Datenwissenschaft und maschinelles Lernen (Teil 08): K-Means Clustering in reinem MQL5

Daten sind wie Müll, man sollte besser wissen, was man mit ihnen machen will, bevor man sie sammelt
Mark Twain
Unüberwachtes Lernen
Ist ein Paradigma des maschinellen Lernens für Probleme, bei denen die verfügbaren Daten aus unbeschrifteten Beispielen bestehen. Im Gegensatz zu überwachten Lerntechniken wie Regressionsmethoden, SVM, Entscheidungsbäumen, neuronalen Netzen und vielen anderen, die in dieser Artikelserie besprochen werden, haben wir immer gekennzeichnete Datensätze, auf die wir unsere Modelle anpassen. Beim unüberwachten Lernen sind die Daten nicht gekennzeichnet, sodass es dem Algorithmus überlassen bleibt, die Beziehung und alles andere selbst herauszufinden.Beispiele für unüberwachte Lernaufgaben sind Clustering, Dimensionsreduktion und Dichteschätzung.
Clustering-Analyse
Bei der Clustering-Analyse geht es darum, eine Menge von Objekten so zu gruppieren, dass Objekte mit denselben Attributen in dieselben Gruppen (Cluster) eingeordnet werden.
Wenn Sie in ein Einkaufszentrum gehen, werden Sie ähnliche Artikel finden, die zusammen aufbewahrt werden, richtig? Wenn der Datensatz nicht gruppiert ist, wird die Clustering-Analyse genau das tun: Die Datenwerte gruppieren, die einander in gewisser Weise ähnlicher sind als der Rest der Gruppen (Clusters).
Die Clustering-Analyse selbst ist kein spezifischer Algorithmus. Die allgemeine Aufgabe kann durch verschiedene Algorithmen gelöst werden, die sich in ihrem Verständnis dessen, was ein Cluster ist, erheblich unterscheiden.
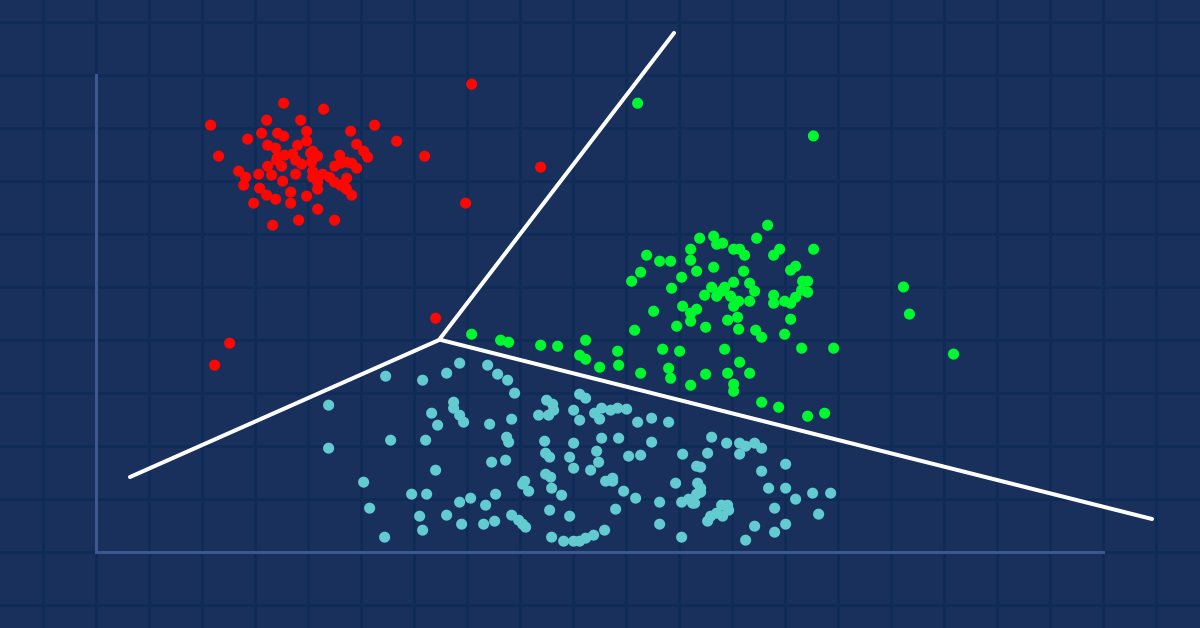
Es gibt drei weithin bekannte Arten von Clustern:
Bildquelle: wikipedia
- Exklusives Clustering
- Überlappendes Clustering
- Hierarchisches Clustering
Exklusives Clustering
Dies ist ein hartes Clustering, bei dem die Datenpunkte exklusiv zugeordnet werden, z. B. das k-means-Clustering.
Überlappendes Clustering
Ist eine Art des Clustering, bei der die Datenpunkte/Elemente zu mehreren Clustern gehören können. Zum Beispiel Fuzzy/c-means-Algorithmus.
Hierarchisches Clustering
Bei dieser Art des Clustering wird versucht, eine Hierarchie von Clustern aufzubauen.
Wo werden Clustering-Algorithmen eingesetzt?
Clustering-Techniken werden von Amazon und vielen anderen E-Commerce-Websites verwendet, um ähnliche Artikel zu empfehlen, die zuvor zusammengebracht wurden. Netflix tut dasselbe, indem es Filme empfiehlt, die zusammen gesehen wurden, basierend auf Interessen.
Grundsätzlich werden sie verwendet, um Gruppen ähnlicher Objekte oder Interessen in einem multivariaten Datensatz zu identifizieren, der aus Bereichen wie Marketing, Biomedizin und Georaum gesammelt wurde.
K-Means-Clustering
Nicht zu verwechseln mit der Nächste-Nachbarn-Klassifikation, der im nächsten Artikel behandelt wird.
Der k-means-Algorithmus ist eine Methode der Vektorquantisierung, die darauf abzielt, n Beobachtungen in k Cluster aufzuteilen, wobei jede Beobachtung zu dem Cluster mit dem nächstgelegenen Mittelwert / nächstgelegenen Schwerpunkt (centroid) gehört, wobei k < n ist.Dies ist der bekannteste und am häufigsten verwendete Clustering-Algorithmus.
Die Mathematik hinter dem Algorithmus ist einfach. Nachfolgend sehen Sie eine Abbildung der am Algorithmus beteiligten Prozesse.

Um zu verstehen, wie dieser Prozess abläuft, führen wir die Operationen manuell und von Hand aus, während wir den Prozess automatisieren, indem wir ihn im Meta-Editor kodieren. Wir erstellen eine Matrix, um die Mittelpunkte für unseren Beispieldatensatz im privaten Bereich der CKMeans-Bibliothek zu speichern.
class CKMeans { private: ulong n; uint m_clusters; ulong m_cols; matrix InitialCentroids; //Intitial Centroids matrix vector cluster_assign; }
Wie immer verwenden wir einen einfachen Datensatz für den Aufbau der Bibliothek und werden dann sehen, wie wir den Algorithmus in einer realen Datensituation einsetzen können.
matrix DMatrix = { {2,10}, {2,5}, {8,4}, {5,8}, {7,5}, {6,4}, {1,2}, {4,9} };
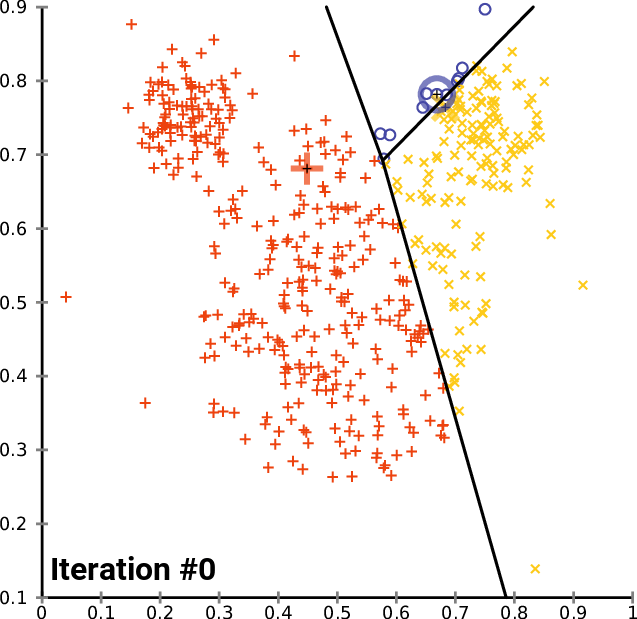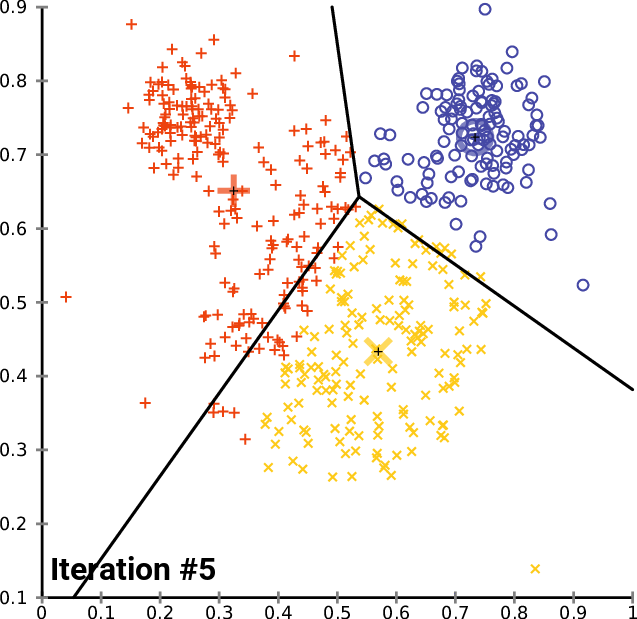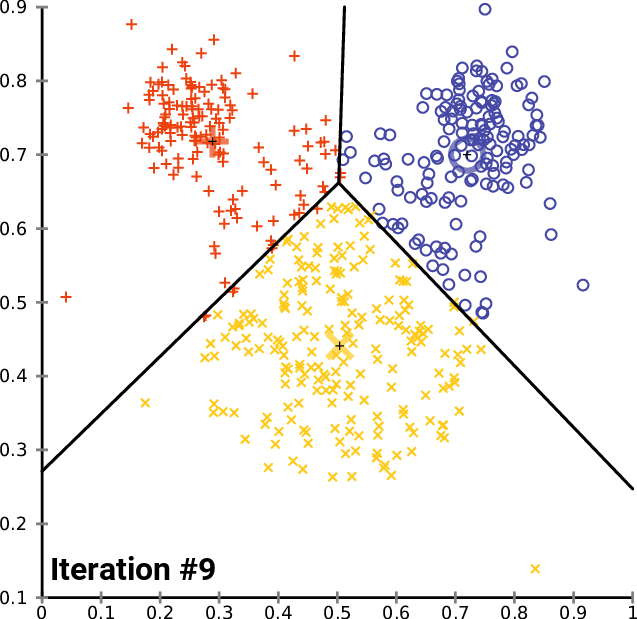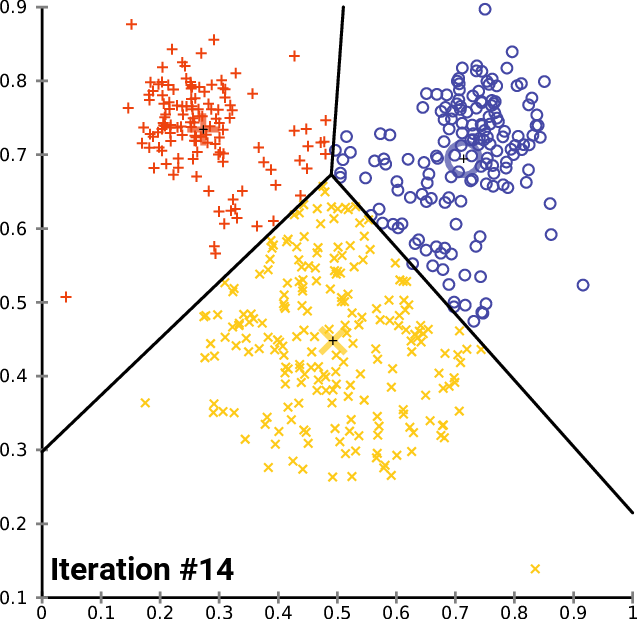
01: Start des Algorithmus & 02: Berechnung des Schwerpunkts (Centroids)
Um den Algorithmus zu starten, benötigen wir die anfänglichen Zentren für jeden der Cluster, nach denen wir suchen, also wählen wir zufällige Zentren und speichern sie in der Matrix InitialCentroid.
m_cols = Matrix.Cols(); n = Matrix.Rows(); //number of elements | Matrix Rows InitialCentroids.Resize(m_clusters,m_cols); vector cluster_comb_v = {}; matrix cluster_comb_m = {}; vector rand_v = {}; for (ulong i=0; i<m_clusters; i++) { rand_v = Matrix.Row(i * m_clusters); InitialCentroids.Row(rand_v,i); } Print("Initial Centroids matrix\n",InitialCentroids);
Hier sind die anfänglichen Schwerpunkte,
CS 0 06:44:02.152 K-means test (EURUSD,M1) Initial Centroids matrix CS 0 06:44:02.152 K-means test (EURUSD,M1) [[2,10] CS 0 06:44:02.152 K-means test (EURUSD,M1) [5,8] CS 0 06:44:02.152 K-means test (EURUSD,M1) [1,2]]
Wir sind mit dem anfänglichen, aber sehr wichtigen Schritt fertig. Der nächste Schritt ist die Berechnung der Schwerpunkte. Moment mal, haben wir nicht gerade den Schwerpunkt berechnet? Das stimmt, wir müssen den Schwerpunkt nicht das erste Mal berechnen, da wir die anfänglichen Schwerpunkte haben.
03: Gruppierung auf Basis des Mindestabstands
Ein Datenpunkt, der einem bestimmten Schwerpunkt am nächsten liegt als alle anderen Schwerpunkte, wird diesem Cluster zugeordnet.
Um den Abstand zu bestimmen, können wir zwei mathematische Formeln verwenden: den euklidischen Abstand oder die Manhattan-Distanz.
Euklidischer Abstand
Dies ist eine Methode zur Messung des Abstands zwischen zwei Punkten auf der Grundlage des Satzes des Pythagoras. Die Formel ist unten angegeben;

Manhattan-Distanz
Der rechtwinklige Abstand ist einfach die Summe der Differenz der x- und y-Koordinaten zwischen zwei Punkten. Ihre Formel lautet wie folgt.

Der Einfachheit halber bevorzuge ich die Manhattan-Distanz, um den Abstand zwischen den Zentren und den Punkten zu ermitteln. Stellen wir die Matrix in Excel dar.

Um die gleichen Ergebnisse im Meta-Editor zu erzielen, müssen wir eine Matrix mit 8 Zeilen und 3 Clustern erstellen, um die geradlinigen Abstände zu speichern, die wir für die Zuordnung der Cluster verwenden werden. Warum drei Cluster? Ich habe mich bei der Initialisierung der Bibliothek für drei Cluster entschieden. Sie können eine beliebige Anzahl von Clustern wählen, je nachdem, was Sie erreichen wollen.
CKMeans::CKMeans(int clusters=3) { m_clusters = clusters; }Im Folgenden wird eine Matrix zum Speichern der geradlinigen Abstände erstellt:
matrix rect_distance = {}; //matrix to store rectilinear distances rect_distance.Reshape(n,m_clusters);
Berechnen wir nun die Manhattan-Distanzen und speichern die Ergebnisse in der soeben erstellten Matrix rect_distance:
vector v_matrix = {}, v_centroid = {}; double output = 0; for (ulong i=0; i<rect_distance.Rows(); i++) for (ulong j=0; j<rect_distance.Cols(); j++) { v_matrix = Matrix.Row(i); v_centroid = InitialCentroids.Row(j); ZeroMemory(output); for (ulong k=0; k<v_matrix.Size(); k++) output += MathAbs(v_matrix[k] - v_centroid[k]); //Rectilinear distance rect_distance[i][j] = output; } Print("Rectilinear distance matrix\n",rect_distance);
Ausgabe:
CS 0 15:17:52.136 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 15:17:52.136 K-means test (EURUSD,M1) [[0,5,9] CS 0 15:17:52.136 K-means test (EURUSD,M1) [5,6,4] CS 0 15:17:52.136 K-means test (EURUSD,M1) [12,7,9] CS 0 15:17:52.136 K-means test (EURUSD,M1) [5,0,10] CS 0 15:17:52.136 K-means test (EURUSD,M1) [10,5,9] CS 0 15:17:52.136 K-means test (EURUSD,M1) [10,5,7] CS 0 15:17:52.136 K-means test (EURUSD,M1) [9,10,0] CS 0 15:17:52.136 K-means test (EURUSD,M1) [3,2,10]]
Wie bereits erwähnt, gruppiert das K-Means-Clustering die Datenpunkte so, dass der Datenpunkt mit dem geringsten Abstand zu einem bestimmten Cluster diesem Cluster zugeordnet wird. In der Matrix rect_distance steht jede Spalte für einen Cluster. Wenn wir uns also den Mindestwert in einer Zeile ansehen, wird die Spalte mit der geringsten Anzahl von allen diesem Cluster zugeordnet (siehe Abbildung unten),

Code für die Zuordnung von Clustern:
//--- Assigning the Clusters matrix cluster_cent = {}; //cluster centroids ulong cluster = 0; for (ulong i=0; i<rect_distance.Rows(); i++) { v_row = rect_distance.Row(i); cluster = v_row.ArgMin(); cluster_assign[i] = (uint)cluster; } Print("Assigned clusters\n",cluster_assign);
Ausgabe:
CS 0 15:17:52.136 K-means test (EURUSD,M1) Assigned clusters CS 0 15:17:52.136 K-means test (EURUSD,M1) [0,2,1,1,1,1,2,1]
Nun, da wir die Punkte ihren jeweiligen Clustern zugeordnet haben, ist es an der Zeit, die Datenpunkte auf der Grundlage der neu gefundenen Cluster zu gruppieren. Wenn wir den Prozess in Excel durchführen, werden die Cluster wie unten auf dem Bild dargestellt:

So einfach die manuelle Gruppierung der Datenpunkte auch war, so schwierig ist sie, wenn wir versuchen, das zu programmieren, weil die Cluster immer unterschiedliche Größen haben werden. Wenn wir also versuchen, die Matrix zum Speichern der Cluster zu verwenden, wird es einen Unterschied in der Anzahl der Zeilen für die Spalten geben. Die Array-Methode ist unbequem und schwer zu lesen, wenn wir versuchen, die CSV-Datei zum Speichern der Werte zu verwenden, wird der Prozess flach fallen, weil wir die Spalten für jeden der Cluster dynamisch schreiben sollen.
Ich kam auf die Idee, die 3 x n clusters_matrix zu verwenden, um die Cluster zu speichern. Dies ist eine Matrix mit Nullwerten, deren Größe zunächst so angepasst wurde, dass die Anzahl der Zeilen der Anzahl der Cluster entspricht und die Anzahl der Spalten auf die größtmögliche Anzahl von Clustern eingestellt ist.
Am Ende wird jeder Cluster horizontal in einer Zeile der Matrix gespeichert.
Hier ist die Ausgabe,
CS 0 15:17:52.136 K-means test (EURUSD,M1) clustered Matrix CS 0 15:17:52.136 K-means test (EURUSD,M1) [[2,10,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] CS 0 15:17:52.136 K-means test (EURUSD,M1) [2,5,1,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] CS 0 15:17:52.136 K-means test (EURUSD,M1) [8,4,5,8,7,5,6,4,4,9,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]Da diese Matrix in der Funktion KMeansClustering, in der all diese Operationen durchgeführt werden, als Referenz übergeben wird, kann sie extrahiert werden, und Sie können die Werte so filtern, dass Sie die Nullwerte nach dem letzten nichtnegativen Nullwert ignorieren.
void CKMeans::KMeansClustering(const matrix &Matrix, matrix &clustered_matrix)
04: Aktualisieren der Schwerpunkte
Die neuen Zentren für jeden Cluster werden durch Ermittlung des Mittelwerts aller einzelnen Elemente im Cluster ermittelt. Hier ist das Codefragment:
vector x_y_z = {0,0}; ZeroMemory(rand_v); for (ulong k=0; k<cluster_cent.Cols(); k++) { x_y_z.Resize(cluster_cent.Cols()); rand_v = cluster_cent.Col(k); x_y_z[k] = rand_v.Mean(); } InitialCentroids.Row(x_y_z, i); if (index >= n_each_cluster.Size()) break; } Print("New Centroids\n",InitialCentroids,"\nclustered Matrix\n",clustered_matrix);
Nachfolgend finden Sie die Ausgabe:
CS 0 15:17:52.136 K-means test (EURUSD,M1) New Centroids CS 0 15:17:52.136 K-means test (EURUSD,M1) [[2,10] CS 0 15:17:52.136 K-means test (EURUSD,M1) [1.5,3.5] CS 0 15:17:52.136 K-means test (EURUSD,M1) [6,6]]
Nun, da wir gesehen haben, wie der gesamte Prozess funktioniert, müssen wir vom zweiten bis zum letzten Schritt wiederholen, bis die Daten gut in die jeweiligen Cluster eingeordnet sind. Dies kann auf zwei Arten erreicht werden: Einige Leute stellen die Logik so ein, dass immer dann, wenn die neuen Zentren für die Cluster aufhören, sich zu ändern, die optimalen Werte für alle Cluster bereits gefunden sind, während andere eine begrenzte Anzahl von Iterationen für diesen Algorithmus festlegen. Ich denke, das Problem mit der ersten Möglichkeit ist, dass wir eine Endlosschleife einfügen müssen, die von der if-Anweisung gesteuert wird, um die Break-Anweisung zu ziehen. Ich halte es für klug, den Algorithmus auf eine bestimmte Anzahl von Iterationen zu beschränken.
Nachfolgend ist die vollständige Funktion des k-means-Clusteralgorithmus mit den hinzugefügten Iterationen dargestellt:
void CKMeans::KMeansClustering(const matrix &Matrix, matrix &clustered_matrix,int iterations = 10) { m_cols = Matrix.Cols(); n = Matrix.Rows(); //number of elements | Matrix Rows InitialCentroids.Resize(m_clusters,m_cols); cluster_assign.Resize(n); clustered_matrix.Resize(m_clusters, m_clusters*n); clustered_matrix.Fill(NULL); vector cluster_comb_v = {}; matrix cluster_comb_m = {}; vector rand_v = {}; for (ulong i=0; i<m_clusters; i++) { rand_v = Matrix.Row(i * m_clusters); InitialCentroids.Row(rand_v,i); } Print("Initial Centroids matrix\n",InitialCentroids); //--- vector v_row; vector n_each_cluster; //Each cluster content matrix rect_distance = {}; //matrix to store rectilinear distances rect_distance.Reshape(n,m_clusters); vector v_matrix = {}, v_centroid = {}; double output = 0; //--- for (int iter=0; iter<iterations; iter++) { printf("\n<<<<< %d >>>>>\n",iter ); for (ulong i=0; i<rect_distance.Rows(); i++) for (ulong j=0; j<rect_distance.Cols(); j++) { v_matrix = Matrix.Row(i); v_centroid = InitialCentroids.Row(j); ZeroMemory(output); for (ulong k=0; k<v_matrix.Size(); k++) output += MathAbs(v_matrix[k] - v_centroid[k]); //Rectilinear distance rect_distance[i][j] = output; } Print("Rectilinear distance matrix\n",rect_distance); //--- Assigning the Clusters matrix cluster_cent = {}; //cluster centroids ulong cluster = 0; for (ulong i=0; i<rect_distance.Rows(); i++) { v_row = rect_distance.Row(i); cluster = v_row.ArgMin(); cluster_assign[i] = (uint)cluster; } Print("Assigned clusters\n",cluster_assign); //--- Combining the clusters n_each_cluster.Resize(m_clusters); for (ulong i=0, index =0, sum_count = 0; i<cluster_assign.Size(); i++) { for (ulong j=0, count = 0; j<cluster_assign.Size(); j++) { //printf("cluster_assign[%d] cluster_assign[%d]",i,j); if (cluster_assign[i] == cluster_assign[j]) { count++; n_each_cluster[index] = (uint)count; cluster_comb_m.Resize(count, m_cols); cluster_comb_m.Row(Matrix.Row(j) , count-1); cluster_cent.Resize(count, m_cols); // New centroids cluster_cent.Row(Matrix.Row(j),count-1); sum_count++; } else continue; } //--- MatrixToVector(cluster_comb_m, cluster_comb_v); // solving for new cluster and updtating the old ones if (iter == iterations-1) clustered_matrix.Row(cluster_comb_v, index); //--- index++; //--- vector x_y_z = {0,0}; ZeroMemory(rand_v); for (ulong k=0; k<cluster_cent.Cols(); k++) { x_y_z.Resize(cluster_cent.Cols()); rand_v = cluster_cent.Col(k); x_y_z[k] = rand_v.Mean(); } InitialCentroids.Row(x_y_z, i); if (index >= n_each_cluster.Size()) break; } Print("New Centroids\n",InitialCentroids);//,"\nclustered Matrix\n",clustered_matrix); } //end of iterations } //+------------------------------------------------------------------+
Nach 10 Iterationen sieht das Algorithmusprotokoll kurz wie folgt aus:
CS 0 20:40:05.438 K-means test (EURUSD,M1) <<<<< 0 >>>>> CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 20:40:05.438 K-means test (EURUSD,M1) [[0,5,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5,6,4] CS 0 20:40:05.438 K-means test (EURUSD,M1) [12,7,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5,0,10] CS 0 20:40:05.438 K-means test (EURUSD,M1) [10,5,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [10,5,7] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9,10,0] CS 0 20:40:05.438 K-means test (EURUSD,M1) [3,2,10]] CS 0 20:40:05.438 K-means test (EURUSD,M1) Assigned clusters CS 0 20:40:05.438 K-means test (EURUSD,M1) [0,2,1,1,1,1,2,1] CS 0 20:40:05.438 K-means test (EURUSD,M1) New Centroids CS 0 20:40:05.438 K-means test (EURUSD,M1) [[2,10] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,3.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [6,6]] CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) <<<<< 1 >>>>> CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 20:40:05.438 K-means test (EURUSD,M1) [[0,7,8] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5,2,5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [12,7,4] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5,8,3] CS 0 20:40:05.438 K-means test (EURUSD,M1) [10,7,2] CS 0 20:40:05.438 K-means test (EURUSD,M1) [10,5,2] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9,2,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [3,8,5]] CS 0 20:40:05.438 K-means test (EURUSD,M1) Assigned clusters CS 0 20:40:05.438 K-means test (EURUSD,M1) [0,1,2,2,2,2,1,0] CS 0 20:40:05.438 K-means test (EURUSD,M1) New Centroids CS 0 20:40:05.438 K-means test (EURUSD,M1) [[3,9.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,3.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [6.5,5.25]] CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) <<<<< 2 >>>>> CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 20:40:05.438 K-means test (EURUSD,M1) [[1.5,7,9.25] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5.5,2,4.75] CS 0 20:40:05.438 K-means test (EURUSD,M1) [10.5,7,2.75] CS 0 20:40:05.438 K-means test (EURUSD,M1) [3.5,8,4.25] CS 0 20:40:05.438 K-means test (EURUSD,M1) [8.5,7,0.75] CS 0 20:40:05.438 K-means test (EURUSD,M1) [8.5,5,1.75] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9.5,2,8.75] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,8,6.25]] CS 0 20:40:05.438 K-means test (EURUSD,M1) Assigned clusters CS 0 20:40:05.438 K-means test (EURUSD,M1) [0,1,2,0,2,2,1,0] CS 0 20:40:05.438 K-means test (EURUSD,M1) New Centroids CS 0 20:40:05.438 K-means test (EURUSD,M1) [[3.666666666666667,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,3.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7,4.333333333333333]] CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) <<<<< 3 >>>>> CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 20:40:05.438 K-means test (EURUSD,M1) [[2.666666666666667,7,10.66666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5.666666666666666,2,5.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9.333333333333334,7,1.333333333333333] CS 0 20:40:05.438 K-means test (EURUSD,M1) [2.333333333333333,8,5.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7.333333333333334,7,0.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7.333333333333334,5,1.333333333333333] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9.666666666666666,2,8.333333333333332] CS 0 20:40:05.438 K-means test (EURUSD,M1) [0.3333333333333335,8,7.666666666666667]] CS 0 20:40:05.438 K-means test (EURUSD,M1) Assigned clusters CS 0 20:40:05.438 K-means test (EURUSD,M1) [0,1,2,0,2,2,1,0] CS 0 20:40:05.438 K-means test (EURUSD,M1) New Centroids CS 0 20:40:05.438 K-means test (EURUSD,M1) [[3.666666666666667,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,3.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7,4.333333333333333]] CS 0 20:40:05.438 K-means test (EURUSD,M1) ..... ..... ..... ..... CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) <<<<< 9 >>>>> CS 0 20:40:05.438 K-means test (EURUSD,M1) CS 0 20:40:05.438 K-means test (EURUSD,M1) Rectilinear distance matrix CS 0 20:40:05.438 K-means test (EURUSD,M1) [[2.666666666666667,7,10.66666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [5.666666666666666,2,5.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9.333333333333334,7,1.333333333333333] CS 0 20:40:05.438 K-means test (EURUSD,M1) [2.333333333333333,8,5.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7.333333333333334,7,0.666666666666667] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7.333333333333334,5,1.333333333333333] CS 0 20:40:05.438 K-means test (EURUSD,M1) [9.666666666666666,2,8.333333333333332] CS 0 20:40:05.438 K-means test (EURUSD,M1) [0.3333333333333335,8,7.666666666666667]] CS 0 20:40:05.438 K-means test (EURUSD,M1) Assigned clusters CS 0 20:40:05.438 K-means test (EURUSD,M1) [0,1,2,0,2,2,1,0] CS 0 20:40:05.438 K-means test (EURUSD,M1) New Centroids CS 0 20:40:05.438 K-means test (EURUSD,M1) [[3.666666666666667,9] CS 0 20:40:05.438 K-means test (EURUSD,M1) [1.5,3.5] CS 0 20:40:05.438 K-means test (EURUSD,M1) [7,4.333333333333333]]
Dies bringt uns zu dem Punkt, wie viele Iterationen für diese Art von Algorithmus am besten geeignet sind. Im Gegensatz zum Gradientenabstieg und anderen Algorithmen benötigt das k-means Clustering nicht viele Iterationen, um die optimalen Werte zu erreichen, es braucht oft 5 bis 10 Iterationen, um den einfachen Datensatz vollständig zu clustern.
Innerhalb des K-Means-Test-Skripts
In der Hauptfunktion des Testskripts initialisieren wir die Bibliothek, rufen die Funktion k-MeansClustering auf, zeichnen die Cluster auf derselben Achse und löschen schließlich das Objekt für die Bibliothek. void OnStart() { //--- matrix DMatrix = { {2,10}, {2,5}, {8,4}, {5,8}, {7,5}, {6,4}, {1,2}, {4,9} }; int clusters =3; matrix clusterd_mat; clustering = new CKMeans(clusters); clustering.KMeansClustering(DMatrix,clusterd_mat); ObjectsDeleteAll(0,0); ScatterPlotsMatrix("graph",clusterd_mat,"cluster 1"); delete(clustering); }
unten ist der Plot der Cluster:

Toll, in der Funktion ScatterPlotsMatrix() wurde die Funktion zum Filtern der Nullwerte aufgerufen, bevor die Werte in das Diagramm eingezeichnet werden konnten. Alle Werte, die genau auf der x- oder y-Achse liegen, sollten ignoriert werden.
vectortoArray(x,x_arr); FilterZeros(x_arr); graph.CurveAdd(x_arr,CURVE_POINTS," cluster "+string(i+1));
Was ist die richtige Anzahl von k Clustern?
Wir verstehen jetzt, wie der Algorithmus funktioniert, aber wir können die Hauptfunktion des k-means-Clusters aufrufen und die Anzahl der Cluster eingeben, und das war's. Woher wissen wir, dass die Anzahl der Cluster, die wir ausgewählt haben, die optimale ist? Weil dieser Algorithmus von Initialisierungen beeinflusst wird? Um das zu verstehen, schauen wir uns etwas an, das sich „Ellenbogenmethode“ nennt.
Die Ellbogenmethode
Die Ellbogen-Methode wird verwendet, um die optimale Anzahl von Clustern im k-means-Clustering zu finden. Die Ellbogen-Methode stellt den Graphen einer Kostenfunktion dar, die durch verschiedene Werte von Clustern (k) erzeugt wurde.
Mit zunehmender Anzahl von k nimmt die Kostenfunktion ab, was als Overfitting bezeichnet werden kann.
Bei der Analyse des Ellenbogendiagramms kann man einen Punkt erkennen, an dem sich die Richtung des Diagramms schnell ändert, und danach beginnt sich das Diagramm parallel zur x-Achse zu bewegen.

WCSS
Die Summe der quadrierten Residuen innerhalb des Clusters (WCSS) ist die Summe des quadrierten Abstands zwischen jedem Punkt und dem Schwerpunkt des Clusters.
Ihre Formel lautet wie folgt.

Da die Ellbogen-Methode eine Optimierungsmethode für das K-Means-Clustering ist, muss bei jeder ihrer Iterationen die K-Mean-Clustering-Funktion aufgerufen werden.
Um nun die Ellbogen-Methode auszuführen und die Ergebnisse zu erhalten, müssen wir einige Dinge in der Hauptfunktion für das k-Mittel-Clustering ändern. Der erste Punkt, den wir ändern müssen, ist die Ermittlung der Schwerpunkte, denn wenn die Anzahl der ausgewählten Cluster der Anzahl der Zeilen in der Matrix entspricht oder auch nur annähernd, dann greift die Methode der zufälligen Auswahl des anfänglichen Schwerpunkts zu kurz.
for (ulong i=0; i<m_clusters; i++) { rand_v = Matrix.Row(i); InitialCentroids.Row(rand_v,i); }
Wir müssen auch die Logik für die größte Anzahl von anfänglichen Clustern ändern, um die Anzahl von n Stichproben im Datensatz nicht zu überschreiten, wie aus der Definition von k-means clustering hervorgeht, dass k < n ist.
void CKMeans::ElbowMethod(const int initial_k=1, int total_k=10, bool showPlot = true) { matrix clustered_mat, _centroids = {}; if (total_k > (int)n) total_k = (int)n; //>>k should always be less than n
Nachstehend finden Sie den vollständigen Code für die Elbogenmethode:
void CKMeans::ElbowMethod(const int initial_k=1, int total_k=10, bool showPlot = true) { matrix clustered_mat, _centroids = {}; if (total_k > (int)n) total_k = (int)n; //k should always be less than n vector centroid_v={}, x_y_z={}; vector short_v = {}; //vector for each point vector minus_v = {}; //vector to store the minus operation output double wcss = 0; double WCSS[]; ArrayResize(WCSS,total_k); double kArray[]; ArrayResize(kArray,total_k); for (int k=initial_k, count_k=0; k<ArraySize(WCSS)+initial_k; k++, count_k++) { wcss = 0; m_clusters = k; KMeansClustering(clustered_mat,_centroids,1); for (ulong i=0; i<_centroids.Rows(); i++) { centroid_v = _centroids.Row(i); x_y_z = clustered_mat.Row(i); FilterZero(x_y_z); for (ulong j=0; j<x_y_z.Size()/m_cols; j++) { VectorCopy(x_y_z,short_v,uint(j*m_cols),(uint)m_cols); //--- WCSS ( within cluster sum of squared residuals ) minus_v = (short_v - centroid_v); minus_v = MathPow(minus_v,2); wcss += minus_v.Sum(); } } WCSS[count_k] = wcss; kArray[count_k] = k; } Print("WCSS"); ArrayPrint(WCSS); Print("kArray"); ArrayPrint(kArray); //--- Plotting the Elbow on the graph if (showPlot) { ObjectDelete(0,"elbow"); ScatterCurvePlots("elbow",kArray,WCSS,WCSS,"Elbow line","k","WCSS"); } }
Nachfolgend sehen Sie die Ausgabe des obigen Codeblocks:

Betrachtet man das Ellbogen-Diagramm, so wird deutlich, dass die optimale Anzahl von Clustern bei 3 liegt. Die WCSS-Werte sind an diesem Punkt drastisch gesunken, von 51,4667 auf 14,333.
Okay, damit haben wir alles, was wir brauchen, um den k-means Clustering-Algorithmus in MQL5 zu implementieren. Sehen wir uns also an, wie wir den Algorithmus in der Handelsumgebung implementieren können.
Schauen wir uns an, wie wir dieselben Marktpreisdaten in mehrere Cluster einteilen können:
matrix DMatrix = {}; DMatrix.Resize(bars, 1); //columns determines the dimension of the dataset 1D won't be visualized properly vector column_v = {}; column_v.CopyRates(symbol,PERIOD_CURRENT,COPY_RATES_CLOSE,1,bars); DMatrix.Col(column_v,0);
Wir haben soeben die Matrix durch die nx1-Matrix für die Marktpreiswerte ersetzt. Diesmal haben wir eine eindimensionale Matrix verwendet, und entsprechend der Art und Weise, wie wir den Clustering-Algorithmus kodiert haben, werden eindimensionale Matrizen nicht gut visualisiert und geclustert, z.B.: Sehen Sie das Ergebnis der gesamten Clustering-Operation für das NASDAQ-Symbol für 20 Balken auf den Grafiken unten.

Die 4 Cluster, die nach der Ellbogenmethode am besten in das Diagramm über den Clustern passen, sehen viel besser aus, wenn sie in das Diagramm eingetragen werden,

Setzen wir nun die Werte für dasselbe Symbol in eine 3D-Matrix ein und sehen wir, was mit den Clustern passiert.
matrix DMatrix = {}; DMatrix.Resize(bars, 3); //columns determines the dimension of the dataset 1D won't be visualized properly vector column_v = {}; ulong start = 0; for (ulong i=0; i<2; i++) { column_v.CopyRates(symbol,PERIOD_CURRENT,COPY_RATES_CLOSE,start,bars); DMatrix.Col(column_v,i); start += bars; }
Nachfolgend sehen Sie, wie die Cluster auf dem Diagramm aussehen werden:

Es scheint, dass die dreidimensionale Matrix, wenn sie auf der gleichen Achse geclustert wird, eine Menge Ausreißer in den Clustern aufweist.
Ich kann mir vorstellen, eine Matrix mit mehr als einer Dimension zu verwenden, wenn ich versuche, verschiedene Stichproben zu clustern, deren Werte auf verschiedenen Ebenen/Skalen liegen, z. B. die RSI-Indikatorwerte und die Werte des gleitenden Durchschnittsindikators, aber diese Werte insgesamt in eine eindimensionale Matrix zu stecken, d. h. in eine Spalte einer Matrix, ist ideal; Sie können das gerne erforschen und mit allen im Diskussionsbereich teilen.
Eine Sache, die ich vergessen habe zu erwähnen, bevor ich die Bilder für die Diagramme gezeigt habe, ist, dass ich die NASDAQ-Kurswerte mit der Technik der Mean-Normalization normalisiert habe.
MeanNormalization(DMatrix);
Dadurch werden die Daten auf dem Diagramm gut verteilt. Nachstehend finden Sie den vollständigen Code:
void MeanNormalization(matrix &mat) { vector v = {}; for (ulong i=0; i<mat.Cols(); i++) { v = mat.Col(i); MeanNormalization(v); mat.Col(v,i); } } //+------------------------------------------------------------------+ void MeanNormalization(vector &v) { double mean = v.Mean(), max = v.Max(), min = v.Min(); for (ulong i=0; i<v.Size(); i++) v[i] = (v[i] - mean) / (max - min); }
Abschließende Überlegungen
Das k-means Clustering ist ein sehr nützlicher Algorithmus, der in der Toolbox jedes Händlers und Datenwissenschaftlers vorhanden sein sollte. Es ist zu beachten, dass dieser Algorithmus stark von Initialisierungen beeinflusst wird. Wenn man die Suche nach dem optimalen Algorithmus mit der Elbow-Methode beginnt, indem man mit 2 Clustern startet, kann es sein, dass man zu einer anderen optimalen Anzahl von Clustern gelangt als derjenige, der als Ausgangscluster 4 gewählt hat. Auch die anfänglichen Schwerpunkte spielen eine große Rolle, weshalb ich die Eingabe in die Haupt-Clustering-Funktion hinzufügen musste, um die Wahl zu erleichtern, ob die anfänglichen Schwerpunkte zufällig ausgewählt werden sollen oder stattdessen die ersten drei Zeilen der Matrix ausgewählt werden sollen.void CKMeans::KMeansClustering(matrix &clustered_matrix,matrix ¢roids,int iterations = 1,bool rand_cluster =false)
Das Funktionsargument rand_cluster für die zufällige Auswahl des Schwerpunkts ist standardmäßig auf false gesetzt. Dies soll helfen, wenn die K-Means-Clustering-Funktion im Rahmen der Elbow-Methode aufgerufen wird, da die Auswahl zufälliger Schwerpunkte bei der Suche nach optimalen Clustern nicht gut funktioniert. Aber es funktioniert gut, wenn die Anzahl der Cluster bekannt ist.
Mit freundlichen Grüßen.
Die in diesem Artikel verwendeten mql5-Codedateien sind unten angehängt. Der Code in den Zip-Dateien hat sich gegenüber dem oben vorgestellten Code geringfügig geändert, einige Zeilen wurden aus Leistungsgründen entfernt, während andere nur hinzugefügt wurden, um den gesamten Prozess leichter verständlich zu machen.
GITHUB REPO >> https://github.com/MegaJoctan/Data-Mining-MQL5
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/11615
 Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 29): Die sprechende Plattform
Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 29): Die sprechende Plattform
 Lernen Sie, wie man ein Handelssystem mit den Fraktalen entwickelt
Lernen Sie, wie man ein Handelssystem mit den Fraktalen entwickelt
 Lernen Sie, wie man ein Handelssystem mit dem Alligator entwickelt
Lernen Sie, wie man ein Handelssystem mit dem Alligator entwickelt
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.