
Kategorientheorie in MQL5 (Teil 13): Kalenderereignisse mit Datenbankschemata
Einführung
In unserem letzten Artikel dieser Serie über die Kategorientheorie haben wir uns angesehen, wie die Ordnungstheorie mit der Kategorientheorie zusammenarbeiten kann, wir haben untersucht, wie Konzepte aus dieser Vereinigung in MQL5 implementiert werden können, und wir haben auch eine Fallstudie über ein Handelssystem betrachtet, das einige dieser Konzepte verwendet.
In unserem letzten Artikel haben wir uns auf zwei ordnungs-theoretische Konzepte konzentriert, nämlich partielle Ordnungen und lineare Ordnungen. Bei partiellen Ordnungen handelt es sich, um es noch einmal zusammenzufassen, um eine Reihe von Rangordnungsmethoden, die eine spezielle Art mit antisymmetrische Relation sind. Das heißt, sie haben auch reflexive und transitive Relationen. Lineare Ordnungen hingegen sind eine gezieltere Form der partiellen Ordnungen, da sie zusätzlich Vergleichbarkeit erfordern, was bedeutet, dass undefinierte Beziehungen nicht zulässig sind.
In diesem Artikel werden wir eine Pause von der Einführung neuer Konzepte einlegen und einen Schritt zurückgehen, um einiges von dem, was bisher behandelt wurde, mit dem Ziel zu überprüfen, es in einen Sprachklassifikator zu integrieren, der Relationenschemata verwendet.
Die Notwendigkeit einer effektiven Klassifizierung von Kalenderereignisse
Kalenderereignisse gibt es fast täglich, wobei die meisten bereits Monate im Voraus bekannt sind. Sie werden über den MetaTrader-Wirtschaftskalender bezogen und beleuchten Währungs- und makroökonomische Indikatoren für China, die USA, Japan, Deutschland, die EU, Großbritannien, Südkorea, Singapur, die Schweiz, Kanada, Neuseeland, Australien und Brasilien. Die Liste scheint dynamisch zu sein, sodass in Zukunft weitere Länder hinzukommen könnten. Diese Indikatoren sind häufig, aber nicht immer, mit numerischen Werten formatiert, die in erster Linie einen Prognosewert, einen Istwert und einen früheren Wert enthalten. Das liegt daran, dass nicht alle Indikatoren numerische Werte haben, und selbst bei denjenigen, die numerische Werte haben, variiert die Anzahl und das Format der tatsächlichen Zahlen sehr stark. Anders ausgedrückt, es gibt viele Unvergleichbarkeiten, und dies stellt in gewisser Weise unsere Problemstellung dar.
Um die Indikatoren für diese Währungen und Volkswirtschaften nutzen zu können, müssen die Händler in der Lage sein, die numerischen Werte zuverlässig und konsistent zu lesen bzw. den angezeigten Text richtig zu interpretieren. Wir wollen dies anhand einiger typischer Kalenderereignisse veranschaulichen.
![]()
![]()
![]()
![]()
Oben haben wir vier Ereignisse für China, die USA, Japan und Deutschland, die jeweils einen Index, prozentuale Renditen, Geldbeträge und einen nicht definierten Wert erfassen. Diese Informationen können in MQL5 über einfache Methoden extrahiert werden (siehe unten).
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ void SampleRetrieval(string Currency) { MqlCalendarValue _value[]; datetime _stop_date=datetime(__start_date+int(PeriodSeconds(__stop_date_increment))); //--- get events MqlCalendarEvent _event[]; int _events=CalendarEventByCurrency(Currency,_event); printf(__FUNCSIG__+" for Currency: "+Currency+" events are: "+IntegerToString(_events)); // for(int e=0;e<_events;e++) { int _values=CalendarValueHistoryByEvent(_event[e].id, _value, __start_date, _stop_date); // for(int v=0;v<_values;v++) { // printf(__FUNCSIG__+" Calendar Event code: "+_event[e].event_code+", for value: "+TimeToString(_value[v].period)+" on: "+TimeToString(_value[v].time)+", has... "); // if(_value[v].HasPreviousValue()) { printf(__FUNCSIG__+" Previous value: "+DoubleToString(_value[v].GetPreviousValue())); } if(_value[v].HasForecastValue()) { printf(__FUNCSIG__+" Forecast value: "+DoubleToString(_value[v].GetForecastValue())); } if(_value[v].HasActualValue()) { printf(__FUNCSIG__+" Actual value: "+DoubleToString(_value[v].GetActualValue())); } } } }
Nach der Extraktion stellt sich das Problem, wie die extrahierten Werte für die Analyse organisiert und sortiert werden können. Wären unsere numerischen Werte alle standardmäßig, d. h. in einem Bereich von 0 bis 100, wie ein Index, dann wäre ein relativer Vergleich zwischen den Kalenderereignissen einfach, da dies leicht zu einer Einschätzung der relativen Bedeutung der einzelnen Ereignisse führen könnte. Die Analyse muss nun jedoch von einer „dritten Partei“ durchgeführt werden, z. B. Korrelationen zwischen jedem einzelnen Ereignis und den Kursbewegungen einer bestimmten Aktie oder Währung.
Hinzu kommt, dass einige Ereignisse keinen vergleichbaren numerischen Wert haben, wie z. B. die oben für Deutschland dargestellte Rede des Vorstandsmitglieds der Bundesbank.
Noch wichtiger ist jedoch die Textbeschreibung des Ereignisses selbst, mit der ein Händler das Ereignis identifizieren soll. Wenn Sie zum Beispiel ein Devisenpaar wie EURUSD analysieren, sollten Sie EUR-Ereignisse idealerweise mit vergleichbaren USD-Ereignissen vergleichen. Aber wie könnte man solche Ereignisse zusammenführen?

Mit ihren scheinbar vergleichbaren Pendants auf der USD-Seite von:
![]()
und:
![]()
Orientieren wir uns bei der Auswahl des EUR an der Stimmung im Euro oder an der Stimmung in Deutschland? Oder verwenden wir beides mit einer Gewichtung? Aber wenn, welche Gewichte verwenden wir? Welchen der Werte aus Michigan oder Philadelphia verwenden wir auf der USD-Seite?
Daher benötigen wir neben den bereits von MQL5 bereitgestellten Klassifizierungsmöglichkeiten für unsere Ereignisse eine weitere Möglichkeit, die uns nicht nur den einfachen Vergleich numerischer Werte zwischen verschiedenen Volkswirtschaften und Währungen ermöglicht, sondern auch speziell für die Ausführung von Geschäften.
Die bestehenden Klassifizierungsmethoden sind recht rudimentär. Dazu gehören: Auswahl von Ereignissen nach ID, Auswahl von Ereignissen nach Land und Auswahl von Ereignissen nach Währung. Es gibt nur wenige andere Kategorisierungen, die die Werte dieser Ereignisse berücksichtigen, aber sie unterscheiden sich nicht wesentlich von diesen Klassifizierungen. Auch die Auswahl nach Ländern und Währungen schafft Unklarheit, vor allem wegen des EUR, was nicht hilfreich ist. Grundlegende Aspekte, ob das Ereignis rückwärtsgerichtet ist wie ein Index oder vorwärtsgerichtet wie ein Sentiment, fehlen. Außerdem ist die Notwendigkeit, verschiedene Währungen für dasselbe Ereignis zu vergleichen, in einigen Fällen nicht so klar definiert, wie oben am Beispiel des EURUSD-Paares gezeigt.
Konzepte der Kategorientheorie und Datenbankschemata
Um kurz zu rekapitulieren, was wir bisher in der Kategorientheorie behandelt haben, begannen wir mit der Betrachtung der Elemente, der Grundeinheit einer Menge (in früheren Artikeln wurde die Menge als Domäne bezeichnet), betrachteten dann die Mengen, dann die Morphismen mit ihren Typen und schließlich die Komposition mit ihren zahlreichen Eigenschaften und Formen.
Bilder, die eine Annäherung an die Graphentheorie darstellen und das konzeptionelle Layout erfassen, dem die Daten entsprechen, ohne sich vorschnell mit den einzelnen Daten zu befassen, die die Tabellen füllen, könnte man als Datenbankschemata bezeichnen. Datenbanken sind bekanntlich indizierte Speichermedien, die referenzielle Integrität erzwingen und Datenduplikate vermeiden.
Die potenzielle Synergie zwischen Kategorientheorie und Datenbankschemata liegt in der Tatsache, dass Kompositionen der Kategorientheorie einige ihrer Eigenschaften an Datenbankschemata weitergeben können. Wenn wir also damit beginnen, unsere Kalenderereignisse mit einer einfachen Datenbank zu klassifizieren, können wir das Schema ganz einfach durch verschiedene „Linsen“ betrachten, seien es Rückzüge, Graphen, Ordnungen und vieles mehr. Hier ist eine schematische Darstellung der Tabellen, die unsere Kalenderereignisse definieren könnten.
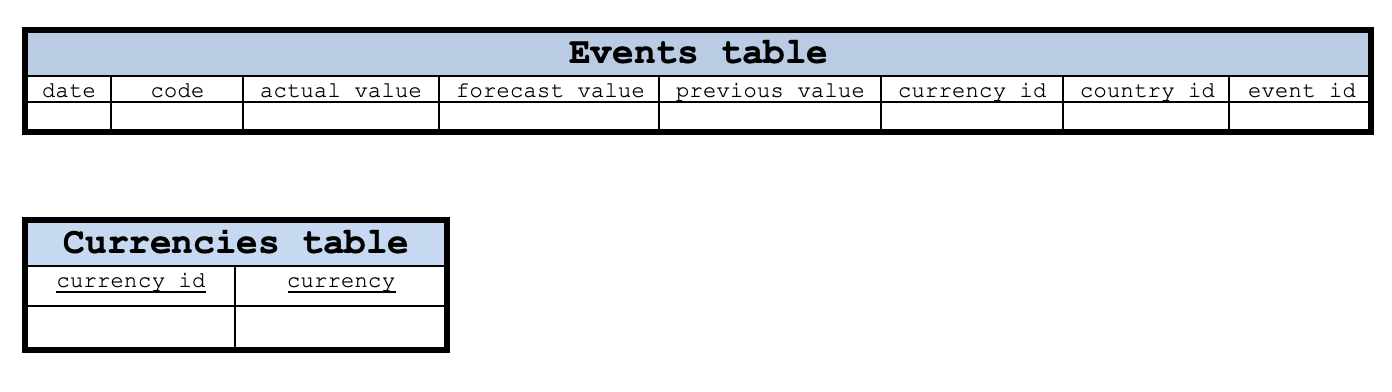
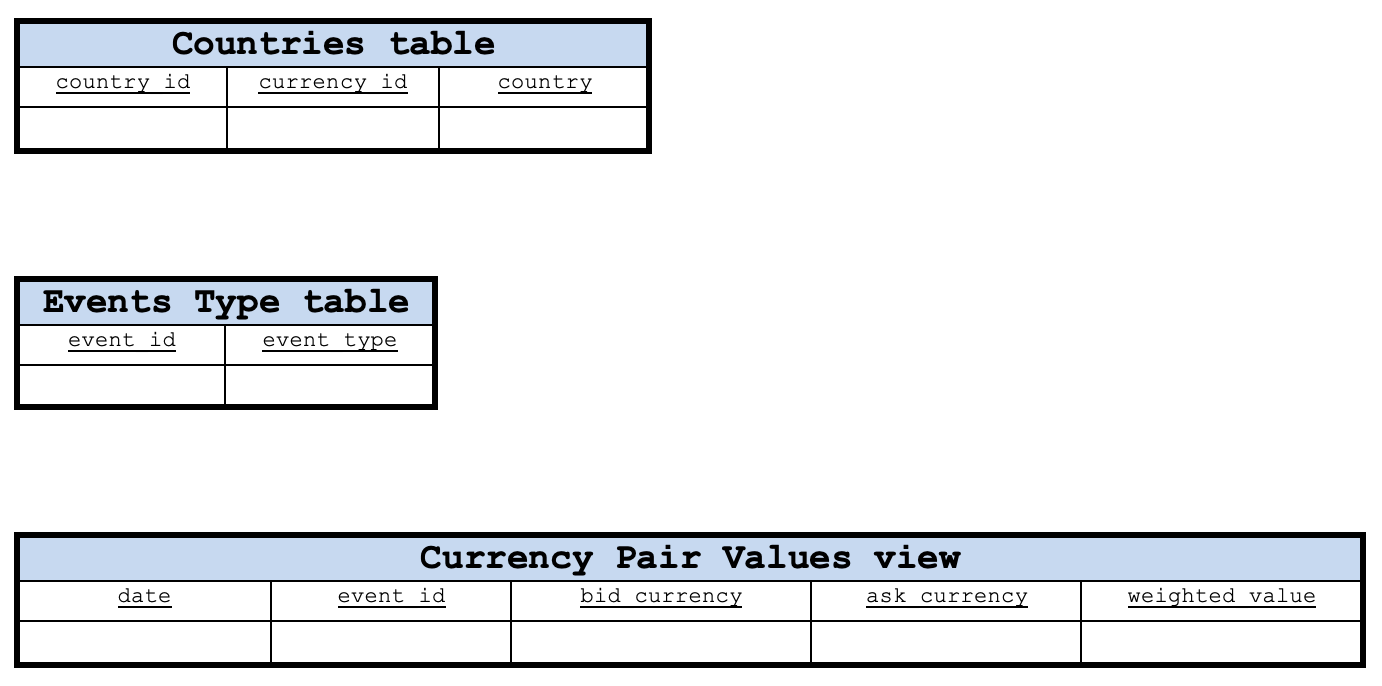
Bei diesem Grundlayout dienen die Spalten date (Datum) und code (Kennzahl) der Ereignistabelle beide als Primärschlüssel. Rufen Sie die Codespalte auf. Die Codespalte enthält die aus den Kalenderereignissen gelesenen Ereigniscodedaten. Die Primärschlüssel von Tabellen des Typs Währungen, Länder und Ereignisse können problemlos als Spalten currencies_id, country_id bzw. event_id angelegt werden. Die Tabelle der Währungspaarwerte muss jedoch die Spalten date und event_id für ihren Primärschlüssel kombinieren.
Die obige Abbildung ist kein Schema, da keine Verbindungen zwischen den Tabellen angegeben sind, sondern zeigt lediglich die Tabellen in unserer Datenbank. Wir können jedoch ein Schema haben, von dem ein Teil unten abgebildet ist.
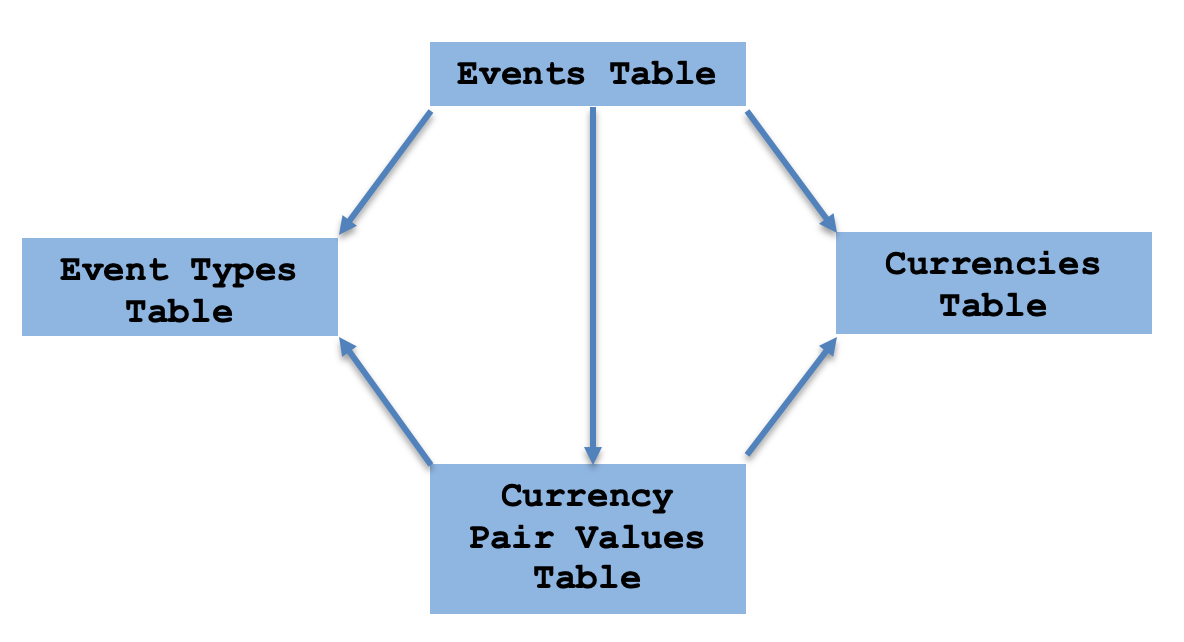
Diese schematische Anordnung kann leicht als kategorientheoretisches Produkt und Koprodukt betrachtet werden. Das bedeutet, dass wir eine universelle Eigenschaft zwischen unserer Ereignistabelle und den Werten der Währungspaare (Sicht (Datenbank)) haben.
Zusammenfassend lässt sich sagen, dass die universelle Eigenschaft des Koprodukts typischerweise bei der Behandlung stückweiser Kurven nützlich ist. Nehmen wir zum Beispiel ein Experiment, bei dem die aufgezeichnete Temperatur in zwei Regionen A und B linear bzw. quadratisch variiert. Um das Temperaturprofil der kombinierten Region A u B zu untersuchen, würde die universelle Eigenschaft des Koprodukts es ermöglichen, die individuellen Temperaturprofile jeder Region in eine Funktion zu kleben, die auf der Grundlage der Kurvendaten ein vernünftiger Näherungswert dafür wäre, was zu erwarten wäre, wenn sich jemand entschließen würde, in diese Region zu reisen, ohne eine klar definierte Reiseroute zu haben.
Für unsere Zwecke als Händler ist die obige Zusammensetzung recht nützlich, da die Ereigniswerte der einzelnen Währungen nie zur gleichen Zeit veröffentlicht werden. Wenn also beispielsweise heute die Stimmungsdaten für den EUR veröffentlicht werden, könnten die für den USD in vierzehn Tagen erscheinen. Wir könnten alte USD-Werte (die neuesten) verwenden, um den Wert des Währungspaares zu ermitteln, aber mit der Kategorientheorie können wir die universelle Eigenschaft nutzen, um den Wert für die Währung zu antizipieren oder vorherzusagen, der nicht aktualisiert wird, trotz eines volatilen Charts.
Implementierung in MQL5
Da unsere Kategorientheorie und Schemata in MQL5 als quadratisches Beziehungen dargestellt werden können, können wir die Klasse „CSquareCommute“ aus früheren Artikeln wie folgt leicht modifizieren:
//+------------------------------------------------------------------+ //| Square Commute Class to illustrate Universal Property | //+------------------------------------------------------------------+ template <typename TA,typename TB,typename TC,typename TD> class CCommuteSquare { public: CHomomorphism<TA,TB> ab; CHomomorphism<TA,TC> ac; CHomomorphism<TD,TB> db; CHomomorphism<TD,TC> dc; CHomomorphism<TD,TA> da; //universal property virtual void SquareAssert() { ab.domain=ac.domain; ab.codomain=db.codomain; dc.domain=db.domain; dc.codomain=ac.codomain; da.domain=db.domain; da.codomain=ac.domain; } CCommuteSquare(){}; ~CCommuteSquare(){}; };
Was wir dem Original hinzugefügt haben, ist einfach ein zusätzlicher Homomorphismus für die universelle Eigenschaft. Damit wäre die nächste wichtige Frage, wie man Elemente für jeden Satz definiert, die die jeweiligen Daten erfassen. Dies könnte für den Ereignissatz (als Ereignistabelle dargestellt) wie unten aufgeführt geschehen:
//sample constructor for event set CElement<string> _e_event;_e_event.Cardinality(7); //
Sobald dieses Element definiert ist, kann der Händler es leicht mit Daten füllen, indem er Listing-1 (siehe oben) oder eine andere geeignete Option verwendet. Ich habe mir nicht die Mühe gemacht, dies hier zu demonstrieren, da ich zuversichtlich bin, dass der Leser eine Methode findet, die seiner Strategie besser entspricht. Sobald ein Element mit Daten gefüllt ist, kann es einfach der entsprechenden Domäne der oben gezeigten commute-Klasse hinzugefügt werden, wie wir in früheren Artikeln behandelt haben. Die Ereigniswerte und sogar die Währungsset-Elemente können auch wie unten gezeigt konstruiert werden:
//sample constructor for type set CDomain<string> _d_type;_d_type.Cardinality(_types); //data population CElement<string> _e_type;_e_type.Cardinality(1); //sample constructor for currency set CDomain<string> _d_currency;_d_currency.Cardinality(_currencies); //data population CElement<string> _e_currency;_e_currency.Cardinality(1);
Daraus ergeben sich dann die Wertelemente des Währungspaares. Mit diesem Set werden Währungen zu einem gemeinsamen gehandelten Paar gepaart, das ein Preischart aufweist, wenn es von der Marktübersicht ausgewählt wird, wobei ein neuer numerischer Wert hinzugefügt wird, der den effektiven Wert des Paares aus der Kombination der beiden Ereigniswerte jeder Währung darstellt. Wenn wir beispielsweise Einzelhandelsumsätze für den Euroraum haben, die der EUR-Währung zugeordnet werden, und Einzelhandelsumsätze für die USA, die dem USD zugeordnet werden, dann würde das Währungspaarwerte-Set das EURUSD-Paar mit seiner effektiven Einzelhandelsumsatzzahl auflisten. Die Auflistung für den Aufbau des Elements ist nachstehend dargestellt:
//sample constructor for values set CDomain<string> _d_values;_d_values.Cardinality(_values); //data population CElement<string> _e_values;_e_values.Cardinality(4);
In diesem Zusammenhang kann man sich die Frage stellen, warum die Ansicht des Währungspaares (in der obigen MQL5-Auflistung sind das die Werte des Währungspaares) von Bedeutung ist? Sie vereinheitlicht die Ereigniswerte zweier Währungen, wie sie im Ereigniskalender angegeben sind, zu einem einzigen Wert für das Währungspaar dieser beiden Währungen. Dieser Einzelwert könnte dann z. B. eine Zeitreihe bilden, die Möglichkeiten für weitere Untersuchungen etwa mit der Preiszeitreihe des Paares oder einer anderen Indikatorreihe dieses Paares bietet.
Um das bisher Erarbeitete zu rekapitulieren: Die Schritte zur Entwicklung und Implementierung dieser Klassifizierung bestehen zunächst darin, die rohen Kalenderereignisse in ein Datenbankschema einzusortieren. Dadurch werden sich wiederholende Texte identifiziert und die Verwendung von Indizes ermöglicht. Ein einfaches Schema, in dem die Ereignistabelle mit allen anderen Tabellen verknüpft ist, könnte für diesen Entwurf verwendet werden.
Mit diesem Entwurf würden wir dann durch die Kalenderereignisse iterieren, die leicht extrahiert werden können, wie in unserem ersten Listing-1 oben gezeigt, und die Werte in unserer Datenbank auffüllen. Ich will das Rad nicht neu erfinden, aber die Klasse für unsere Datenbank mit den dazugehörigen Tabellen, die als Structs dargestellt werden, könnte wie folgt aussehen:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CDatabase { public: STableEvents events; STableEventTypes event_types; STableCountries countries; STableCurrencies currncies; CDatabase(void); ~CDatabase(void); };
Der Unterschied zu SQL besteht darin, dass die Daten im Arbeitsspeicher (RAM) gespeichert werden, der nur vorübergehend zur Verfügung steht, während SQL die Daten in der Regel auf dem Speicherplatz des Computers (Festplatte) speichert. Diese Klasse ermöglicht es uns jedoch, sie in eine bestehende Datenbank zu exportieren, und da die MQL5-IDE über einige Datenbankfunktionen verfügt, könnten Sie diese Werte eventuell aus einer physischen Datenbank statt aus dem RAM lesen, um Rechenressourcen zu sparen.
Sobald wir eine Datenbank haben, würden wir dann unsere quadratische Beziehung aus der oben genannten Klasse konstruieren. Dazu müssen lediglich die Eckensätze wie in der folgenden Abbildung dargestellt definiert werden. Für jedes Set definieren wir seine Elementstruktur, und die Auflistung dafür wurde bereits oben mitgeteilt. Sobald die Elemente definiert sind, werden sie mit Daten aus unserer Datenbank gefüllt und dann zu einer Instanz der Klasse Square Commute hinzugefügt.
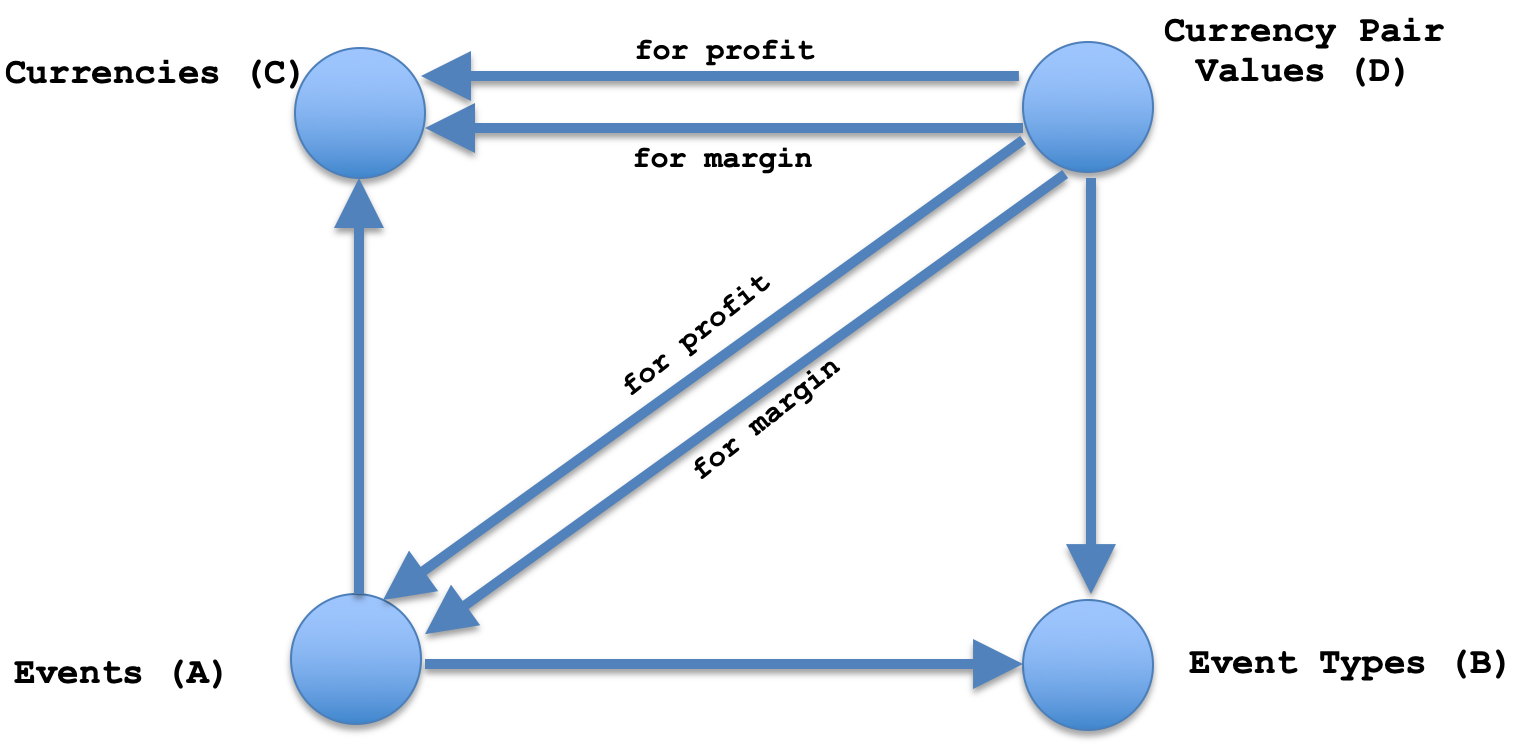
Sobald wir unsere Mengen haben, können wir uns an die Definition der Homomorphismen zwischen diesen Mengen machen. Der Homomorphismus vom Ereignissatz zum Ereignistypensatz würde einfach Ereignisse auf ihren Typ abbilden, was aus Sicht des Datenbankdesigns bedeutet, dass wir nur eine Spalte mit dem Index des Typs in der Ereignistabelle haben könnten, während die tatsächlichen Typen mit ihren Indizes in der Ereignistypentabelle wären und eine Fremdschlüsselbeziehung zwischen den beiden gleichwertig mit unserem Homomorphismus sein würde. Da es sich nicht um eine Datenbank handelt, werden in der Typenmenge einfach alle Typen aufgeführt, die bereits Teil der Ereignismenge sind, jedoch ohne Wiederholung, d. h. unsere Ereignismenge ist die Domäne und die Ereignistypen sind die Codomäne. Der Homomorphismus kann daher leicht anhand der nachstehenden Auflistung definiert werden:
//ab homomorphisms CHomomorphism<string,string> _ab; CElement<string> _e; for(int s=0;s<_sc.ab.domain.Cardinality();s++) { _e.Let(); if(_sc.ab.domain.Get(s,_e)) { string _s=""; if(_e.Get(0,_s)) { CMorphism<string,string> _m; _m.Morph(_sc.ab.domain,_sc.ab.codomain,s,EventType(_s)); _ab.Morphisms(_ab.Morphisms()+1); _ab.Set(_ab.Morphisms()-1,_m); } } }
Ebenso ist der Homomorphismus von Ereignissen zu Währungen eine einfache Abbildung, die mit der nachstehenden Liste realisiert werden kann:
//ac homomorphisms CHomomorphism<string,string> _ac; for(int s=0;s<_sc.ac.domain.Cardinality();s++) { _e.Let(); if(_sc.ac.domain.Get(s,_e)) { string _s=""; if(_e.Get(1,_s)) { CMorphism<string,string> _m; int _c=EventCurrency(_s); if(_c!=-1) { _m.Morph(_sc.ac.domain,_sc.ac.codomain,s,_c); _ac.Morphisms(_ac.Morphisms()+1); _ac.Set(_ac.Morphisms()-1,_m); } } } }
Der springende Punkt sind jedoch die verbleibenden drei Homomorphismen, nämlich die Zuordnung zu den Ereignistypen aus der Menge der Werte der Währungspaare, die Zuordnung zu den Währungen aus der Menge der Währungspaarwerte und schließlich die universelle Eigenschaftszuordnung zu den Währungspaarwerten aus der Menge der Ereignisse. Wenn wir das auspacken, beginnend mit den ersten beiden, die relativ einfach sind, haben wir ein Zurordnen von Währungspaarwerten auf Ereignistypen und auch ein Zuordnen von Währungspaarwerten auf Währungen, was unsere Komposition zu einem Produkt und Koprodukt macht. Es ist erwähnenswert, dass nach den Grundregeln der Homomorphismen ein Element in der Domäne nur auf ein Element in der Codomäne abgebildet werden kann. Dies bedeutet also, dass bei der Betrachtung mehrerer Währungen eine Zuordnung in umgekehrter Richtung nicht möglich ist, da dies dazu führen würde, dass Ereigniswerte auf mehrere Paare abgebildet werden, wenn ein Paar auf seinen Wert verweist, und auch bei den Währungen würde eine Abbildung auf die Werte des Währungspaares ein ähnliches Wiederholungsproblem aufwerfen. Die Umsetzung für die Abbildung auf Ereigniswerte könnte also wie folgt aussehen:
//db homomorphisms CHomomorphism<string,string> _db; for(int s=0;s<_values;s++) { _e.Let(); if(_sc.db.domain.Get(s,_e)) { string _s=""; if(_e.Get(3,_s)) { int _t=TypeToInt(_s); CMorphism<string,string> _m; // _m.Morph(_sc.db.domain,_sc.db.codomain,s,_t); _db.Morphisms(_db.Morphisms()+1); _db.Set(_db.Morphisms()-1,_m); } } }
Ebenso könnte die Zuordnung zu Währungen wie folgt aussehen:
//dc homomorphisms CHomomorphism<string,string> _dc; for(int s=0;s<_values;s++) { _e.Let(); if(_sc.dc.domain.Get(s,_e)) { string _s=""; if(_e.Get(0,_s))//morphisms for margin currency only { int _c=EventCurrency(_s); CMorphism<string,string> _m; // _m.Morph(_sc.dc.domain,_sc.dc.codomain,s,_c); _dc.Morphisms(_dc.Morphisms()+1); _dc.Set(_dc.Morphisms()-1,_m); } } }
Bemerkenswert sind hier die Gewichtungsparameter für die Geld- und die Marginwährung. Diese könnten durch Optimierung oder die relative Gewichtung der Benchmark-Zinssätze der einzelnen Volkswirtschaften oder ihrer Inflationsraten erreicht werden (diese Liste ist nicht erschöpfend). Der Händler muss eine Entscheidung treffen, die von seiner Strategie und seinen Marktaussichten abhängt. Der endgültige Homomorphismus zu den Währungspaarwerten zurück von den Ereignissen würde ein einzelnes Element in den Währungspaarwerten auf zwei Einträge in der Ereignismenge abbilden. Auf der Grundlage der Gewichtung, die für die beiden obigen Zuordnungen verwendet wurde, wird die universelle Eigenschaftszuordnung wie unten dargestellt aufgelistet:
//da homomorphisms CHomomorphism<string,string> _da; for(int s=0;s<_values;s++) { _e.Let(); if(_sc.da.domain.Get(s,_e)) { string _s_c="",_s_t=""; if(_e.Get(0,_s_c) && _e.Get(3,_s_t))// for margin currency { for(int ss=0;ss<_sc.ac.domain.Cardinality();ss++) { CElement<string> _ee; if(_sc.da.codomain.Get(ss,_ee)) { string _ss_c="",_ss_t=""; if(_ee.Get(1,_ss_c) && _ee.Get(6,_ss_t))// for margin currency { if(_ss_c==_s_c && _ss_t==_s_t) { CMorphism<string,string> _m; // _m.Morph(_sc.da.domain,_sc.da.codomain,s,ss); _da.Morphisms(_da.Morphisms()+1); _da.Set(_da.Morphisms()-1,_m); _sc.da=_da; _sc.SquareAssert(); break; } } } } } } } _da.domain=_sc.da.domain; _da.codomain=_sc.da.codomain; _sc.da=_da; _sc.SquareAssert();
Dies wäre somit der letzte Schritt bei der Erzeugung effektiver Gewichte für ein Währungspaar auf der Grundlage von Kalenderereignissen einzelner Währungen.
Kalenderereignisse klassifizieren
Bei der Erstellung der Tabelle der Ereignistypen kann es ratsam sein, eine disziplinierte Methodik anzuwenden, die eine kritische Masse von Daten berücksichtigt, bevor die Ereignistypen festgelegt werden. Die Klassifizierung von Ereignissen ist wichtig, wie in der Problemstellung dargelegt wurde. Daher würde eine mögliche Methodik zur Klassifizierung dieser Ereignisse in vergleichbare Typen Folgendes beinhalten: Datensammlung eine grundlegende Extraktion von Daten unter Verwendung der in MQL5 eingebauten Klassen wurde oben bereits erwähnt; die Gruppierung von Ereignissen würde dann folgen, wobei wir Standardgruppen wie Indizes, Stimmungswerte, Staatsanleihenrenditen, Inflationswerte usw. verwenden könnten. Darauf folgt die Merkmalsextraktion, bei der jedes Ereignis nach Schlüsselwörtern analysiert wird, um festzustellen, zu welcher Gruppe es am besten gehört; dann folgt die Modellschulung und die Bewertung unserer Merkmalsklassifizierung, bei der wir Trainings- und Testdatensätze erstellen und mit der Schulung des Modells beginnen; dann folgt die Prüfung des Modells auf dem Testdatensatz, um zu sehen, wie gut es unsere Ereignisse klassifiziert; und schließlich folgt die Nachanalyse und die iterative Verbesserung, bei der wir nach Möglichkeiten suchen, wie unser Modell feinabgestimmt werden kann, ohne es zu sehr anzupassen.
Sobald unsere Ereignistypen erstellt sind, würden wir diese in unsere Tabelle „event_types“ eintragen, wie im obigen Diagramm dargestellt. Dies würde bedeuten, dass die Spalte „Event type id“ in der Ereignistabelle für alle Ereignisse aktualisiert wird, um ihre Gruppe zuzuordnen. Eine gespeicherte Prozedur, die neue Zeilen einfügt oder Zeilen aktualisiert, kann bei der Implementierung unseres obigen Modells helfen.
Da der Elementdatentyp ein String-Array ist, bei dem jeder Array-Index einer Datenspalte entspricht, würde diese Ergänzung der Ereignismenge bedeuten, dass die einzige signifikante Änderung an unserer obigen Komposition in der Homomorphie von Ereignissen zu Ereigniswerten besteht. Anstatt nur Werte einzubeziehen, deren Beschreibungstext in allen Währungen identisch ist, wie z. B. „Einzelhandelsumsätze“, würden wir nun eine breitere Palette von Ereignissen berücksichtigen.
Informationen für Handelsentscheidungen
Die Erstellung von Währungspaarwerten aus unserer(n) obigen Zusammensetzung(en) bedeutet also, dass wir Währungspaarwerte mit einem Zeitstempel haben. Anhand dieses Zeitstempels können wir die Größenordnung (und in einigen Fällen die Richtung) dieser Werte mit eventuellen Preisänderungen vergleichen. In einem sorgfältigen Analyseprozess, der Trainings- und Testdatensätze umfasst, kann untersucht werden, wie und in welchem Ausmaß die einzelnen Ereignistypen mit der späteren Kursentwicklung korrelieren.
Anhand dieser Daten über die Korrelation von Ereigniswerten mit der nachfolgenden Kursentwicklung können wir nicht nur Regeln für die Platzierung von Geschäften auf der Grundlage der Analyseergebnisse aufstellen, sondern auch die Positionsgröße auf der Grundlage des Ausmaßes der Korrelation festlegen.
Die Genauigkeit eines Systems, das gewichtete Werte von Währungspaaren verwendet, um mögliche Kursbewegungen zu kennzeichnen, könnte verbessert werden, wenn mehrere Ereignisse zu einem gewichteten Durchschnitt zusammengefasst werden und dieser „Indikator“ dann mit den möglichen Kursbewegungen korreliert wird. Dabei stellt sich die Frage, welche Gewichte auf welches Ereignis angewendet werden. Diese Frage könnte durch Optimierung beantwortet werden, oder der Händler könnte sich bei diesem Prozess von seinem eigenen Verständnis der Makroökonomie leiten lassen. Unabhängig davon, welche Methode gewählt wird, führt dieser ganzheitlichere Ansatz zwangsläufig zu genaueren Prognosen.
Fallstudie: Implementierung und Auswertung in MQL5
Der Kürze halber wird dies kein vollständiges Handelssystem sein, sondern nur die ersten Teile davon, die unsere Zusammensetzung berücksichtigen, die, wie bereits erwähnt, aus vier Gruppen besteht: Ereignisse, Typen, Währungen und Werte. Wir werden Kalenderereignisdaten direkt und nicht mit unserer Datenbankklasse abrufen, eine Instanz der Klasse „square commute“ befüllen und ablesen, welche Homomorphismen wir erzeugen können. Auch hier handelt es sich nur um einen ersten Schritt, der lediglich das Potenzial aufzeigen soll, und zu diesem Zweck werden wir hauptsächlich drei Eingaben machen, nämlich die Art des Ereignisses, auf das wir uns konzentrieren, die Gewichtung für die Bid/ Margenwährung und die Gewichtung für die Ask/ Gewinnwährung. Wie bereits erwähnt, dienen diese Gewichte dazu, die Kalenderwerte von zwei Währungen zu einer einzigen zu kombinieren. Bei der Erstellung der Messwerte für diese Studie berücksichtigen wir nur PMI-bezogene Ereignisse und betrachten nur die Währungen EUR, GBP, USD, CHF und JPY sowie Werte nur für die Paare EURUSD, GBPUSD, USDCHF und USDJPY. Der gesamte Code ist am Ende des Artikels beigefügt. Wenn wir Ausdrucke für die universelle Eigenschaft homomorphism ausführen, sollten wir diese Protokolle unten erhalten:
2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) void OnStart() d to a homomorphisms are... 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) {(EUR,USD,45.85000000,TYPE_PMI),(GBP,USD,47.00000000,TYPE_PMI),(USD,CHF,45.05000000,TYPE_PMI),(USD,JPY,48.75000000,TYPE_PMI)} 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) | 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) (EUR,USD,45.85000000,TYPE_PMI)|----->(markit-manufacturing-pmi,EUR,44.60000000,44.60000000,44.80000000,2023.06.01 11:00,TYPE_PMI) 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) | 2023.07.11 13:51:52.966 ct_13 (GBPUSD.i,H1) {(markit-manufacturing-pmi,EUR,44.60000000,44.60000000,44.80000000,2023.06.01 11:00,TYPE_PMI),(markit-manufacturing-pmi,EUR,44.80000000,44.20000000,43.60000000,2023.06.23 11:00,TYPE_PMI),(markit-services-pmi,EUR,55.90000000,55.90000000,55.10000000,2023.06.05 11:00,TYPE_PMI),(markit-services-pmi,EUR,55.10000000,55.50000000,52.40000000,2023.06.23 11:00,TYPE_PMI),(markit-composite-pmi,EUR,53.30000000,53.30000000,52.80000000,2023.06.05 11:00,TYPE_PMI),(markit-composite-pmi,EUR,52.80000000,53.00000000,50.300000
Mit unseren Eingaben, die nur PMI-Ereignisse und die oben vorgewählten Währungen und Paare umfassen, erhalten wir nur einen Morphismus für die Randwährung, die in diesem Fall EUR ist. Unser kombinierter Wert war einfach deshalb höher als der EUR-Eingabewert, weil der entsprechende PMI-Wert für den USD höher war und der ausgegebene Wert für das EURUSD-Paar einfach der gewichtete Durchschnitt war. Für diesen speziellen Test wurden EUR und USD gleich gewichtet.
Schlussfolgerung
Ich habe keine Fallstudie angegeben, um zu zeigen, wie diese Klassifizierung in einem Handelssystem angewendet werden könnte, da der Artikel zu lang geworden wäre, aber ich glaube, es gibt genügend Code und Material in diesem Artikel, um eine eigene Implementierung zu ermöglichen. Zusammenfassend haben wir uns angesehen, wie Kategorientheorie und Datenbankschemata zusammenarbeiten können und nicht nur bei der Klassifizierung von Kalenderereignissen helfen, sondern auch bei der Definition von Zusammensetzungen wie Produkten mit universellen Eigenschaften, die bei der Quantifizierung der Auswirkungen von Kalenderereignissen auf das Preisgeschehen eine wichtige Rolle spielen.
Neben der Standardklassifizierung der Ereignisse, die eine einfache Paarbildung bei Währungspaaren ermöglicht, wird das universelle Eigenschaftsaxiom der Kategorientheorie verwendet, mit dessen Hilfe ein Homomorphismus definiert werden kann, der direkt von der Ereignismenge auf die Menge der Währungspaare abgebildet werden kann (ohne Verwendung der Eckmengen von Ereigniswerten oder Währungen). Dies ermöglicht, wie bereits erwähnt, die Vorhersage des Wertes eines Währungspaares für den Fall, dass nur einer der Ereigniswerte der Währung neu ist und der andere noch Tage oder Wochen auf sich warten lässt.
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/12950
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.