales. La cuestión no consiste en ver qué señales eran en el pasado y cómo ocurrían. Hay que comparar las dos últimas señales y hacer conclusiones sobre si pertenecen al mismo grupo o no, y qué movimiento hay que hacer si se sabe el resultado de la señal anterior. Al mismo tiempo, no olvidemos de que la red puede saltar errores.
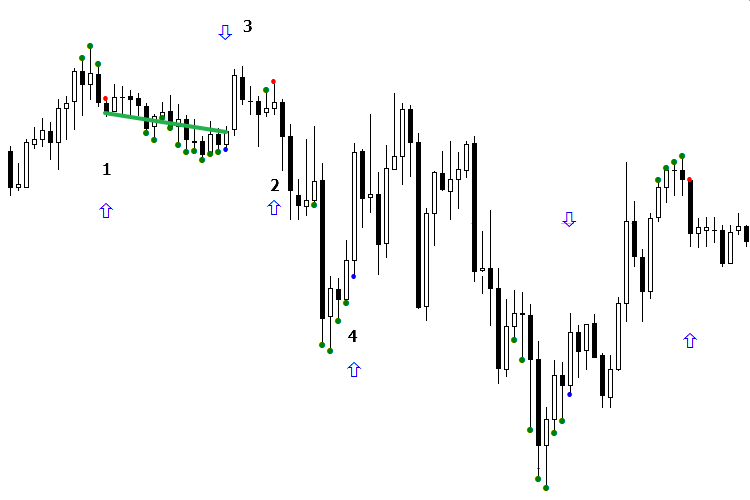
Fig. 2. Indicadores BuyVOLDOWNOPNDOWN.mq5 y SellVOLDOWNOPNDOWN.mq5
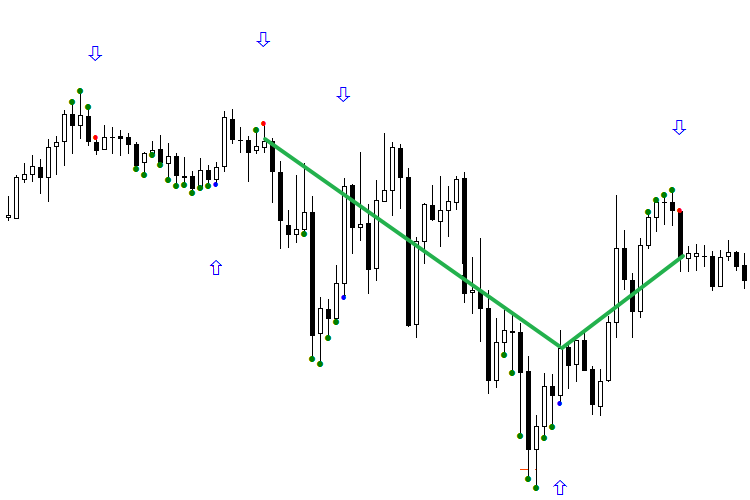
Fig. 3. Indicadores orientados BuyVOLDOWNOPNDOWN.mq5 y SellVOLDOWNOPNDOWN.mq5
Dos últimas imágenes muestran el trabajo de la red para 4 días. Hay que tomar en consideración que sólo la segunda señal diaria va a usarse en el trabajo. Todas las señales rentables están marcadas con línea verde, las no rentables, con línea roja. La primera imagen demuestra el trabajo óptimo de la red, la segunda, con orientación según la primera señal al día. Confórmese conmigo, la primera imagen no causa impresión. Pero si echamos un vistazo a la segunda imagen y comenzamos a procesar las transacciones a partir de la segunda señal de cada día, orientando la estrategia comercial, la imagen se mejorará considerablemente. No olvide que es necesario aplicar la técnica de inversión con mucho cuidado.
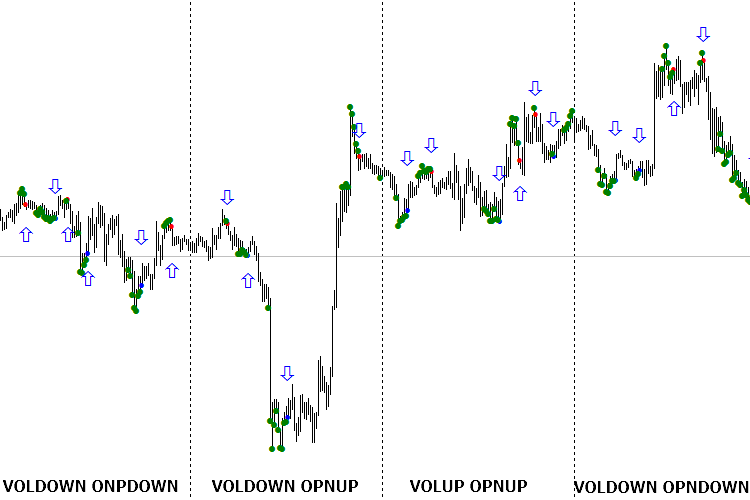
Fig. 4 Indicadores según el nombre para cada día, no orientados en dirección necesaria
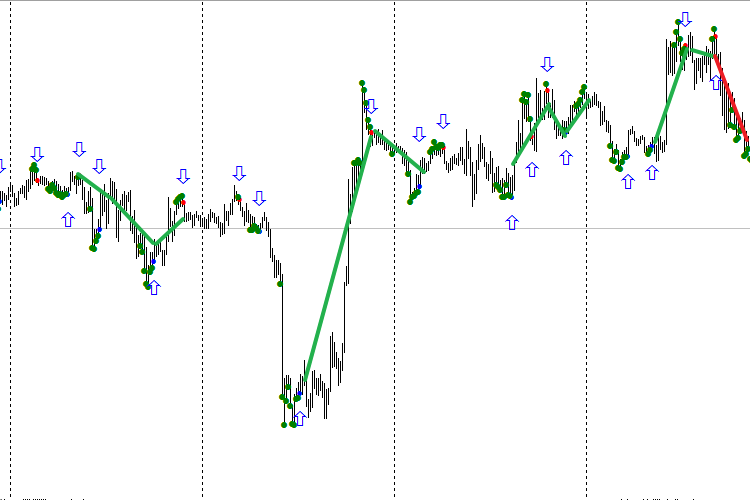
Fig. 5. Indicadores para cada día, orientados según la primera señal diaria (para la compra y la venta por separado)
Así, los modelos ya no parecen un fracaso, más parecen bastante hábiles. Como todavía no han agotado su recurso del intervalo de confianza, creo que su plazo de validez es de algunos días.
La esencia de la clasificación consiste en que el espacio multidimensional de datos está dividido con una línea universal que define las señales en un grupo de «verdaderas» y en un grupo de «falsas». Las señales «verdaderas» se encuentran por encima de cero, las «falsas», por debajo. Lo importante aquí es la estabilidad de separar unas señales de otras. Se introduce el concepto de la orientación de la estrategia comercial (EC). Es importante determinar cuando la red empieza a generar pérdidas de forma estable, mostrando las señales invertidas. Generalmente, en este caso la primera señal del día actúa como guía. Es posible operar usando esta señal, pero con muchísimo cuidado, a base de otros factores del análisis. Mi consejo es el siguiente: para liberar la red de los desequilibrios, procure hacer que el número de 0 y 1 en la variable de salida sea igual. Para la igualación, elimine sin miedo los ceros y unos sobrantes de la muestra de aprendizaje, empezando por las señales más remotas.
No importa como ocurra la división: lo importante es que sea estable. Volvamos a nuestro ejemplo: aún antes de la reorientación hemos obtenido dos errores seguidos en la imagen №2 y hemos aprovechado de la situación. Como vemos, durante el trabajo de Sequential en 15 minutos, recibimos de 2 a 5 señales al día. Si, por ejemplo, dos señales de compra entran en clases diferentes (una es verdadera, otra es falsa), sabiendo el resultado de la señal anterior, la primera, no es difícil de determinar cuál será la actual, falsa o verdadera. Sin embargo, hay que trabajar con mucho cuidado usando el método de orientación. La red puede saltar un error, y luego seguir trabajando de forma correcta. En cualquier caso, todo viene con experiencia, tanto las reacciones automáticas, como la intuición para usar un modelo. En los siguientes artículos yo pretendo aclarar mejor la cuestión sobre la conveniencia del modelo resultante, porque en esta materia hay muchos detalles.
Aspecto organizativo: los archivos adjuntos se refieren a las imágenes que se encuentran arriba. Se puede descargarlas y comprobar en la fecha especificada. La estrategia comercial es insensible a las cotizaciones. Sin embargo, habían casos cuando el «Sistema secuencial» (TD Sequential) no daba la señal para otro bróker porque en el momento clave las cotizaciones eran diferentes. Pero estos casos son muy raros, y los datos de entrada tienen que ser idénticos en todas las corredoras, porque llegan de la misma fuente y no pueden cambiarse. No obstante, no puedo garantizar que después de bajar los archivos adjuntos a su ordenador, podrá obtener el mismo resultado en el mismo período de tiempo. Pero creo que podrá usar los modelos para separar la señal actual de la anterior.
En conclusión de este artículo, vamos a considerar otra cuestión que ya hemos mencionado antes. ¿Qué hacemos cuando la red nos salta la señal «NO SÉ» y qué significa eso? Me repito: en las páginas del historial, el concepto como «no sé» no puede existir en principio. Eso sólo quiere decir que en la muestra de aprendizaje no había este patrón, y las opiniones de las redes en círculo se dividieron sobre este asunto. «NO SÉ» supone que podemos tener delante tanto una señal verdadera, como la falsa. Es muy probable que si tomásemos una parte un poco más grande del historial, el patrón necesario se encontraría y la red podría identificarlo. Pero la profundidad del aprendizaje no es muy grande, unas 30 señales, lo que corresponde aproximadamente a 8-10 días. Claro que periódicamente aparecen las señales que no estaban durante el aprendizaje, modelos desconocidos. Según mis observaciones, cuanto más tiempo trabaja el modelo, con más frecuencia responde «no sé». Eso se encaja bien en la teoría del «mercado vivo», cuando el pasado no significa el futuro. Los patrones recientes pueden repetirse tanto en un futuro cercano, como en un futuro lejano. La esencia del mercado es que la significación de la barra se disminuye gradualmente después de su cierre a medida de que se vaya más al fondo del historial. Es una regla general para cualquier información: cuanto más vieja sea, es menos significativa.
Hay dos soluciones del problema de clasificación del estado «no sé». Veamos la siguiente imagen. Tenemos las señales en las que la ausencia de flechas significa nuestro «no sé», dos redes en círculo las han interpretado de diferentes maneras. En las imágenes, estas señales están marcadas como 1 y 2, además la primera señal tiene que ser falsa, para que se pueda ganar en ella.
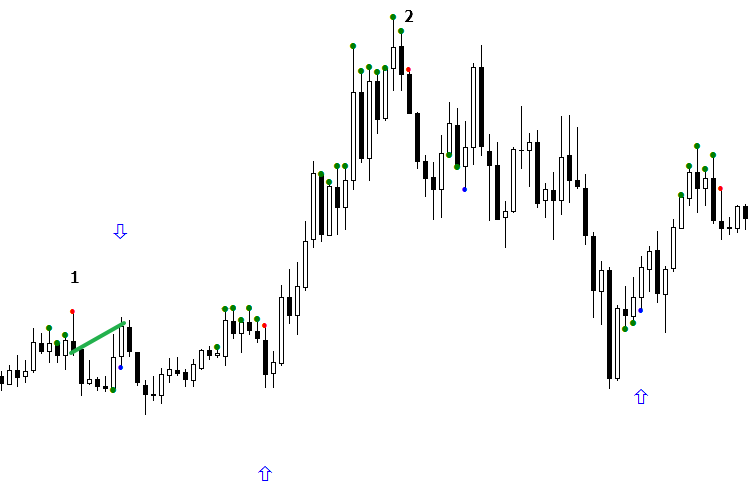
Fig. 6. Método para organizar la orientación de la señal según el contexto del día
Hay dos maneras de clasificar el estado «no sé». La primera manera es muy simple (véase Fig. 7). Determinamos que el estado «no sé» era falso para la primera venta. Es decir, consideramos la señal «no sé» para la venta como falsa. También consideramos que la señal №2 es falsa, suponiendo continuar las compras. En realidad, la red ha cometido un error, pero en la práctica este error puede ser reducido a nada, entrando en el mercado con mejor precio. Por eso, la aparición de la flecha hacia arriba no nos perjudicará mucho, aunque en realidad la señal resulta ser negativa. También consideramos la señal «no sé» de compra (flecha azul) como falsa, porque la última vez durante el estado «no sé» la señal de compra era falsa. Este método es muy antiguo, pero en nuestra experiencia funciona bastante bien.
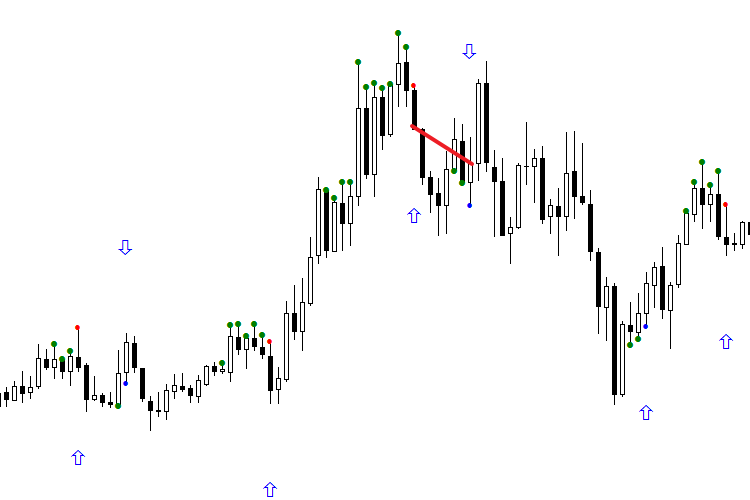
Fig. 7. Clasificación adicional de la señal «no sé» cuando se considera como una clase alternativa
El segundo método de la clasificación del estado «no sé» apela a la organización interna del optimizador y se apoya en su base. Pues, el estado «no sé» surge cuando una red en el círculo muestra 1, otra muestra 0. La esencia del método consiste en que en el círculo nosotros elegimos la red que muestra correctamente. Volvemos a nuestro ejemplo. La señal №1 fue falsa cuando la red A estaba encima de cero, y la red B estaba debajo. Por eso si la red B está encima de cero, y la red A está debajo, este estado «no sé» es verdadero. En caso de la señal de compra, es al revés: la señal anterior (incluso no figura en la imagen) era falsa, cuando la respuesta de la red A era negativa, y de la red B, era positiva. En la señal actual de compra la situación es inversa, por eso suponemos que esta señal es verdadera y la compra es recomendable.
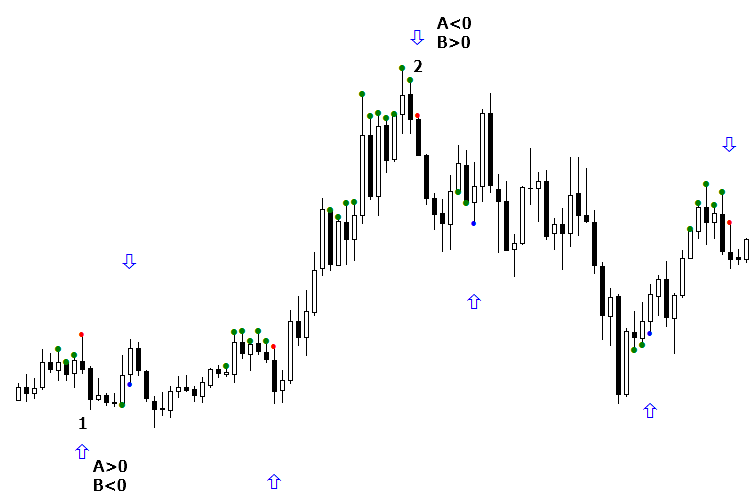
Fig. 8. Clasificación adicional de la señal «no sé» según las indicaciones de cada una de la red del círculo
De dos métodos de la clasificación del estado «no sé» a mí me parece el primero, y eso tiene su lógica explicación. Al usar los círculos de dos redes, obtenemos tres clases: «Sí», «No» y «No sé», nuestros datos se distribuyen en estos tres grupos. Lo importante no es que tenemos tres grupos, sino el hecho de que son absolutamente diferentes. Después de obtener la señal «No sé» y aclarar luego su dirección, creemos que las nuevas señales en este grupo van a tener la misma dirección. La experiencia actual demuestra que este método es más fiable que el segundo.
Es difícil pronosticar los mercados financieros, porque representan un organismo vivo e impredecible donde trabajan personas reales. Entre día, la situación en los mercados puede cambiar de tal modo que nadie puede prever nada, ni los creadores del mercado, ni los traders importantes, ni más aun nosotros mismos. El modo de estos cambios se compone de dos componentes. El primer componente es el contexto del mercado del que ya hemos hablado. El segundo es la actividad de los compradores y vendedores en tiempo real, aquí y ahora mismo. ¡Por eso, lo más importante en el trading es orientarse a tiempo y estar atento!
El uso de la inteligencia artificial no es una panacea ni el Grial. Desde luego, al operar usando las redes neuronales, indudablemente merece la pena escuchar los consejos de la inteligencia artificial. Pero es necesario tradear usando su propia cabeza. Después de recibir una señal de la IA, hay que esperar su confirmación, elegir correctamente el nivel, evaluar la posibilidad del retroceso, etc. Es sobre lo que me gustaría hablar en el tercer artículo que será dedicado a las particularidades prácticas del trading según la estrategia «Sequential» con el uso de las redes neuronales.
7. Conclusión
Otra vez quiero matizar que este artículo es puramente de naturaleza metodológica. Todos los métodos que describo pueden usarse en sus sistemas comerciales, y espero que mis consejos sean útiles para Usted.
Estoy seguro de que habrá gente que tienen argumentos en pro y en contra el método descrito. Si ha llegado a estas líneas, está por lo menos interesado. Me importa mucho su opinión sobre lo que no acepta, sobre todo, si tiene las soluciones constructivas, mejoras y cambios. En otras palabras, ¡critique y proponga! La construcción conjunta de un sistema de inteligencia artificial puede ser la prueba de la capacidad del funcionamiento de este enfoque. Me gustaría trabajar en conjunto con un programador profesional sobre este asunto, y les invito a la colaboración.
Al artículo se le adjunta el código del indicador «TD Sequential», así como los indicadores que filtran o clasifican las señales de compra y de venta tomando en cuenta el contexto del día y la orientación al principio del trading. Debo decir desde el principio que los indicadores han sido reescritos desde el lenguaje MQL4 y no ofrecen la completa funcionalidad para reproducir todo lo que ha sido mostrado en el artículo. La razón es que los datos de entrada para la RN requieren un conjunto de indicadores del proyecto ClusterDelta que están disponibles solamente por la suscripción de pago.
A todos los interesados les estoy dispuesto a proporcionar un archivo listo para el trabajo de los indicadores. Sería interesante reescribir todos los indicadores necesarios en MQL5 para poder repetir completamente el algoritmo de trabajo. Aquí mi propósito era demostrar cómo usar el código abierto para crear y entrenar las redes neuronales en la famosa estrategia comercial de Demark. Estoy dispuesto a escuchar todos los comentarios y responder a las preguntas.
Programas usados en el artículo:
| # | Nombre |
Tipo |
Descripción |
|---|---|---|---|
| 1 | TDSEQUENTA_by_nikelodeon.mq5 | Indicador | La estrategia base que da las señales de compra o de venta en forma de puntos azules y rojos, respectivamente. Los puntos verdes significan que las condiciones para la formación de señal están creadas y es necesario esperar la aparición de la propia señal. La estrategia es conveniente porque el trader está listo para la aparición de la señal: el punto verde le avisa de eso. |
| 2 | eVOLution-dvoid.1.3 (1).mq5 | Indicador | Carga el archivo de texto con los datos sobre el volumen y el interés abierto para los días anteriores, calcula la diferencia entre los datos e introduce todo eso en el búfer de indicador para la futura referencia al guardar los datos, así como al seleccionar el modelo que debe trabajar hoy. En otras palabras, organiza el contexto del mercado. |
| 3 | dvoid-BP.csv | Archivo de texto |
Sirve para registrar la información sobre el volumen e interés abierto cada mañana a las 7:30 desde la web de la Bolsa de valores de Chicago. El registro de datos se realiza manualmente cada mañana. El archivo se descarga con la extensión txt. Después de la descarga, hay que cambiar la extensión por csv y colocar el archivo en la carpeta ..\Files\evolution-dvoid\dvoid-BP.csv |
| 4 | BuyVOLDOWNOPNDOWN.mq5 | Indicador | La red para la clasificación de las señales de compra los días cuando el volumen y el interés abierto han caído. |
| 5 | BuyVOLDOWNOPNUP.mq5 | Indicador | La red para la clasificación de las señales de compra los días cuando el volumen ha caído y el interés abierto ha crecido. |
| 6 | BuyVOLUPOPNDOWN.mq5 | Indicador | La red para la clasificación de las señales de compra los días cuando el volumen ha crecido y el interés abierto ha caído. |
| 7 | BuyVOLUPOPUP.mq5 | Indicador | La red para la clasificación de las señales de compra los días cuando el volumen y el interés abierto han crecido. |
| 8 | SellVOLDOWNOPNDOWN.mq5 | Indicador |
La red para la clasificación de las señales de venta los días cuando el volumen y el interés abierto han caído. |
| 9 | SellVOLDOWNOPNUP.mq5 | Indicador | La red para la clasificación de las señales de venta los días cuando el volumen ha caído y el interés abierto ha crecido. |
| 10 | SellVOLUPOPNDOWN.mq5 | Indicador |
La red para la clasificación de las señales de venta los días cuando el volumen ha crecido y el interés abierto ha caído. |
| 11 | SellVOLUPOPNUP.mq5 | Indicador |
La red para la clasificación de las señales de venta los días cuando el volumen y el interés abierto han crecido. |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/2773
 Los Asesores Expertos desde el Asistente MQL5 funcionan en MetaTrader 4
Los Asesores Expertos desde el Asistente MQL5 funcionan en MetaTrader 4
 Recetas MQL5 - Creando el búfer circular para calcular rápidamente los indicadores en la ventana móvil
Recetas MQL5 - Creando el búfer circular para calcular rápidamente los indicadores en la ventana móvil
 Patrones disponibles al comerciar con cestas de divisas. Parte II
Patrones disponibles al comerciar con cestas de divisas. Parte II
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso