Cuantificación en el aprendizaje automático (Parte 1): Teoría, ejemplo de código, análisis sintáctico de la aplicación CatBoost

Introducción
En el presente artículo veremos la aplicación de la teoría de la cuantificación a la construcción de modelos arbóreos. El material se presentará sin fórmulas matemáticas complejas, en un lenguaje accesible. Mientras preparaba el artículo, descubrí que no existe una terminología uniforme establecida en las obras científicas de diferentes autores, tal vez sea por el coste de la traducción, así que he elegido aquellas variantes de los términos que en mi opinión reflejan en mayor medida el significado; utilizaré mi terminología en aquellas cuestiones que hayan quedado sin la debida atención por parte de otros investigadores. Este artículo usará términos y conceptos sobre los que ya he escrito anteriormente en el artículo "Aprendizaje de máquinas de Yándex (CatBoost) sin estudiar Python y R", por lo que le recomiendo que lo lea antes de abordar el material propuesto.
En este artículo no analizaremos la posibilidad de aplicar la cuantificación a las redes neuronales entrenadas para reducir su tamaño, ya que por el momento no tengo experiencia propia en esta materia.
Qué espera al lector en este artículo:
- La primera parte contiene material teórico introductorio sobre la cuantificación, y será útil para comprender el propósito y la naturaleza del proceso.
- En la segunda parte del artículo, describiremos el método de cuantificación uniforme usando un ejemplo del código MQL5.
- En la tercera parte le propondremos familiarizarse con la realización del proceso de cuantificación usando un ejemplo de CatBoost.
1. Propósitos estándar del uso
Qué es la cuantificación y por qué se usa: ¡vamos al grano!
En primer lugar, hablemos un poco de datos. Así, para crear modelos (entrenarlos) se requieren datos meticulosamente recopilados en una tabla; la fuente de dichos datos puede ser cualquier información que pueda explicar la métrica objetivo (lo cual determinará el modelo, por ejemplo, una señal comercial). Las fuentes de datos pueden denominarse de diferentes formas: predictores, fichas, atributos o factores. La frecuencia de aparición de una fila de datos viene determinada por la aparición de una observación comparable del proceso del fenómeno sobre el que se recopila información y que se estudiará con la ayuda del aprendizaje automático. El conjunto de los datos obtenidos se denomina muestra.
Una muestra puede ser representativa, es decir, cuando las observaciones registradas en ella describen el proceso completo del fenómeno estudiado, o puede ser no representativa, es decir, cuando hay tantos datos como ha sido posible recoger, lo que solo permite describir parcialmente el proceso del fenómeno estudiado. Por regla general, cuando nos ocupamos de los mercados financieros, tratamos con muestras no representativas, porque aún no ha ocurrido todo lo que puede ocurrir, y por este motivo no sabemos cómo se comportará un instrumento financiero cuando se produzcan nuevos eventos que no han ocurrido antes, en su totalidad. No obstante, todo el mundo conoce la expresión "la historia se repite", y es en esta observación en la que se basa un tráder algorítmico en su investigación, con la esperanza de que entre los nuevos eventos se encontrarán aquellos que fueron similares a los anteriores, y que su resultado se asemejará a la probabilidad identificada.
Desde el punto de vista de su contenido lógico (escala de medida), los indicadores numéricos de predictores pueden ser:
- Binarios: confirman o refutan la presencia de una característica fija del fenómeno observado;
- Cuantitativos (escala métrica): describen un fenómeno usando algún indicador medible, por ejemplo, la velocidad, las coordenadas de algo, el tamaño, el tiempo transcurrido desde el inicio de un suceso y muchas otras características que pueden medirse, incluidas sus derivadas.
- Categóricos (escala nominal): señalan objetos o fenómenos observables diferentes pero pertenecientes al mismo grupo lógico, normalmente expresado como un número entero. Por ejemplo, días de la semana, dirección de la tendencia del precio, número de nivel de apoyo o resistencia.
- De rango (escala ordinal): caracterizan el grado de superioridad u ordenación de algo. Rara vez se distinguen como grupo aparte, ya que dependiendo del contexto y la lógica pueden atribuirse a otros tipos de indicadores. Por ejemplo, pueden incluir el orden de las acciones, o el resultado de un experimento como la evaluación de su resultado en relación con otros experimentos similares.
Así, la muestra contiene diferentes predictores con sus valores numéricos, y estos datos, en su totalidad, describen el fenómeno observado, cuyas características o tipo se describen en la función objetivo (en adelante, objetivo). El objetivo de la muestra puede ser un indicador numérico o categórico, y en adelante en el texto me referiré a la función objetivo categórica, y en mayor medida a la binaria.
La wikipedia ofrece la siguiente definición:
Cuantificación (ingl. quantization): en el tratamiento de señales, es la división de la gama de valores de referencia de la señal en un número finito de niveles y el redondeo de estos valores a uno de los dos niveles más próximos. El valor de la señal puede redondearse al nivel más próximo, o al menor o mayor de los niveles más próximos, según el método de codificación. Esta cuantificación se denomina cuantificación escalar. También existe la cuantificación vectorial, que consiste en dividir el espacio de valores posibles de una magnitud vectorial en un número finito de áreas y sustituir estos valores por el identificador de una de estas áreas.
Me gusta otra definición más corta:
La cuantificación de datos es un método de compresión (codificación) de la información sobre una observación con una pérdida aceptable de precisión en su escala de medida. La compresión (codificación) implica la discreción de los objetos, lo cual implica su igualdad y homogeneidad, o simplemente, su similitud. El criterio de similitud puede ser distinto, dependiendo del algoritmo elegido y de la lógica incorporada en él.
La cuantificación de datos se usa en todas partes, especialmente en la conversión de una señal analógica en digital, así como en la posterior compresión de la señal digital. Por ejemplo, los datos recibidos del sensor de una cámara pueden grabarse como un archivo sin procesar y, a continuación (de inmediato o más tarde), en un ordenador, comprimirse en formato jpg u otro formato de almacenamiento de datos conveniente.
Cuando observamos la representación gráfica de los datos en forma de velas o barras en el terminal MetaTrader 5, vemos el resultado de la cuantificación de los ticks en la escala temporal seleccionada. Es cierto que el proceso de cuantificar un flujo continuo de datos a lo largo del tiempo suele denominarse discretización.
Normalmente, la discretización es el proceso de captar las características de una observación en una frecuencia temporal determinada. No obstante, si consideramos que es la frecuencia con la que se recogen los datos en una muestra, entonces la definición debería ajustarse a lo siguiente "el muestreo es el proceso de registro de las características de una observación cuya frecuencia viene determinada por una función dada en su umbral de activación". Por función entenderemos aquí cualquier algoritmo que, según su propia lógica inherente, emita una señal para recibir datos. Por ejemplo, en MetaTrader 5 vemos exactamente este enfoque, porque en los días no comerciales, en lugar de repetir el precio de cierre como un proceso continuo en el tiempo, simplemente no existe información en el gráfico, es decir, la tasa de muestreo cae a cero.
Un ejemplo sencillo de algoritmo de cuantificación sería la construcción de un histograma. El algoritmo de este método es bastante simple:
- Encontramos el valor máximo y mínimo del indicador (en nuestro caso, el predictor).
- Calculamos la diferencia entre el valor máximo y el mínimo.
- Dividimos el delta resultante en el punto 2 por un número entero, por ejemplo diez, o como recomienda Carl Pearson, según el número de observaciones. Luego obtenemos el paso de división en las unidades iniciales, que serán la referencia de la nueva escala de medida.
- Ahora deberemos construir su escala, con sus divisiones. Esto se hace simplemente multiplicando el paso por el número de referencia ordinal.
- El algoritmo procede entonces asignando cada valor de observación a un rango de la nueva escala de medición y resumiendo aparte el número de observaciones en cada rango.
El resultado del algoritmo será el histograma mostrado en la figura 1.
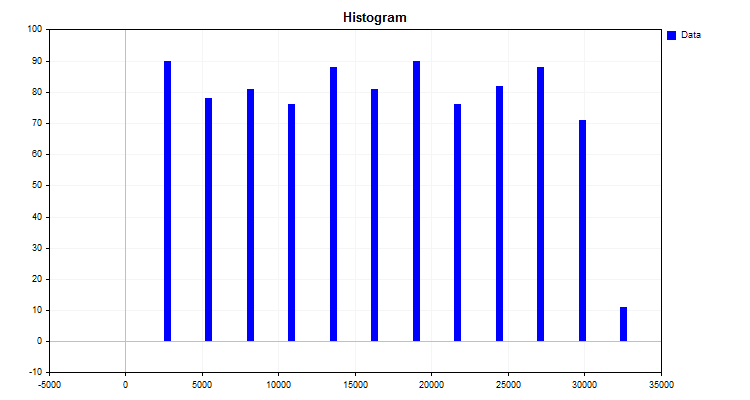
Figura nº 1.
El histograma muestra cómo se han distribuido los datos en la nueva escala de medición. A partir del aspecto de la distribución, usando el aparato de la estadística descriptiva, podemos inferir el tipo de densidad de la distribución, lo cual puede resultar útil para elegir el método de cuantificación finita. No obstante, le propongo familiarizarse con el tema de la distribución de la densidad en los artículos disponibles en nuestro portal favorito:
- Estimación de la densidad del kernel de la función de densidad de probabilidad desconocida;
- Distribuciones Estadísticas en MQL5: tomamos lo mejor de R y lo hacemos más rápido;
- Cálculos Estadísticos.
¿Qué hemos obtenido construyendo el histograma?
- Los niveles (puntos de corte) o bordillos que dividen los datos en grupos. El conjunto de niveles se denomina rejilla cuántica o diccionario. Conforme a estos niveles tiene lugar el proceso de codificación de los datos, que garantiza su agrupación y compresión. Los límites pueden fijarse según distintas reglas integradas en el algoritmo de cuantificación. Los niveles (puntos de corte) forman una nueva escala para medir el rendimiento de las observaciones. El intervalo entre dos niveles lo suelo llamar "intervalo cuántico", aunque en la literatura hay otros nombres: "intervalo", "rango", "paso de cuantificación";
- La pertenencia de cada valor de observación (métrica) a un grupo determinado (columna del histograma). En el caso de la cuantificación, es obra del algoritmo de compresión, cuya esencia es la transformación de los datos originales en datos comprimidos en el momento en que se atribuye el valor de observación a un determinado rango de la rejilla cuántica. El resultado de la compresión puede ser una transformación numérica distinta del valor de la variable. Con frecuencia se encuentran dos opciones: la primera opción es una transformación en la que se asigna a una variable un rango (índice) según el número del intervalo entre los valores de corte (bordillo) en el que cae el número. La segunda opción consiste en asignar un valor de escala de nivel a la variable, por ejemplo, si un valor de observación numérico cae en el intervalo entre 1,2 y 1,4, entonces se asignará al valor de la derecha - 1,4. No obstante, para aplicar la segunda opción será necesario establecer límites más allá de los cuales no irán los datos, mientras que la primera opción permite trabajar con cualquier valor fuera de los límites de la tabla cuántica. Para la segunda opción, una buena solución sería forzar la adición de niveles (bordillos/límites) a una distancia significativa, permitiendo que los errores en forma de valores atípicos o los datos restantes se coloquen allí.
- Es posible recuperar cada valor de un número con pérdida de precisión (decuantificación), lo cual puede lograrse de las siguientes maneras:
- - Centrando el intervalo que corresponde al índice del número.
- - Según el valor izquierdo o derecho del nivel (frontera/corte/bordillo) del intervalo, más a menudo el derecho. Considerando que para el primer y el último intervalo los límites no suelen estar definidos en la tabla de cuantificación, podemos utilizar el rango medio de los intervalos o el primer y el último valor de la anchura del intervalo para definirlos.
Dependiendo del problema y del campo de aplicación de la cuantificación nos encontraremos con diferentes designaciones de variables y estilos de escritura de fórmulas, lo cual dificulta la comprensión de la esencia del algoritmo, porque el autor que las describe asume conocimientos del campo concreto en el que se aplica el algoritmo. La esencia de los diferentes algoritmos se reduce a las diferentes formas de construir los niveles (puntos de corte), por lo que sugiero generalizarlos según una serie de características.
Cuantificación de intervalos constantes:
- Partición en intervalos fijos usando un método similar al histograma de Pearson;
- Conversión para reducir el dígito de un número.
Cuantificación de intervalos variables:
- Acumulación de un porcentaje fijo de observaciones para cada intervalo.
- Uso de un valor fijo del área bajo la curva de una distribución teórica o aproximada.
- Uso una función determinada que cambie el paso de cuantificación en función del coeficiente. Suelen ser funciones que amplían el intervalo hasta el borde o hasta el centro.
- Uso de factores de ponderación que afectan al intervalo en función de la densidad de valores.
- Métodos iterativos, incluidos los métodos adaptativos. Para ajustar los bordillos, se utiliza la información sobre la estructura de datos y se toman medidas para reducir el error.
- Otros métodos.
Cuantificación con un intervalo definido empíricamente:
- Secuencias numéricas;
- Conocimiento de la naturaleza de la observación para agrupar indicadores similares;
- Método de marcado manual.
La reducción del error de cuantificación en la métrica seleccionada puede ser un proceso iterativo o calcularse una vez mediante una fórmula determinada. Para evaluar el resultado, será cómodo utilizar el porcentaje medio de propagación del error en relación con toda la gama de números que toman el valor predictor en la muestra.
2. Ejemplo de aplicación del algoritmo de cuantificación en MQL5
Antes hemos descrito un ejemplo sencillo sobre cómo se realiza la cuantificación, pero le falta uno de los pasos que se suelen utilizar en la cuantificación, a saber, la redivisión de la escala obtenida tras algunos cálculos para hallar el valor medio del intervalo, que suele denominarse centroide. El intervalo de cuantificación se definirá finalmente por la mitad de la distancia entre los límites de dos centroides cercanos.
Como ejemplo, cuantificaremos paso a paso los números reales de tipo double, que ocupan 8 bytes en memoria, en el tipo de datos entero uchar, que solo ocupa 8 bits:
- 1. Encontramos el máximo y el mínimo en los datos de entrada:
- 1.1.Hallamos el valor de máximo y mínimo - variable Max y Min en el array arr_In_Data.
- 2. Calculamos el tamaño de la ventana entre intervalos:
- 2.1. Encontramos la diferencia entre el máximo y el mínimo,la guardamos en la variable Delta.
- 2.2. Hallamos el tamaño de una ventana Delta/nQ, donde nQ es el número de separadores (bordillos); el resultado se almacenará en la variable Interval_Size.
- 3. Cuantificamos y calculamos el error:
- 3.1. Desplazamos el mínimo del valor de los datos de entrada a cero arr_In_Data-Min.
- 3.2. Dividimos el resultado de 3.1. por el número de intervalos Interval_Size, que es uno más que el número de separadores.
- 3.3. Ahora debemos aplicar la función de redondeo, que redondea el número al entero más próximo, al resultado obtenido en 3.2. El resultado se almacenará en el array arr_Output_Q_Interval.
- 3.4. Multiplicamos el valor del array arr_Output_Q_Interval por Interval_Size y añadimos el mínimo. Este será el valor convertido (no cuantificado) del número, que guardaremos en el array arr_Output_Q_Data.
- 3.5. Calculamos el error según el total acumulado; para ello, dividiremos la diferencia de módulo entre el valor inicial y el valor obtenido como resultado de la cuantificación por el rango. Dividimos el total resultante por el número de elementos del array arr_In_Data.
- 4. Guardamos los separadores (bordillos) en el array arr_Output_Q_Book:
- 4.1. Para el primer intervalo hacemos una corrección: al valor mínimo (Min) le añadimos la mitad del tamaño del intervalo (Interval_Size).
- 4.2. Los intervalos posteriores ya se cuentan calculando el valor del intervalo respecto al valor del array arr_Output_Q_Book en el paso anterior.
A continuación le mostramos un ejemplo de código de función con la descripción de las variables y arrays.
/+---------------------------------------------------------------------------------+ //|Quantization of transformation (encoding) type to a given integer bitness //+---------------------------------------------------------------------------------+ double Q_Bit( double &arr_Input_Data[],//Quantization data array int &arr_Output_Q_Interval[],//Outgoing array with intervals containing data double &arr_Output_Q_Data[],//Outgoing array with restored values of the original data float &arr_Output_Q_Book[],//Outgoing array - "Book with boundaries" or "Quantization table" int N_Intervals=2,//Number of intervals the original data should be divided (quantized) into bool Use_Max_Min=false,//Use/do not use incoming maximum and minimum values double Min_arr=0.0,//Maximum value double Max_arr=100.0//Minimum value ) { if(N_Intervals<2)return -1;//There may be at least two intervals, in this case, there is one separator //---0. Initialize the variables and copy the arr_Input_Data array double arr_In_Data[]; double Max=0.0;//Maximum double Min=0.0;//Minimum int Index_Max=0;//Maximum index in the array int Index_Min=0;//Minimum index in the array double Delta=0.0;//Difference between maximum and minimum int nQ=0;//Number of separators (borders) double Interval_Size=0.0;//Interval size int Size_arr_In_Data=0;//arr_In_Data array size double Summ_Error=0.0;//To calculate error/data loss nQ=N_Intervals-1;//Number of separators Size_arr_In_Data=ArrayCopy(arr_In_Data,arr_Input_Data,0,0,WHOLE_ARRAY); ArrayResize(arr_Output_Q_Interval,Size_arr_In_Data); ArrayResize(arr_Output_Q_Data,Size_arr_In_Data); ArrayResize(arr_Output_Q_Book,nQ); //---1. Finding the maximum and minimum in the input data if(Use_Max_Min==false)//If enforced array limits are not used { Index_Max=ArrayMaximum(arr_In_Data,0,WHOLE_ARRAY); Index_Min=ArrayMinimum(arr_In_Data,0,WHOLE_ARRAY); Max=arr_In_Data[Index_Max]; Min=arr_In_Data[Index_Min]; } else//Otherwise enforce the maximum and minimum { Max=Max_arr; Min=Min_arr; } //---2. Calculate the window size between intervals Delta=Max-Min;//Difference between maximum and minimum Interval_Size=Delta/nQ;//Size of one window //---3. Perform quantization and error calculation for(int i=0; i<Size_arr_In_Data; i++) { arr_Output_Q_Interval[i]=(int)round((arr_In_Data[i]-Min)/Interval_Size); arr_Output_Q_Data[i]=arr_Output_Q_Interval[i]*Interval_Size+Min; Summ_Error=Summ_Error+(MathAbs(arr_Output_Q_Data[i]-arr_In_Data[i]))/Delta; } //---4. Save separators (borders) into the array for(int i=0; i<nQ; i++) { switch(i) { case 0: arr_Output_Q_Book[i]=float(Min+Interval_Size*0.5); break; default: arr_Output_Q_Book[i]=float(arr_Output_Q_Book[i-1]+Interval_Size); break; } } return Summ_Error=Summ_Error/(double)Size_arr_In_Data*100.0; }
Qué aporta la cuantificación de datos en sentido práctico:
- Reducción de la memoria necesaria para guardar y procesar datos. Este efecto se consigue almacenando solo el índice del segmento cuántico en el que cae el valor numérico del número índice. Tendrá sentido cambiar el tipo de datos de real double o float a tipos enteros como int o incluso uchar.
- Aceleración del cálculo. Se logra trabajando con números enteros y reduciendo el conjunto de números usados, lo cual reduce el número de ciclos en los algoritmos.
- Reducción del ruido. La calidad de los datos brutos puede contener ruido en forma de errores de medición, tanto primarios -pérdida de datos del bróker- como en forma de retrasos, redondeos y errores de medición; la cuantificación, de hecho, promedia el indicador en el rango del segmento cuántico, lo que suaviza dicho ruido y no permite al modelo centrar su atención en él.
- Compensación de la falta de valores de observación cercanos. A veces el valor predictor resulta muy raro debido a la escasez de observaciones y no puede considerarse un valor atípico; la cuantificación puede dar a esas observaciones un rango suficiente de dispersión del valor para que sea adecuado utilizar el modelo en nuevos datos que no estaban en la muestra.
- Lucha contra la maldición de la dimensionalidad. Reduciendo el número de combinaciones posibles, se disminuye la rejilla de coordenadas posibles de los espacios de medición, lo que acelera y mejora el proceso de aprendizaje.
En los dos ejemplos, hemos visto que existen dos estrategias principales de cuantificación:
- Una estrategia destinada a aproximar los datos.
- Y otra estrategia orientada a la adición de datos.
El primer tipo de estrategias resulta adecuado para escalas métricas que miden indicadores próximos a una distribución continua de valores de características. En teoría, cuantos más intervalos separen el rango de valores, mejor, ya que el error de dispersión del valor reconstruido en todo el rango de la serie numérica será menor. Este tipo resulta muy adecuado para la recuperación de funciones matemáticas.
El segundo tipo de estrategias tiene por objeto agrupar los datos; cabe imaginar que se crean valores categóricos generalizados de las características, y aquí el problema de la estimación correcta de los límites resulta mucho más complicado: según mi experiencia, hay que procurar que al menos el 5% de las observaciones de la muestra entren en el intervalo.
Debemos tener en cuenta que las características que ya tienen un significado categórico, sin convenciones, deben cuantificarse con mucha cautela, combinando solo las que sean realmente similares. En este caso, la similitud implicará aquí la similitud de las muestras cuando se dividen en submuestras.
Adjuntamos al artículo el script "Q_Trans" que sirve de ejemplo del proceso de cuantificación, los datos para la cuantificación se generan aleatoriamente, y contiene las siguientes funciones principales:
- "Q_Bit" - Cuantificación - tipo de conversión (codificación) a un bit entero determinado
- "Book_to_cifra" - Decodificador - recupera un valor aproximado de un número de la Tabla de Cuantificación, se requiere un array con índices.
- "Book_to_cifra_v2" - Decodificador - recupera un valor aproximado de un número de la Tabla de Cuantificación, no se requiere un array con índices.
- "Q_Random" - Cuantificación - con ajuste aleatorio de los límites.
El script contiene las siguientes configuraciones:
- Número de intervalos en los que dividir (sin cuantificar) los datos originales;
- Número inicializador para el generador de números aleatorios;
- Almacenamiento de gráficos;
- Directorio para guardar los gráficos;
- Anchura del gráfico;
- Altura del gráfico;
- Tamaño de la fuente.
Descripción de las etapas de funcionamiento del script:
- Primero se generará una muestra aleatoriamente.
-
El gráfico del instrumento comercial mostrará un gráfico de histograma, construido como hemos descrito antes en el artículo (figura 1), así como un gráfico con los valores del predictor generado, distribuidos por orden cronológico y divididos por los límites obtenidos tras la cuantificación (figura 2). Si la opción "Guardar gráficos" se ha establecido en "true", los gráficos se guardarán en el directorio de archivos de usuario del terminal "Files\Q_Trans\Grafics".
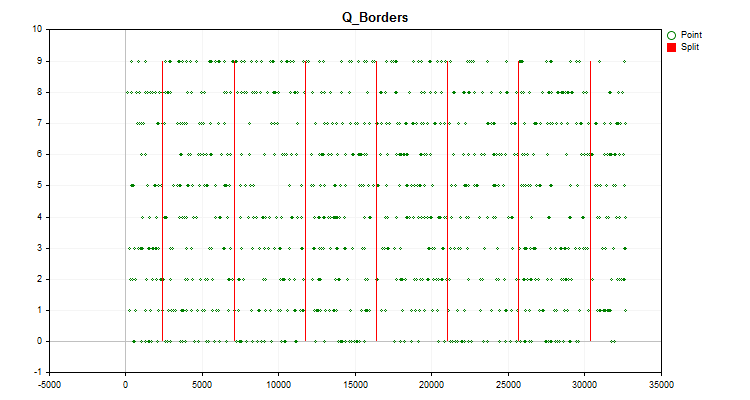 Figura nº 2.
Figura nº 2. - La función "Q_Bit" cuantificará y calculará el error como desplazamiento del valor reconstruido con respecto a todo el rango de valores de la muestra.
- La función "book_to_cifra" se usará para la decuantificación del centroide y calcular el error como desplazamiento del valor recuperado.
- La función "Book_to_cifra" se utilizará para la decuantificación del límite derecho y calcular el error como desplazamiento del valor recuperado.
- La función "Book_to_cifra_v2" se utilizará para la decuantificación del centroide y calcular el error como desplazamiento del valor recuperado.
- La función "Q_Random" se utilizará para realizar 1 000 intentos de encontrar los mejores intervalos para dividir el predictor.
- La función "book_to_cifra" se utilizará para la decuantificación utilizando la mejor rejilla obtenida aleatoriamente en el centroide y calcular el error en forma de desplazamiento del valor recuperado.
Si ejecutamos el script con la configuración por defecto, veremos la siguiente información en la columna "Mensaje" del registro del terminal "Expertos"
Average data recovery error size = 3.52% of full range when using 8 intervals Average error size via quantum table for centroid conversion (Book_to_cifra) = 1145.62263 Average error size via quantum table for right boundary conversion (Book_to_cifra) = 2513.41952 Average error size via quantum table for centroid transformation (Book_to_cifra_v2) = 1145.62263 Average error size via quantum table for centroid transformation (Q_Random) = 1030.79216
Curiosamente, el método aleatorio de selección de límites ha mostrado incluso mejores resultados que el que consideramos antes, basado en la cuantificación uniforme.
3. Cuantificación con CatBoost
CatBoost, sobre el que ya hablé anteriormente en mi artículo "Aprendizaje de máquinas de Yándex (CatBoost) sin estudiar Python y R", utiliza la cuantificación para preprocesar los datos, lo cual hace que el algoritmo de potenciación del gradiente sea mucho más rápido. Al igual que antes, usaremos la versión para consola de CatBoost, ya que no requiere la instalación de software adicional cuando se ejecuta en la CPU del ordenador.
Necesitaremos los siguientes ajustes:
1. El método de cuantificación (separación), la clave "--feature-border-type":
- Median
- Uniform
- UniformAndQuantiles
- MaxLogSum
- MinEntropy
- GreedyLogSum
2. Un número de separadores de 1 a 65535, clave "--border-count"
3. El almacenamiento de tablas de cuantificación en un archivo especificado, clave " --output-borders-file"
4. La carga de las tablas de cuantificación a partir del archivo especificado, clave " --input-borders-file"
Si no especificamos las claves descritas anteriormente, se aplicarán los ajustes por defecto para construir los modelos utilizados en el artículo:
- Para el cálculo en CPU, el método de cuantificación es "GreedyLogSum", el número de separadores es "254";
- Para los cálculos GPU, el método de cuantificación es "GreedyLogSum", el número de separadores es "128".
Aquí tenemos algunos ejemplos de cómo prescribir estas claves:
Configuramos la cuantificación estableciendo el método "Uniform" y el número de separadores en 30, y guardamos la tabla de cuantificación en el archivo "Quant_CB.csv"
catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description Test_CB_Setup_0_000000000 --has-header --delimiter ; --train-dir ..\Rezultat --feature-border-type Uniform --border-count 30 --output-borders-file Quant_CB.csv
Luego cargamos la tabla de cuantificación del archivo "Quant_CB.csv" y entrenamos el modelo.
catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description Test_CB_Setup_0_000000000 --has-header --delimiter ; --train-dir ..\Rezultat --input-borders-file Quant_CB.csv
La sección del manual del desarrollador relativa a los ajustes de cuantificación puede consultarse en el siguiente enlace
Veamos en qué se diferencian los métodos de cuantificación aplicados a datos concretos. A continuación le mostramos los gráficos como archivos gif, cada nuevo marco será el siguiente método, el número de separadores que hemos tomado es 16.
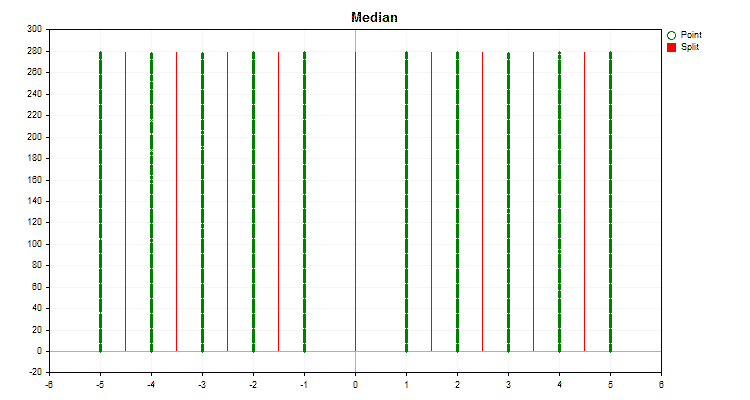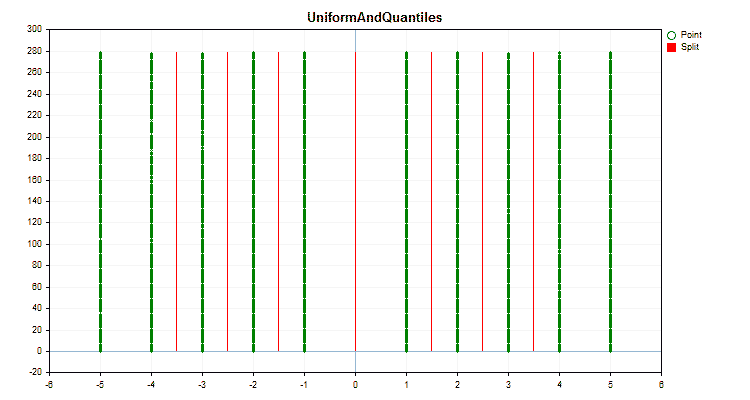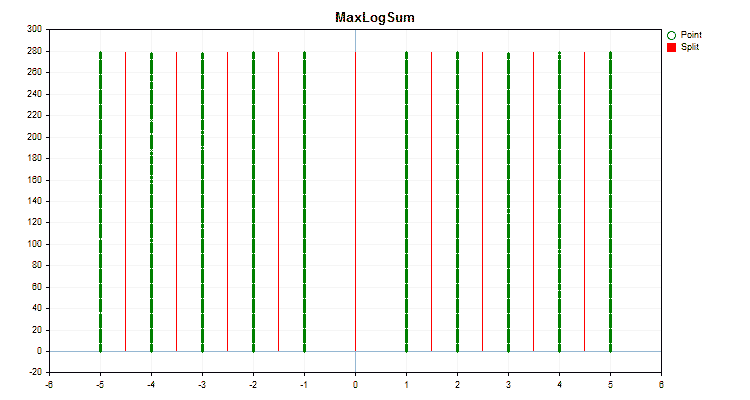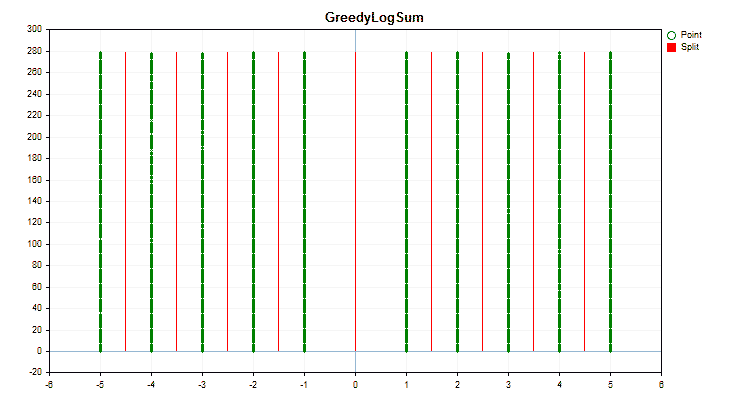
Figura nº 2 "Gráfico de datos para el predictor categórico"
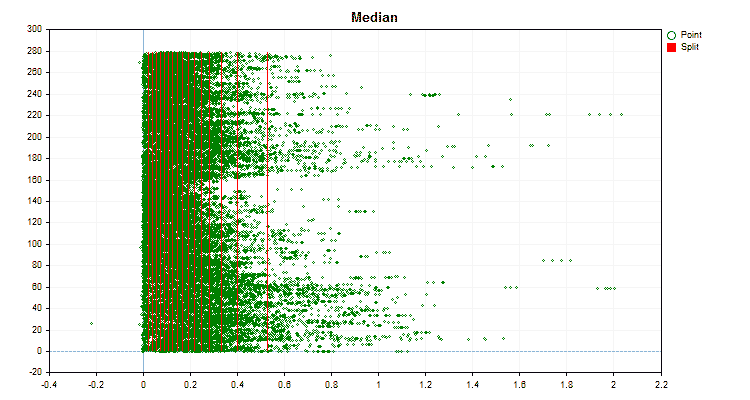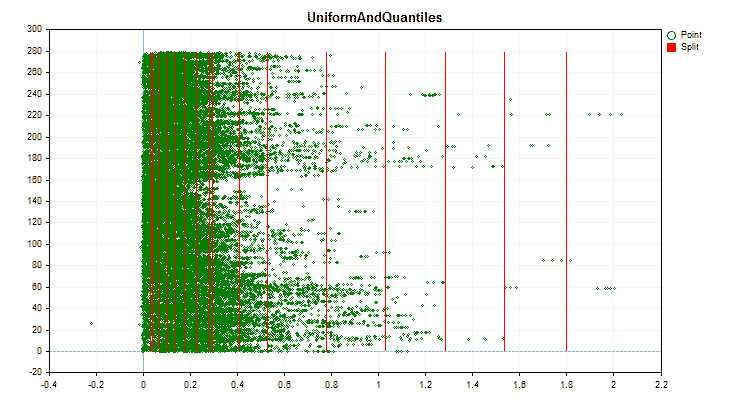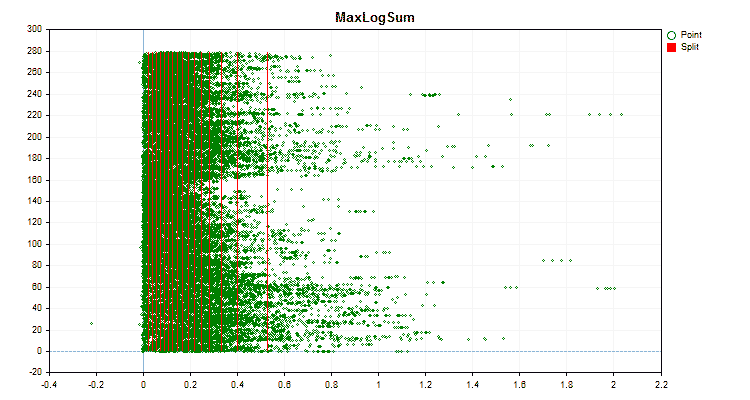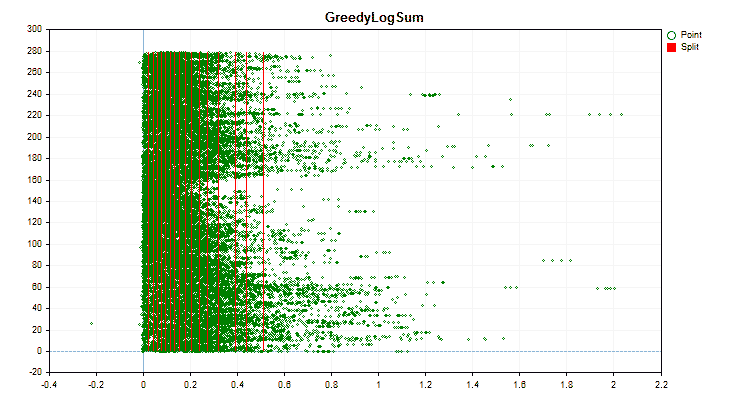
Figura nº 3 "Gráfico de datos del predictor con valores desplazados a la región izquierda"
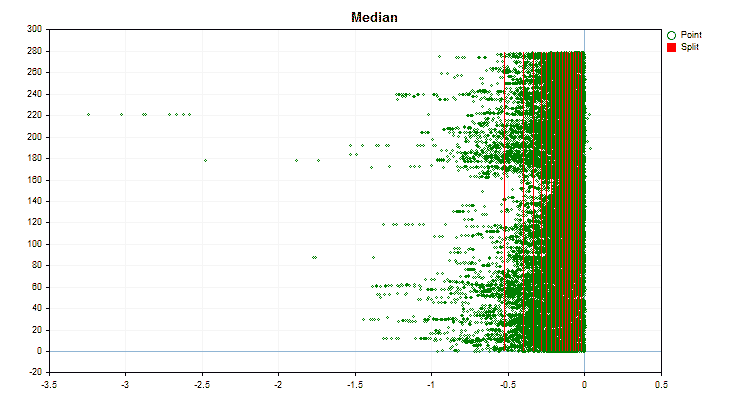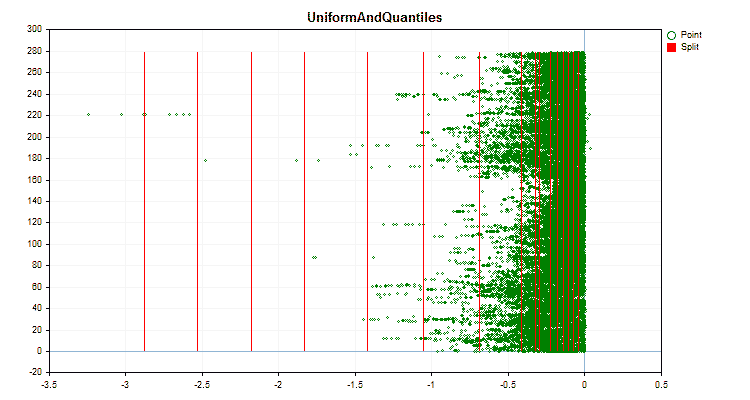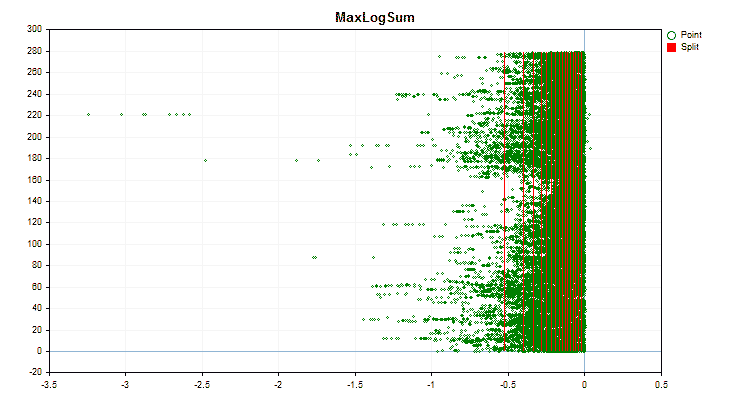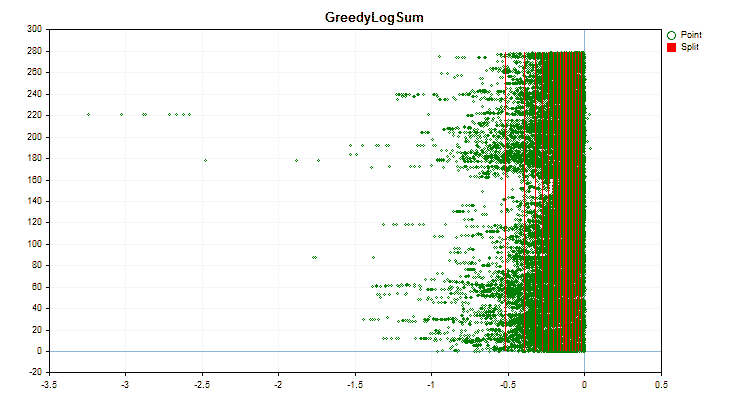
Figura nº 4 "Gráfico de datos del predictor con valores desplazados a la región derecha"
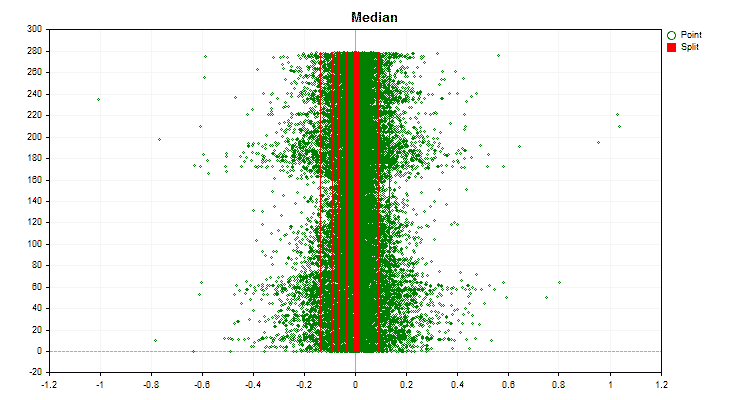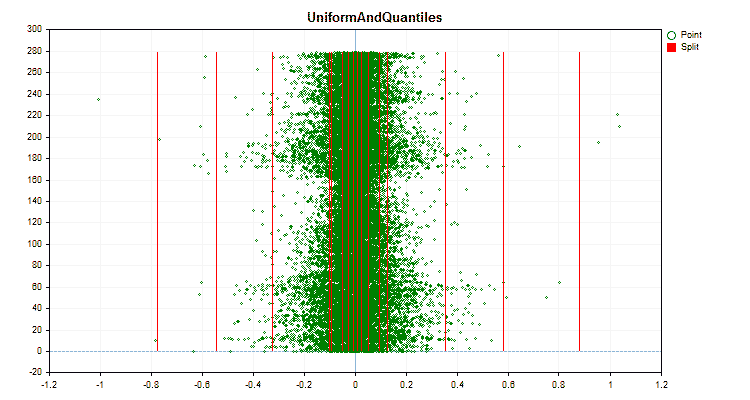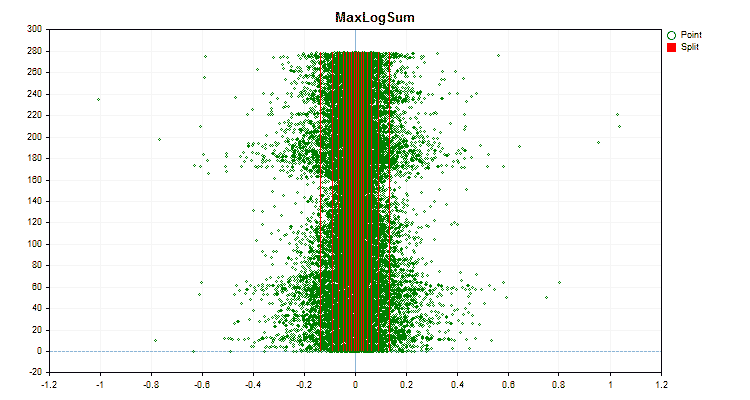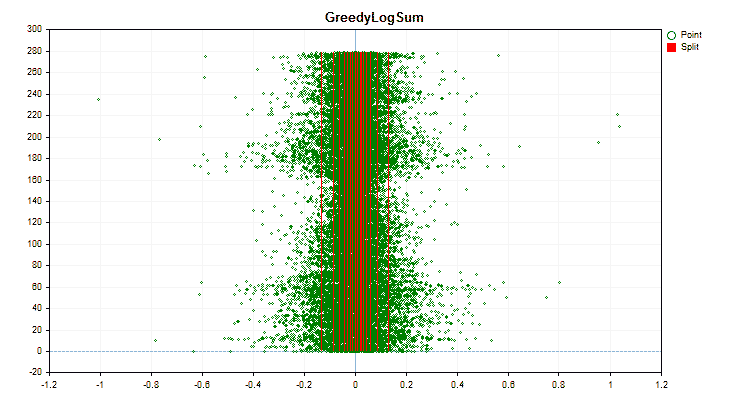
Figura nº 5 "Gráfico de datos del predictor con valores ubicados en la zona central"
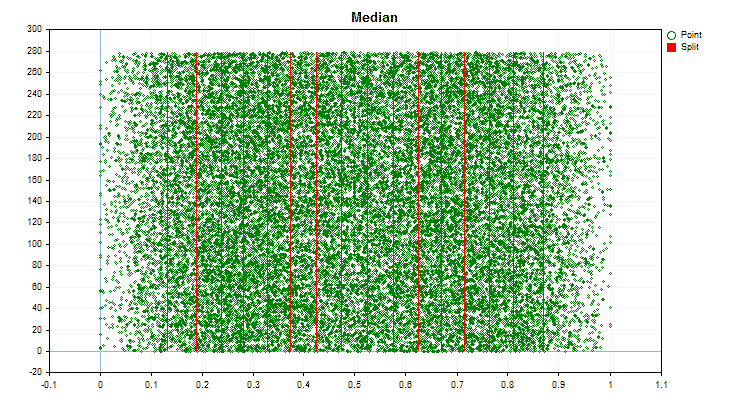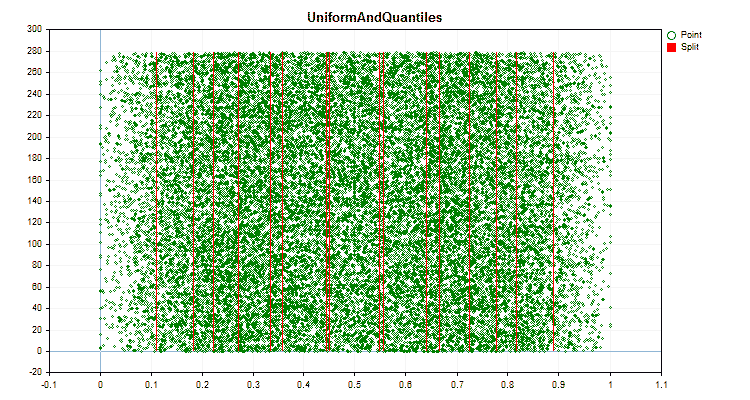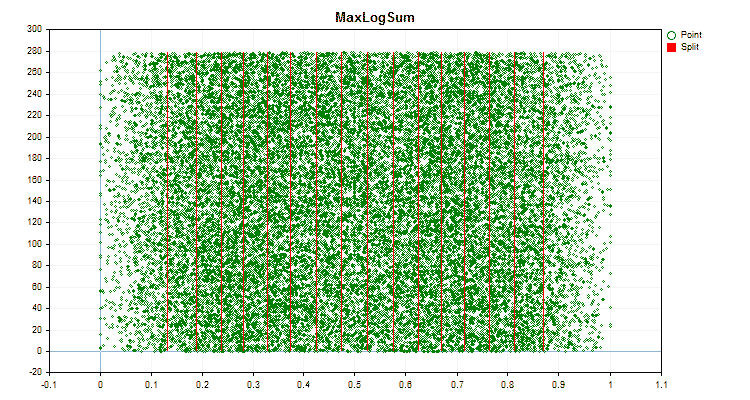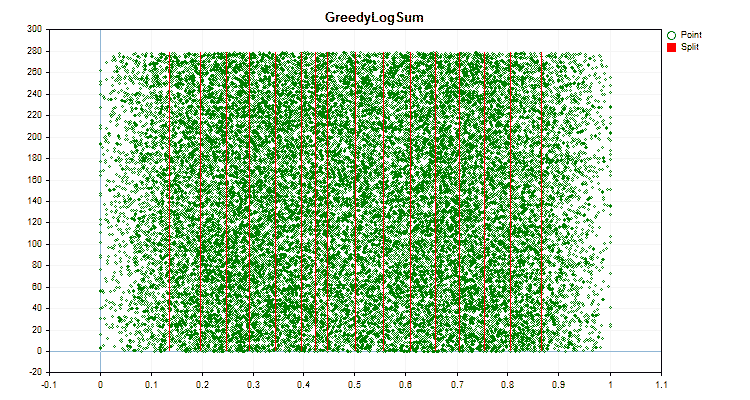
Figura nº 6 "Gráfico de datos para el predictor con una distribución uniforme de valores"
Si analizamos la estructura del archivo con la tabla de cuantificación, en nuestro caso será el archivo "Quant_CB.csv", veremos dos columnas y muchas filas. La primera columna almacena el número ordinal del predictor que se usará en el entrenamiento del modelo y la segunda el separador (bordillo/nivel). El número de filas se corresponderá con la suma acumulada de separadores, mientras que el número de la primera columna cambiará una vez enumerados todos los separadores.
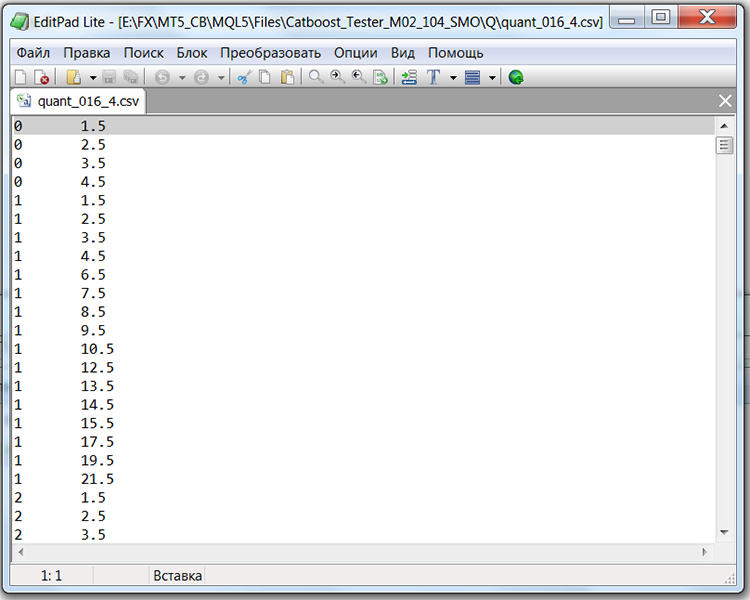
Tabla 1 "Contenido del archivo CatBoost guardado con separadores"
Conclusión
En este artículo, nos hemos familiarizado con el concepto de cuantificación, hemos analizado el proceso de obtención de valores predictivos cuantificados usando el ejemplo de código MQL5 y hemos considerado la implementación de la cuantificación en CatBoost.
Si el estimado lector ha encontrado errores en la terminología o los juicios del artículo, por favor, le ruego que me escriba: está en su mano mejorar el texto en beneficio de nuestra comunidad.
En el próximo artículo abordaremos cómo podemos seleccionar las tablas cuánticas para un predictor concreto, además de realizar un experimento para evaluar la viabilidad de esta tarea.
| # | Anexo | Descripción |
|---|---|---|
| 1 | Q_Trans.mq5 | Script que contiene un ejemplo de cuantificación uniforme en una muestra aleatoria. |
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/13219
 Añadimos un LLM personalizado a un robot comercial (Parte 2): Ejemplo de despliegue del entorno
Añadimos un LLM personalizado a un robot comercial (Parte 2): Ejemplo de despliegue del entorno
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso