Нейросети — это просто (Часть 55): Контрастный внутренний контроль (CIC)

Введение
В предыдущих статьях мы уже обсуждали преимущества использования иерархических моделей. Мы рассматривали методы обучения моделей, способные извлекать и выделять отдельные навыки Агента. Полученные навыки могут быть полезны для достижения конечной цели поставленной задачи. Примерами таких алгоритмов могут быть DIAYN, DADS, EDL. Указанные алгоритмы по-разному подходят к процессу обучения навыков, но все они были использованы для задач дискретного пространства действий. Сегодня мы поговорим ещё об одном подходе к изучению навыков Агента и посмотрим на его применение в области решения задач непрерывного пространства действий.
1. Основные компоненты CIC
В практике обучения с подкреплением широко используются алгоритмы предварительного обучения Агентов с помощью самоконтролируемых внутренних вознаграждений. Подобные алгоритмы можно условно разделить на 3 категории: основанные на компетенциях, знаниях и данных. Тесты в Unsupervised Reinforcement Learning Benchmark демонстрируют, что алгоритмы, основанные на компетенциях, уступают другим категориям.
Алгоритмы, использующие компетенции, стремятся максимизировать взаимную информацию между наблюдаемыми состояниями и латентным вектором навыков. Эта взаимная информация оценивается через модель Дискриминатора. Обычно, в качестве Дискриминатора используется модель классификатора или регрессора. Однако для достижения точности в задачах классификации и регрессии требуется огромное количество разнообразных обучающих данных. В простых средах, где количество потенциальных вариантов поведения ограничено, методы, основанные на компетенциях, демонстрирую свою эффективность. Но в средах с множеством потенциальных поведенческих вариантов их эффективность значительно снижается.
Сложные среды подразумевают наличие большого числа разнообразных навыков. И для их обработки необходим Дискриминатор с большой мощностью. Противоречие между этим требованием и ограниченными возможностями существующих Дискриминаторов подтолкнуло к созданию метода Contrastive Intrinsic Control (CIC).
Contrastive Intrinsic Control представляет собой новый подход к контрастной оценке плотности для приближения условной энтропии Дискриминатора. Метод оперирует переходами между состояниями и векторами навыков. Что позволяет применять мощные методы обучения представлений от обработки визуальных данных до выявления навыков. Предложенный метод позволяет увеличить стабильность и эффективность обучения Агента в разнообразных средах.
Алгоритм Contrastive Intrinsic Control начинается с обучения Агента в среде с помощью обратной связи и получения траекторий состояний и действий. Затем выполняется обучение представлений с использованием Contrastive Predictive Coding (CPC), что мотивирует Агента выделять ключевые признаки из состояний и действий. Формируются представления, учитывающие зависимости между последовательными состояниями.
Важную роль играет внутреннее вознаграждение, определяющая какие поведенческие стратегии следует максимизировать. В CIC максимизируется энтропия переходов между состояниями, что способствует разнообразию поведения Агента. Это позволяет Агенту исследовать и создавать разнообразные поведенческие стратегии.
После формирования разнообразных навыков и стратегий, алгоритм CIC использует Дискриминатор для конкретизации представлений навыков. Дискриминатор направлен на то, чтобы состояния были предсказуемыми и устойчивыми. Таким образом, Агент учится "использовать" навыки в предсказуемых ситуациях.
Комбинация исследования, мотивируемого внутренними вознаграждением, и использование навыков для предсказуемых действий создает сбалансированный подход для создания разнообразных и эффективных стратегий.
В результате алгоритм Contrastive Predictive Coding стимулирует Агента к обнаружению и усвоению широкого спектра поведенческих стратегий, обеспечивая при этом стабильное обучение. Ниже представлена авторская визуализация алгоритма.

Более подробно мы познакомимся с алгоритмом в процессе реализации.
2. Реализация средствами MQL5
Приступая к своей реализации алгоритма Contrastive Predictive Coding средствами MQL5 мы должны определить некоторые ключевые моменты. Во-первых, алгоритм обучения модели разбивается на 2 крупных этапа:
- обучение навыков без внешнего вознаграждения от окружающей среды;
- обучение политики решения поставленной задачи на основе внешнего вознаграждения.
Во-вторых, в процессе обучения Дискриминатора изучает соответствие переходов между состояниями и навыков. И здесь надо обратить внимание, что мы оперируем именно изменением состояния. Не внешним вознаграждением за переход в новое состояние. И не действием приведшим в это состояние. Если проводить аналогии с ранее рассмотренными алгоритмами, которые оперировали с этими же данными, то DIAYN на основании исходного и нового состоянии модель определяла навык. В DADS, наоборот, на основании исходного состояния и навыка Дискриминатор прогнозировал следующее состояния. В данном же методе мы определяем контрастную ошибку между переходом (исходным и последующим состоянием) и навыком, используемым Агентом. При этом формируются латентные представления состояний и навыков. Именно Дискриминатор оказывает влияние на обучения кодировщика состояний, который впоследствии используется Агентом и планировщиком. И это отражается в архитектуре используемых нами моделей. Именно это сподвигло нас вынести Энкодер состояния окружающей среды в отдельную модель.
2.1 Описание архитектуры моделей
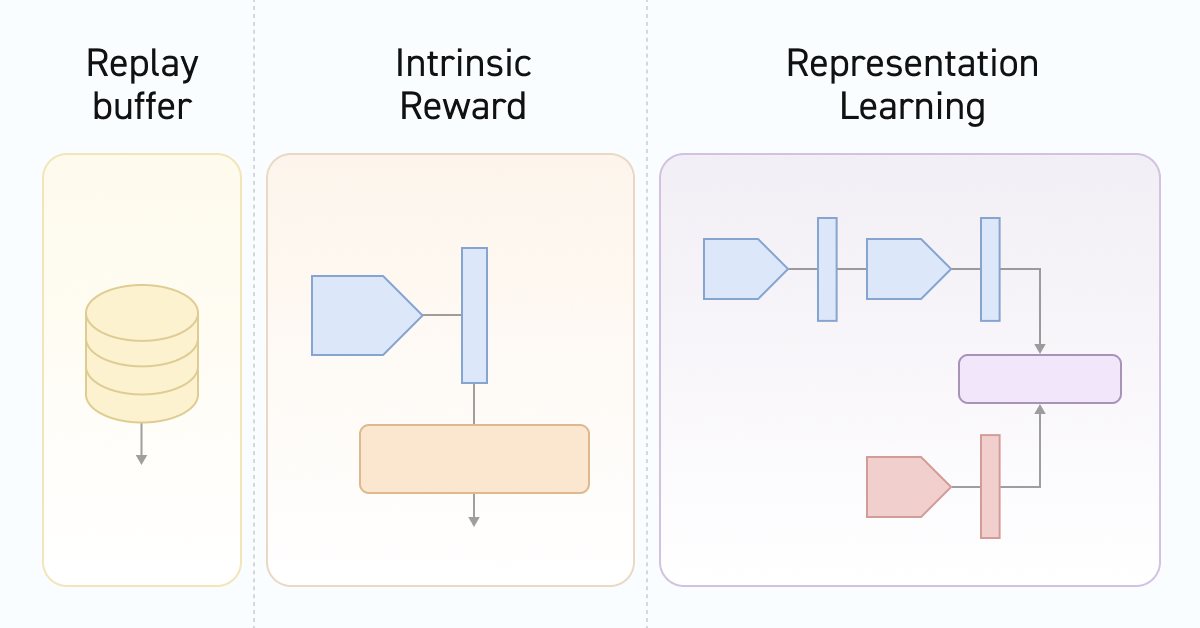
И так мы плавно подходим к методу описания архитектур используемых моделей CreateDescriptions. В параметрах данного метода мы видим указатели на массивы описания архитектур 6 моделей, о назначении которых мы поговорим в процессе их описания.
bool CreateDescriptions(CArrayObj *state_encoder, CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution, CArrayObj *descriminator, CArrayObj *skill_project ) { //--- CLayerDescription *descr; //--- if(!state_encoder) { state_encoder = new CArrayObj(); if(!state_encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } if(!skill_project) { skill_project = new CArrayObj(); if(!skill_project) return false; }
Первым у нас идет модель энкодера состояний окружающей среды. Выше мы уже начали разговор о функционале данной модели. Как вы знаете, состояние окружающей среды у нас состоит из 2 блоков: исторических данных и состояния счета. Оба этих тензора мы будем подавать на вход нашего энкодера. Архитектура данной модели вам напомнит блок предварительной обработки исходных данных, ранее используемый в моделях Актеров.
bool CreateDescriptions(CArrayObj *state_encoder, CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution, CArrayObj *descriminator, CArrayObj *skill_project ) { //--- CLayerDescription *descr; //--- if(!state_encoder) { state_encoder = new CArrayObj(); if(!state_encoder) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } if(!descriminator) { descriminator = new CArrayObj(); if(!descriminator) return false; } if(!skill_project) { skill_project = new CArrayObj(); if(!skill_project) return false; } //--- State Encoder state_encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = 8; descr.step = 8; descr.window_out = 8; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!state_encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = NSkills; descr.window = prev_count; descr.step = AccountDescr; descr.optimization = ADAM; descr.activation = SIGMOID; if(!state_encoder.Add(descr)) { delete descr; return false; }
Следующей рассмотрим архитектуру Актера. Это все таже модель. Только мы исключаем блок предварительной обработки исходных данных, который был вынесен в отдельный Энкодер. Но есть одна деталь. Мы добавляем ещё один тензор исходных данных, который описывает используемый навык.
И чтобы политики поведения Актера при использовании различных навыков были четко разделимы мы отказываемся от использования стохастичных политик.
//--- Actor actor.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NSkills; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Как обычно, после Актера мы описываем архитектуру Критика. И здесь нам стоит задуматься над его функционалом. На первый взгляд вопрос довольно прозаичный. Критик оценивает ожидаемое вознаграждение за переход в новое состояние. И вознаграждение за конкретный переход зависит от осуществляемого действия, а не используемого навыка. Конечно, действие выбирается Актером исходя из указанного навыка. Но ведь окружающей среде все равно какими мотива руководствовался Агент. Она реагирует на его воздействие.
С другой стороны, Критик дает оценку политики Актера и прогнозирует ожидаемое вознаграждение последующего использования данной политики. А политики Актера напрямую зависит от используемого навыка. Поэтому, в исходных данных Критику нам необходимо передать текущее состояние окружающей среды, используемый навык и выбранное действие Актера. И здесь мы будем использовать уже отработанный ранее прием. Мы возьмем латентное состояние Актера, которое уже учитывает описание состояния окружающей среды и используемый навык. И добавим выбранное Актером действие. Таким образом, архитектура Критика осталась без изменений. Но изменился идентификатор латентного состояния Актера.
И ещё мы отказались от декомпозиции функции вознаграждения. Это вынужденная мера. Как уже было сказано, обучать модель мы будем 2 этапа. И на каждом этапе мы будем использовать разную функцию вознаграждения. И перед нами стал выбор. Использовать декомпозицию вознаграждения и обучать 2 различных Критика на каждом этапе. Или отказаться от декомпозиции вознаграждения, но использовать одного и того же Критика на обоих этапах. Мы решили пойти по второму пути.
//--- Critic critic.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = LReLU; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NRewards; descr.optimization = ADAM; descr.activation = None; if(!critic.Add(descr)) { delete descr; return false; }
Далее мы внесли свое видение в оптимизацию алгоритма. Дело в том, что в качестве внутреннего вознаграждения авторы метода предлагают использовать энтропию переходов с использование метода частиц от k ближайших соседей, как мы делали в предыдущей статье. Только авторы использовали расстояние между переходами из мини-пакета в представлении обучаемого энкодера. И для этого нам потребуется на каждой итерации обновления параметров осуществлять кодировку некоторого пакета переходов. Мы не можем один раз осуществить кодировку мини-пакета и использовать это представление в процессе обучения. Ведь после каждого обновления параметров энкодера будет меняться пространство его результатов.
Но мы ведь знаем, что даже случайная сверточная модель нам может дать достаточно информации для сравнения двух состояний. Поэтому, для целей внутреннего вознаграждения мы создадим не обучаемую сверточную модель. И перед процессом обучения мы сначала создадим сжатое представление всех переходов из буфера воспроизведения опыта. А в процессе обучения мы будем лишь кодировать анализируемый переход.
Говоря о переходе, в данном случае, мы подразумеваем 2 последующих состояния окружающей среды.
//--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = 2 * (HistoryBars * BarDescr + AccountDescr); descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 512; descr.window = prev_count; descr.step = NActions; descr.optimization = ADAM; descr.activation = SIGMOID; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = 512 / 8; descr.window = 8; descr.step = 8; int prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = (prev_count * prev_wout) / 4; descr.window = 4; descr.step = 4; prev_wout = descr.window_out = 2; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; }
И далее мы переходим к Дискриминатору. Надо сказать, что в данном случае Дискриминатор будет состоять из 2 моделей. Одна модель, которой мы оставили название Дискриминатор, принимает на вход 2 последовательных состояния окружающей среды и возвращает некоторое латентное представление перехода. Обратите внимание, как и было сказано выше, модель кодирует именно переход в окружающей среде без учета используемого навыка и совершенного действия. Здесь в качестве исходных данных мы используем результаты работы энкодера для 2 последующих состояний.
На выходе модели мы используем SoftMax для нормализации полученных результатов.
//--- Descriminator descriminator.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count; descr.step = NSkills; descr.optimization = ADAM; descr.activation = SIGMOID; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = 1; descr.optimization = ADAM; if(!descriminator.Add(descr)) { delete descr; return false; }
Второй составной частью Дискриминатора выступает модель для представления латентного представления используемого навыка. Из функционала модели следует, что на вход она получает только используемый навык. А возвращает его сжатое представление в виде тензора, аналогичного латентному представлению перехода (результат модели Дискриминатора).
Результаты работы этих двух моделей и будут данными для контрастного внутреннего контроля. Соответственно, на выходе модели мы так же используем SoftMax.
//--- Skills project skill_project.Clear(); //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = SIGMOID; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = EmbeddingSize; descr.activation = LReLU; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = 1; descr.optimization = ADAM; if(!skill_project.Add(descr)) { delete descr; return false; } //--- return true; }
Хотя 2 последние модели используют различные исходные данные. Они имеют довольно схожий функционал. Поэтому мы и использовали отчасти похожие архитектурные решения для них.
Как можно заметить, мы завершили метод описания архитектурных решений используемых моделей. Но в нем нет описания архитектуры планировщика. Дело в том, что на этапе обучения навыков мы не используем планировщик. Забегая немного вперед, скажу, что на первом этапе обучения мы будем случайным образом генерировать представление навыков. Это позволит нашему Актеру лучше изучить различные политики поведения. Но мы будем использовать планировщик для обучения политики использования навыков для достижения желаемой цели. Поэтому модель планировщика вынесли в отдельный метод SchedulerDescriptions.
bool SchedulerDescriptions(CArrayObj *scheduler) { //--- Scheduller if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } scheduler.Clear(); //--- CLayerDescription *descr = NULL; //--- layer 0 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = NSkills; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.window = prev_count; descr.optimization = ADAM; descr.activation = SIGMOID; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NSkills; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NSkills; descr.step = 1; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
На этом мы завершаем работу по описанию архитектурных решений используемых моделей и переходим к выстраиванию алгоритма их работы.
2.2 Советник сбора обучающей выборки
Как и ранее, в процессе обучения модели мы будем использовать несколько программ. Первый советник "...\CIC\Research.mq5" мы будем использовать для сбора обучающей выборки. Сам процесс сбора данных не изменился. Только вот для формирования действия Актера нам необходимо последовательно использовать несколько моделей. Но вначале мы должны их создать в методе инициализации советника OnInit.
В теле данного метода мы, как обычно, инициализируем все необходимые индикаторы.
int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
А затем загрузим модели Энкодера и Актера. Если отсутствуют предварительно обученные модели, то мы сгенерируем случайные.
//--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *encoder = new CArrayObj(); CArrayObj *descr = new CArrayObj(); if(!CreateDescriptions(encoder,actor, descr,descr,descr,descr)) { delete encoder; delete actor; delete descr; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Actor.Create(actor)) { delete encoder; delete actor; delete descr; return INIT_FAILED; } delete encoder; delete actor; delete descr; //--- }
А вот с Планировщиком ситуация немного иная. Ведь нам потребуется сбор данных обучающей выборки для обоих этапов обучения. И использование модели Планировщика на первом этапе может несколько ограничить пространство действий Актера. А вот использование случайно сгенерированного тензора навыка во многом аналогично использованию Планировщика со случайными параметрами. При этом во много раз быстрее прямого прохода модели.
В то же время на втором этапе обучения наоборот желательно использовать предварительно обученный Планировщик. Ведь это позволит не только собрать данные в области действий его политики, но и оценить результаты его обучения.
Поэтому мы пытаемся загрузить модель предварительно обученного планировщика, а результат операции записываем в флаг использование случайного вектора навыков.
bRandomSkills = (!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true));
Далее мы переносим все используемые модели в единый контекст OpenCL.
COpenCLMy *opcl = Encoder.GetOpenCL();
Actor.SetOpenCL(opcl);
if(!bRandomSkills)
Scheduler.SetOpenCL(opcl);
Проверяем соответствие моделей.
Actor.getResults(ActorResult); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- vector<float> EncoderResults; Actor.GetLayerOutput(0,Result); Encoder.getResults(EncoderResults); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Actor doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } //--- if(!bRandomSkills) { Scheduler.GetLayerOutput(0,Result); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Scheduler doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } }
И инициализируем переменные.
//--- PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
Сбор данных мы осуществляем в методе OnTick. Как и ранее, все операции осуществляются только в момент открытия нового бара.
void OnTick() { //--- if(!IsNewBar()) return;
Здесь мы сначала собираем исторические данные и информацию о состоянии счета. Этот процесс без изменений перенесен из ранее рассмотренных алгоритмов и мы не будем сейчас на этом останавливаться. А сразу перейдем к организации прямого прохода моделей. И первым мы осуществляем вызов Энкодера.
//--- Encoder if(!Encoder.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
Затем мы проверяем флаг использования случайного вектора навыка. Если ранее нам удалось загрузить модель Планировщика, то осуществляем последовательный вызов Планировщика и Актера.
//--- Scheduler & Actor if(!bRandomSkills) { if(!Scheduler.feedForward((CNet *)GetPointer(Encoder),-1,NULL,-1) || !Actor.feedForward(GetPointer(Encoder),-1,GetPointer(Scheduler),-1)) return; }
В противном случае мы сначала формируем случайный тензор навыков. Не забываем нормализовать его функцией SoftMax, ведь это вектора вероятностей использования отдельных навыков. И лишь потом осуществляем вызов Актера.
else { vector<float> skills = vector<float>::Zeros(NSkills); for(int i = 0; i < NSkills; i++) skills[i] = (float)((double)MathRand() / 32767.0); skills.Activation(skills,AF_SOFTMAX); bSkills.AssignArray(skills); if(bSkills.GetIndex() >= 0 && !bSkills.BufferWrite()) return; if(!Actor.feedForward(GetPointer(Encoder),-1,(CBufferFloat *)GetPointer(bSkills))) return; }
В результате прямого прохода моделей мы получаем некий тензор действий на выходе Актера. Но здесь надо сказать, что отказ от стохастичной политики ведет к жестким ассоциациям Актера между исходными данными и выбранным действием. И для целей исследования окружающей среды мы добавим небольшой шум к полученному вектору действий.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- for(ulong i = 0; i < temp.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.1f; temp[i] += rnd; } temp.Clip(0.0f,1.0f); ActorResult = temp;
Лишь только после этих операций мы осуществляем действия Актера и сохраняем полученный результат в буфер воспроизведения опыта.
Здесь следует обратить внимание, что мы сохраняем прежний набор данных без идентификатора навыка. Ведь для целей обучения моделей от окружающей среды нам нужны переходы и вознаграждения. А различные векторы идентификации навыков мы будем генерировать в процессе обучения. Что позволит нам многократно расширить обучающую выборку без дополнительного взаимодействия с окружающей средой.
Дальнейший код метода, как и советника в целом остался без изменений и перекочевал из ранее рассмотренных аналогичных советников. И мы не будем сейчас подробного его разбирать. Вы можете самостоятельно ознакомиться с ним во вложении.
2.3 Обучение навыков
Первый этап обучения моделей — изучение навыков организован в советнике "...\CIC\Pretrain.mq5". Во многом он построен по аналогии с ранее рассмотренными советниками "Study.mq5", но с учетом специфики рассматриваемого алгоритма Contrastive Intrinsic Control.
Алгоритм метод инициализации советника OnInit ничем не отличается от одноименных методов ранее рассмотренных аналогичных советников. Остановимся лишь на списке используемых моделей. Здесь мы видим Энкодер, Актера, 2 Критика, случайный сверточный Энкодер и модели Дискриминатора. Но целевая только одна модель Энкодера.
Две модели Энкодера нам необходимы для кодирования анализируемого и последующего состояний окружающей среды, которые используются Дискриминатором.
Однако мы не используем целевые модели Актера и Критиков, так как на данном этапе мы учим Актера к совершению разделимых действий под действием того или иного навыка в конкретном состоянии окружающей среды. Мы не стремимся накопить внутреннее вознаграждение к различным навыкам. Мы максимизируем его в каждом отдельном моменте.
int OnInit() { //--- ....... ....... //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Descriminator.Load(FileName + "Des.nnw", temp, temp, temp, dtStudied, true) || !SkillProject.Load(FileName + "Skp.nnw", temp, temp, temp, dtStudied, true) || !Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true) || !TargetEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *encoder = new CArrayObj(); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *descrim = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); CArrayObj *skill_poject = new CArrayObj(); if(!CreateDescriptions(encoder,actor, critic, convolution,descrim,skill_poject)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } if(!Encoder.Create(encoder) || !Actor.Create(actor) || !Critic1.Create(critic) || !Critic2.Create(critic) || !Descriminator.Create(descrim) || !SkillProject.Create(skill_poject) || !Convolution.Create(convolution)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } if(!TargetEncoder.Create(encoder)) { delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; return INIT_FAILED; } delete encoder; delete actor; delete critic; delete descrim; delete convolution; delete skill_poject; //--- TargetEncoder.WeightsUpdate(GetPointer(Encoder), 1.0f); } //--- OpenCL = Actor.GetOpenCL(); Encoder.SetOpenCL(OpenCL); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetEncoder.SetOpenCL(OpenCL); Descriminator.SetOpenCL(OpenCL); SkillProject.SetOpenCL(OpenCL); Convolution.SetOpenCL(OpenCL); //--- ........ ........ //--- return(INIT_SUCCEEDED); }
Непосредственно процесс обучения моделей организован в методе Train.
По аналогии с предыдущей статьей, в начале метода мы кодируем все имеющиеся в буфере воспроизведения опыта переходы между состояниями. Алгоритм построения процесса идентичный. Но есть и своя специфика. Мы кодируем переходы. Поэтому на вход случайному кодировщику подаем тензор из 2 последовательных состояний без учета выполняемых действий.
И второй момент, на данном этапе мы используем лишь внутреннее вознаграждение. А значит исключаем обработку внешних вознаграждений окружающей среды.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- int total_states = Buffer[0].Total - 1; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total - 1; vector<float> temp; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total - 1; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- State.AddArray(Buffer[tr].States[st + 1].state); State.Add((Buffer[tr].States[st + 1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[1] / PrevBalance); State.Add((Buffer[tr].States[st + 1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st + 1].account[2]); State.Add(Buffer[tr].States[st + 1].account[3]); State.Add(Buffer[tr].States[st + 1].account[4] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[5] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[st + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { state_embedding.Reshape(state,state_embedding.Cols()); total_states = state; }
Далее мы объявляем локальные переменные.
vector<float> reward = vector<float>::Zeros(NRewards); vector<float> rewards1 = reward, rewards2 = reward; int bar = (HistoryBars - 1) * BarDescr;
И организовываем цикл обучения моделей. В теле цикла мы, как и ранее, случайным образом выбираем траекторию и анализируемое состояние из буфера воспроизведения опыта.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
На данных семплированного состояния мы формируем тензоры исходных данных наших моделей.
//--- State State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
Тут же мы формируем случайный тензор используемого навыка.
//--- Skills vector<float> skills = vector<float>::Zeros(NSkills); for(int sk = 0; sk < NSkills; sk++) skills[sk] = (float)((double)MathRand() / 32767.0); skills.Activation(skills,AF_SOFTMAX); Skills.AssignArray(skills); if(Skills.GetIndex() >= 0 && !Skills.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Сформированные исходные данные мы сначала подаем на вход нашего Энкодера.
//--- Encoder State if(!Encoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
А затем осуществляем прямой проход Актера.
//--- Actor if(!Actor.feedForward(GetPointer(Encoder), -1, GetPointer(Skills))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
На базе полученного тензора действий мы формируем прогнозное последующее состояние. С историческими данными ценового движения у нас нет проблем. Мы их просто берем из буфера воспроизведения опыта. А вот для расчета прогнозного состояния счета мы создадим метод ForecastAccount, с алгоритмом которого познакомимся немного позже.
//--- Next State TargetState.AssignArray(Buffer[tr].States[i + 1].state); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); Actor.getResults(Result); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,Result,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetAccount.AssignArray(forecast); if(TargetAccount.GetIndex() >= 0 && !TargetAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
И далее осуществляем прямой проход целевого Энкодера для получения латентного представления последующего состояния.
if(!TargetEncoder.feedForward(GetPointer(TargetState), 1, false, GetPointer(TargetAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
На данном этапе у нас есть латентное представление 2 последующих состояний окружающей среды и можем получить вектор представления перехода. И тут же получаем вектор представления навыка.
//--- Descriminator if(!Descriminator.feedForward(GetPointer(Encoder),-1,GetPointer(TargetEncoder),-1) || !SkillProject.feedForward(GetPointer(Skills),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Результат контрастного сравнения двух полученных векторов служит первой частью нашего внутреннего вознаграждения. Максимизация этого вознаграждения стимулирует Актера к обучения легко разделимых и предсказуемых навыков, которые легко сопоставить с отдельным переходом состояний в окружающей среде.
Descriminator.getResults(rewards1); SkillProject.getResults(rewards2); float norm1 = rewards1.Norm(VECTOR_NORM_P,2); float norm2 = rewards2.Norm(VECTOR_NORM_P,2); reward[0] = (rewards1 / norm1).Dot(rewards2 / norm2);
И сразу мы обновляем параметры моделей Дискриминатора. Без лишнего усложнения алгоритма мы просто обучаем модель Дискриминатора на приближение сжатого представления навыка. А модель проекции навыка на приближение сжатого представления перехода.
Одновременно мы обучаем Энкодер на такое представление состояния окружающей среды, которое могло бы быть идентифицировано с неким навыком. Энкодер мы обучаем на основании градиентов ошибки, полученных от Дискриминатора. Аналогично Актеру и Критику в непрерывном пространстве действий.
Result.AssignArray(rewards2); if(!Descriminator.backProp(Result,GetPointer(TargetEncoder)) || !Encoder.backPropGradient(GetPointer(Account),GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.AssignArray(rewards1); if(!SkillProject.backProp(Result,(CNet *)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Второй составляющей нашей функции внутреннего вознаграждения будет штраф за отсутствие открытых позиций в текущем моменте. Информации о наличии сделок мы берем из прогнозного состояния счета.
if(forecast[3] == 0.0f && forecast[4] == 0.f) reward[0] -= Buffer[tr].States[i + 1].state[bar + 6] / PrevBalance;
И третьей составляющей нашего внутреннего вознаграждения является энтропия перехода, что стимулирует Актера к изучению разнообразного поведения и освоению большого числа навыков. Для получения энтропии перехода мы сначала получаем сжатое представление перехода в пространстве случайного кодировщика и определяем k ближайших соседей в методе KNNReward.
State.AddArray(GetPointer(Account)); State.AddArray(GetPointer(TargetState)); State.AddArray(GetPointer(TargetAccount)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(rewards1); reward[0] += KNNReward(7,rewards1,state_embedding);
Полученный результат энтропии перехода добавляем к нашему внутреннему вознаграждению.
Теперь, когда мы сформировали полное значение нашего комплексного внутреннего вознаграждения мы можем перейти к обучению Критиков и Актера. Прямой проход Актера мы уже осуществили ранее. Теперь мы вызываем прямой проход обоих критиков.
Result.AssignArray(reward); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Актера мы будем обучать с использование критика с минимальной ошибкой. Проверяем среднюю скользящую ошибку Критиков. И сначала осуществляем обратный проход Критика с минимальной ошибкой. За ним следует обратный проход Актера. И завершает обратный проход Критика с наибольшей средней ошибкой прогнозирования стоимости действий Актера..
if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) { if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Skills), GetPointer(Gradient), -1) || !Critic2.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } else { if(!Critic2.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Skills), GetPointer(Gradient), -1) || !Critic1.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Далее мы осуществляем обновление параметров целевого Энкодера и информируем пользователя о состоянии процесса обучения моделей.
//--- Update Target Nets TargetEncoder.WeightsUpdate(GetPointer(Encoder), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
После завершения всех итераций цикла обучения мы очищаем поле комментариев графика и инициализируем процесс закрытия программы.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Для составления общей картины процесса обучения рассмотрим еще метод формирования прогнозного состояния счета ForecastAccount. В параметрах метод получает указатель на предыдущее состояния счета, тензор действий, значение профита в 1 лот длинной позиции за последующий бар и временную метку следующего бара. Размер профита на 1 лот определяется перед вызовом метода на основании информации и последующей свече. Такая операция возможна только при офлайн обучении на основании исторических данных о движении цены.
В теле метода мы сначала проведем небольшую подготовительную работу. Здесь мы объявляем локальные переменные и загрузим некоторую информацию об инструменте. Следует обратить внимание, что так как мы нигде в обучающих данных не указывали инструмент, то воспользуемся данными об инструменте графика. Следовательно, для корректного процесса обучения необходимо запускать советник обучения на графике интересующего инструмента.
vector<float> ForecastAccount(float &prev_account[], CBufferFloat *actions,double prof_1l,float time_label) { vector<float> account; vector<float> act; double min_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_MIN); double step_lot = SymbolInfoDouble(_Symbol,SYMBOL_VOLUME_STEP); double stops = MathMax(SymbolInfoInteger(_Symbol,SYMBOL_TRADE_STOPS_LEVEL), 1) * Point(); double margin_buy,margin_sell; if(!OrderCalcMargin(ORDER_TYPE_BUY,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_ASK),margin_buy) || !OrderCalcMargin(ORDER_TYPE_SELL,_Symbol,1.0,SymbolInfoDouble(_Symbol,SYMBOL_BID),margin_sell)) return vector<float>::Zeros(prev_account.Size());
Для удобства работы перенесем полученные в параметрах данные в вектора.
actions.GetData(act); account.Assign(prev_account);
После этого скорректируем действия агента на открытие позиции только в одном направлении на разницу заявленных объемов. И тут же мы проверяем достаточность средтсв на проведение операций. При недостатке ресурсов на счете мы обнуляем объем сделки.
if(act[0] >= act[3]) { act[0] -= act[3]; act[3] = 0; if(act[0]*margin_buy >= MathMin(account[0],account[1])) act[0] = 0; } else { act[3] -= act[0]; act[0] = 0; if(act[3]*margin_sell >= MathMin(account[0],account[1])) act[3] = 0; }
Далее идут операции расшифровки полученных действий. Процесс построен по аналогии с алгоритмом совершения действий в советнике сбора обучающих данных. Только вместо совершения действий мы изменяем соответствующие элементы описания состояния счета. Первыми мы рассматриваем элементы длинной позиции. Если объем к сделке равен "0" или уровни стопов меньше минимального отступа по инструменту, то такой набор параметров свидетельствует закрытию сделки. Конечно если таковая была открыта. Мы обнуляем размер текущей позиции в данном направлении. А накопленную прибыль / убыток прибавляем к текущему балансу.
//--- buy control if(act[0] < min_lot || (act[1] * MaxTP * Point()) <= stops || (act[2] * MaxSL * Point()) <= stops) { account[0] += account[4]; account[2] = 0; account[4] = 0; }
В случае открытия или удержания позиции мы нормализуем объем сделки. И проверяем полученный объем с открытым ранее. Если позиция была больше предложенной Актером, то накопленную прибыль / убыток делим пропорционально предложенному и закрываемому объемам. Прибыль . убыток закрываемого объема прибавляем к балансу. Разницу оставляем в поле накопленной прибыли. А объем позиции изменяем на предложенный Актером. Дополнительно, к накопленному объему прибавляем прибыль / убыток от перехода в следующее состояние окружающей среды.
else { double buy_lot = min_lot + MathRound((double)(act[0] - min_lot) / step_lot) * step_lot; if(account[2] > buy_lot) { float koef = (float)buy_lot / account[2]; account[0] += account[4] * (1 - koef); account[4] *= koef; } account[2] = (float)buy_lot; account[4] += float(buy_lot * prof_1l); }
Операции повторяются для коротких позиций.
//--- sell control if(act[3] < min_lot || (act[4] * MaxTP * Point()) <= stops || (act[5] * MaxSL * Point()) <= stops) { account[0] += account[5]; account[3] = 0; account[5] = 0; } else { double sell_lot = min_lot + MathRound((double)(act[3] - min_lot) / step_lot) * step_lot; if(account[3] > sell_lot) { float koef = float(sell_lot / account[3]); account[0] += account[5] * (1 - koef); account[5] *= koef; } account[3] = float(sell_lot); account[5] -= float(sell_lot * prof_1l); }
Накопленная прибыль от длинных и коротких позиций составляют накопленную прибыль по счету. А сумма накопленной прибыли и баланса дают показатель Эквити.
account[6] = account[4] + account[5]; account[1] = account[0] + account[6];
Из полученных значений формируем вектор описания состояния счета и возвращаем его, вызывающей программе.
vector<float> result = vector<float>::Zeros(AccountDescr); result[0] = (account[0] - prev_account[0]) / prev_account[0]; result[1] = account[1] / prev_account[0]; result[2] = (account[1] - prev_account[1]) / prev_account[1]; result[3] = account[2]; result[4] = account[3]; result[5] = account[4] / prev_account[0]; result[6] = account[5] / prev_account[0]; result[7] = account[6] / prev_account[0]; double x = (double)time_label / (double)(D'2024.01.01' - D'2023.01.01'); result[8] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_MN1); result[9] = (float)MathCos(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_W1); result[10] = (float)MathSin(2.0 * M_PI * x); x = (double)time_label / (double)PeriodSeconds(PERIOD_D1); result[11] = (float)MathSin(2.0 * M_PI * x); //--- return result return result; }
После завершения процесса обучения все модели сохраняются в методе деинициализации советника OnDeinit.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- TargetEncoder.WeightsUpdate(GetPointer(Encoder), Tau); Actor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetEncoder.Save(FileName + "Enc.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); Critic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Convolution.Save(FileName + "CNN.nnw", 0, 0, 0, TimeCurrent(), true); Descriminator.Save(FileName + "Des.nnw", 0, 0, 0, TimeCurrent(), true); SkillProject.Save(FileName + "Skp.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
На этом мы заканчиваем работу над советником предварительного обучения навыков Актера без внешнего вознаграждения. А с полным кодом данного советника можно ознакомиться во вложении. Там же вы найдете полный код всех программ, используемых в статье.
2.4 Советник тонкой настройки
Завершается процесс обучения моделей обучением Планировщика, который генерирует вектор используемых навыков и тем самым управляет действиями Актера.
Политика Планировщика обучается на максимизацию внешнего вознаграждения. И процесс его обучения мы организуем в советнике "...\CIC\Finetune.mq5". Советник построен аналогично предыдущему, но есть нюансы. Для работы советника необходимы предварительно обученные модели Энкодера, Актера и Критиков. Мы так же будем использовать целевые копии указанных моделей.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Encoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !Actor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !Critic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !Critic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true) || !Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true) || !TargetEncoder.Load(FileName + "Enc.nnw", temp, temp, temp, dtStudied, true) || !TargetActor.Load(FileName + "Act.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic1.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true) || !TargetCritic2.Load(FileName + "Crt2.nnw", temp, temp, temp, dtStudied, true)) { Print("No pretrained models found"); return INIT_FAILED; }
Кроме того, мы загружаем модель случайного сверточного энкодера. Но не загружаем модели Дискриминатора. На данном этапе мы используем только внешнее вознаграждение. Поведенческие политики Актера были изучены на предыдущем этапе. Сейчас нам предстоит выучить верхнеуровневую политику Планировщика.
Поэтому, после загрузки предварительно обученных моделей и пробуем загрузить модель Планировщика. И если таковая не найдена, то на этот раз мы создаем новую модель инициализируем случайными параметрами.
if(!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true)) { CArrayObj *descr = new CArrayObj(); if(!SchedulerDescriptions(descr) || !Scheduler.Create(descr)) { delete descr; return INIT_FAILED; } delete descr; }
Далее мы переводим все модели в единый контекст OpenCL и отключаем режим обучения Актера и Энкодера.
OpenCL = Actor.GetOpenCL(); Encoder.SetOpenCL(OpenCL); Critic1.SetOpenCL(OpenCL); Critic2.SetOpenCL(OpenCL); TargetEncoder.SetOpenCL(OpenCL); TargetActor.SetOpenCL(OpenCL); TargetCritic1.SetOpenCL(OpenCL); TargetCritic2.SetOpenCL(OpenCL); Scheduler.SetOpenCL(OpenCL); Convolution.SetOpenCL(OpenCL); //--- Actor.TrainMode(false); Encoder.TrainMode(false);
В завершении метода инициализации мы проверяем соответствие архитектуры моделей и генерируем событие начала процесса обучения.
vector<float> ActorResult; Actor.getResults(ActorResult); if(ActorResult.Size() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Encoder.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of State Encoder doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; } //--- vector<float> EncoderResults; Actor.GetLayerOutput(0,Result); Encoder.getResults(EncoderResults); if(Result.Total() != int(EncoderResults.Size())) { PrintFormat("Input size of Actor doesn't match Encoder outputs (%d <> %d)", Result.Total(), EncoderResults.Size()); return INIT_FAILED; } //--- Actor.GetLayerOutput(LatentLayer, Result); int latent_state = Result.Total(); Critic1.GetLayerOutput(0, Result); if(Result.Total() != latent_state) { PrintFormat("Input size of Critic doesn't match latent state Actor (%d <> %d)", Result.Total(), latent_state); return INIT_FAILED; } //--- Gradient.BufferInit(AccountDescr, 0); //--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
В методе деинициализации советника мы сохраняем только модели Критиков и Планировщика.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); TargetCritic1.Save(FileName + "Crt1.nnw", Critic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic2.Save(FileName + "Crt2.nnw", Critic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); Scheduler.Save(FileName + "Sch.nnw", 0, 0, 0, TimeCurrent(), true); delete Result; }
Думаю ни у кого не вызывает вопрос необходимость обучения Планировщика. Но вот вопрос обновления параметров Критиков и фиксация параметров Актера наверное стоит пояснить. На предыдущем этапе мы обучили политики Актера в зависимости от используемого навыка. И на данном этапе мы учимся управлять навыками. Поэтому мы фиксируем параметры Актера и обучаем Планировщика управлять им.
Другой вопрос по поводу Критиков. Дело в том, что на стадии обучения навыков мы использовали только внутреннее вознаграждение, которое было направлено на изучение различных навыков Актера. И, конечно, Критики выстроили зависимости между действиями Актера и их влияние на внутреннее вознаграждение. Но на данном этапе мы используем внешнее вознаграждение. И на него, скорее всего, действия Актера оказывают совершенно другое влияние. Поэтому нам предстоит переобучить Критиков под новые обстоятельства.
Здесь также следует сказать, что если раньше мы использовали наши допущения о влиянии выбранного навыка на результат, то сейчас мы будем пропускать градиент ошибки вознаграждения от Критика сквозь Актера до Планировщика. Но давайте вернемся к нашему советнику и посмотрим на алгоритм организации процесса.
Процесс обучения моделей по-прежнему организован в методе Train. Как и в выше рассмотренном советнике обучения навыков, в начале метода мы осуществляем кодирование переходов. Только на этот раз мы добавляем загрузку внешних вознаграждений от окружающей среды. И обратите внимание, что мы берем только вознаграждение за отдельно взятый переход. Накопительное вознаграждением мы будем прогнозировать с использованием целевых моделей.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); float loss = 0; //--- int total_states = Buffer[0].Total - 1; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total - 1; vector<float> temp; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states,temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states,NRewards); int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total - 1; st++) { State.AssignArray(Buffer[tr].States[st].state); float PrevBalance = Buffer[tr].States[MathMax(st,0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st,0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance); double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); //--- State.AddArray(Buffer[tr].States[st + 1].state); State.Add((Buffer[tr].States[st + 1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[1] / PrevBalance); State.Add((Buffer[tr].States[st + 1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st + 1].account[2]); State.Add(Buffer[tr].States[st + 1].account[3]); State.Add(Buffer[tr].States[st + 1].account[4] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[5] / PrevBalance); State.Add(Buffer[tr].States[st + 1].account[6] / PrevBalance); x = (double)Buffer[tr].States[st + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); state_embedding.Row(temp,state); temp.Assign(Buffer[tr].States[st].rewards); for(ulong r = 0; r < temp.Size(); r++) temp[r] -= Buffer[tr].States[st + 1].rewards[r] * DiscFactor; rewards.Row(temp,state); state++; if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } } if(state != total_states) { state_embedding.Reshape(state,state_embedding.Cols()); rewards.Reshape(state,NRewards); total_states = state; }
Далее мы организовываем цикл обучения моделей. В теле цикла мы семплируем состояние из буфера воспроизведения опыта.
vector<float> reward, rewards1, rewards2, target_reward; int bar = (HistoryBars - 1) * BarDescr; for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; } reward = vector<float>::Zeros(NRewards); rewards1 = reward; rewards2 = reward; target_reward = reward;
И подготавливаем буферы исходных данных.
//--- State State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; if(PrevBalance == 0.0f || PrevEquity == 0.0f) continue; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(Account.GetIndex() >= 0) Account.BufferWrite();
После формирования полного набора исходных данных выбранного состояния мы осуществляем прямой проход Энкодера.
//--- Encoder State if(!Encoder.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
За Энкодером идет прямой проход Планировщика, который оценивает латентное представление состояния окружающей среды и генерирует вектор навыков для Актера.
//--- Skills if(!Scheduler.feedForward(GetPointer(Encoder), -1, NULL,-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Актер в свою очередь использует навык, указанный Планировщиком, и анализирует латентное представление состояния окружающей среды от Энкодера. По совокупности исходных данных Актер генерирует вектор действий.
//--- Actor if(!Actor.feedForward(GetPointer(Encoder), -1, GetPointer(Scheduler),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Мы же используем полученный вектор действий для прогноза следующего состояния окружающей среды.
//--- Next State TargetState.AssignArray(Buffer[tr].States[i + 1].state); double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); Actor.getResults(Result); vector<float> forecast = ForecastAccount(Buffer[tr].States[i].account,Result,prof_1l, Buffer[tr].States[i + 1].account[7]); TargetAccount.AssignArray(forecast); if(TargetAccount.GetIndex() >= 0 && !TargetAccount.BufferWrite()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
И мы повторяем действия, но уже для последующего состояния целевыми моделями. Из данной цепочки исключается Планировщик, так как мы предполагаем использование того же навыка.
if(!TargetEncoder.feedForward(GetPointer(TargetState), 1, false, GetPointer(TargetAccount))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Target if(!TargetActor.feedForward(GetPointer(TargetEncoder), -1, GetPointer(Scheduler),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Однако, для оценки политики Актера нам необходима оценка его действий Критиком. И здесь мы будем использовать меньшую оценку для в качестве прогноза будущего вознаграждения.
//--- if(!TargetCritic1.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor)) || !TargetCritic2.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1; else target_reward = rewards2; target_reward *= DiscFactor;
Оценку текущего действия мы будем осуществлять на основании k ближайших соседей прогнозного перехода. Для этого мы воспользуемся случайным Энкодером.
State.AddArray(GetPointer(TargetState)); State.AddArray(GetPointer(TargetAccount)); if(!Convolution.feedForward(GetPointer(State),1,false,NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(rewards1); reward[0] += KNNReward(7,rewards1,state_embedding,rewards); reward += target_reward; Result.AssignArray(reward);
Объединяем текущее и прогнозное вознаграждение. Теперь у нас есть целевое значение для обучения моделей. Остается выбрать модель Критика для обновления параметров Планировщика. Мы осуществляем прямой проход обоих Критиков и выбираем минимальную оценку выбранного Актером действия.
if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor),-1)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic1.getResults(rewards1); Critic2.getResults(rewards2);
Как и в предыдущем советнике, мы осуществляем обратный проход выбранного Критика, Актера, Планировщика. И в последним осуществляем обратный проход Критика с максимальной оценкой действий Актера.
if(rewards1.Sum() <= rewards2.Sum()) { loss = (loss * MathMin(iter,999) + (reward - rewards1).Sum()) / MathMin(iter + 1,1000); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Scheduler),-1,-1) || !Scheduler.backPropGradient() || !Critic2.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } } else { loss = (loss * MathMin(iter,999) + (reward - rewards2).Sum()) / MathMin(iter + 1,1000); if(!Critic2.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Scheduler),-1,-1) || !Scheduler.backPropGradient() || !Critic1.backProp(Result, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
В завершение итераций цикла обучения нам остается обновить целевые модели Критиков и проинформировать пользователя о ходе выполнения процесса обучения моделей.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-20s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), loss); Comment(str); ticks = GetTickCount(); } }
После завершения всех итераций цикла обучения моделей мы очищаем поле комментариев графика и инициализируем процесс завершения работы советника.
Comment(""); //--- PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-20s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", loss); ExpertRemove(); //--- }
На этом мы завершаем рассмотрение программ реализации представленного алгоритма. Мы еще не посмотрели на советник тестирования обученных моделей. В него были внесены коррективы аналогичные советнику сбора обучающей выборки. Только мы не стали в нем добавлять случайный шум в вектор действий, чтобы оценить реальное качество работы обученных моделей. С полным кодом всех программ, используемых в статье вы можете самостоятельно познакомиться во вложении.
3. Тестирование
Обучение и тестирование моделей мы осуществляли на исторических данных за первые 5 месяцев 2023 года. Инcтрумент EURUSD, тайм-фрейм H1. Как всегда, параметры всех индикаторов использовались по умолчанию. Сразу надо сказать, что процесс обучения моделей довольно длительный. Авторы метода предлагают первый этап изучения навыков осуществлять порядка 2 млн. итераций. Конечно, количество итераций может быть увеличено для более сложных сред. В процессе обучения своей модели я проделал данный путь за несколько подходов с дополнительным сбором обучающих данных.
После изучения навыков идет этап тонкой настройки и обучения Планировщика. Данный этап также насчитывает не менее 100 тыс. итераций. Этот этап я также предлагаю осуществлять в несколько подходов. Сначала мы инициализируем случайную модель Планировщика и обучаем на широком наборе данных. После первого прохода обучения Планировщика мы собираем дополнительные обучающие наборы. которые будут включать примеры взаимодействия политики Планировщика с окружающей средой. Это позволит скорректировать его политику в лучшую сторону.
В процессе обучения мне удалось обучить модель, способную генерировать прибыль. На представленном графике результатов тестирования мы видим четкую тенденцию к росту линии баланса. В то же время меня смущают некоторые зоны просадок по Эквити, что может говорить о необходимости дополнительного обучения модели. Мы знаем, что финансовые рынки довольно стохастичные и сложные среды. И вполне ожидаемо, что для получения желаемых результатов необходимы более длительные периоды обучения.


Заключение
В данной статье мы познакомились с перспективным метод в области иерархического обучения с подкреплением — "Контрастный внутренний контроль" (CIC). Этот метод относится к семейству алгоритмов, основанных на самоконтролируемых внутренних вознаграждениях. Основанный на принципах алгоритма DIAYN, он стремится к улучшению извлечения иерархических навыков Агента путем внедрения контрастного обучения.
Одной из ключевых особенностей CIC является его способность изучать разнообразные навыки в сложных средах, где количество потенциальных вариантов поведения может быть довольно большим. Это свойство особенно полезно в области решения задач с непрерывным пространством действий. Использование контрастного обучения позволяет направлять Агента таким образом, чтобы он мог не только эффективно обучаться в разнообразных сценариях, но и извлекать ценные знания из этих сценариев.
В практической части нашей статьи мы реализовали алгоритм средствами MQL5. Провели обучение и тестирование модели на реальных исторических данных. Полученные результаты позволяют говорить о потенциальной эффективности метода. Но изучении большого количества навыков требует и соизмеримых затрат на обучение Агента.
Ссылки
- CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery
- Representation Learning with Contrastive Predictive Coding
- Нейросети — это просто (Часть 43): Освоение навыков без функции вознаграждения
- Нейросети — это просто (Часть 44): Изучение навыков с учетом динамики
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | Pretrain.mq5 | Советник | Советник обучения навыков Актера |
| 3 | Finetune.mq5 | Советник | Советник тонкой настройки и обучения Планировщика |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
На скриншоте в статье только короткие позиции (sell).
А как заставить его работать в обе стороны? Советник перестал обучаться. Pretrain и Finetune после Embedding слетают с графика. К сожалению. Начать все сначала?
Советник перестал обучаться. Pretrain и Finetune после Embedding слетают с графика.
Какие сообщения в журнале?
Какие сообщения в журнале?
Ожил курилка. Заметил такую странность - после прохождения Research в тестере компьютер на некоторое время подвисает. Возможно, потому они и слетали. Продолжаем учиться.
Ожил курилка. Заметил такую странность - после прохождения Research в тестере компьютер на некоторое время подвисает. Возможно, потому они и слетали. Продолжаем учиться.
После прохождения Research происходит сохранение базы примеров. И если она достаточно большая, то возможно ощущение подтормаживания компьютера на время обработки базы и записи её на диск. Естественно, если есть ошибки при сохранении базы, то Pretrain и Finetune не смогут её считать и будут слетать.