
Нейросети — это просто (Часть 36): Реляционные модели обучения с подкреплением (Relational Reinforcement Learning)

Введение
Мы продолжаем изучение методов обучения с подкреплением. В предыдущих статьях было рассмотрено несколько алгоритмов. Но всегда мы использовали сверточные модели. И это неудивительно. При проектировании и тестировании всех рассмотренных ранее алгоритмов использовались различные компьютерные игры. И на вход моделей в основном подавалось изображение уровней различных компьютерных игр. Задачи распознавания изображений и детекции на них различных объектов с легкостью решаются сверточными моделями.
Изображение сцены компьютерных игр лишено шумов и искажений объектов. И это упрощает задачу их распознавания. В реальной же ситуации мы лишены столь "стерильных" условий. Наши данные переполнены различных шумов. И очень часто изучаемые образы далеки от идеальных ожиданий. Они могут быть перемещены по сцене (с этим легко справляются сверточные сети). А могут быть подвержены различным искажениям. Растянуты или сжаты, представлены под другим углом. С такой задачей обычной сверточной модели сложнее справиться.
Возможны ситуации, когда для успешного решения задачи важно не только наличие двух и более объектов, но и их взаимное расположении. И такие задачи уже сложно решать c использованием только сверточных моделей. Но они хорошо решаются реляционными моделями.
1. Реляционное обучение с подкреплением
Основное преимущество реляционных моделей является способность выстраивания зависимостей между объектами, что позволяет структурировать исходные данные. Наиболее наглядно реляционную модель можно представить в виде графов. Объекты и события представлены в виде узлов. А связи демонстрируют зависимости между соответствующими объектами и событиями.

Использование графов позволяет нам наглядно выстроить структуру зависимостей между объектами. К примеру, если мы захотим описать паттерн пробития канала мы составим граф, в вершине которого будет формирование канала. Описание формирования канала также может быть представлено в виде графа. Далее мы создадим 2 узла пробития канала (верхней и нижней границы). Оба узла будут иметь одинаковые связи с предшествующим узлом формирования канала, но не связаны между собой. Для исключения входа в позицию при ложном пробое мы можем дождаться отката к границе канала. Это будут ещё 2 узла отката к верхней и нижней границе канала, которые будут иметь связи с узлами пробития соответствующей границы канала. Но они опять не будут иметь связей между собой.
Описанная структура хорошо ложится в граф и даёт четкое структурирование данных и последовательности событий. Нечто подобное мы рассматривали при построении ассоциативных правил. Но это сложно увязывается с используемыми нами ранее сверточными сетями.
Казалось бы, сверточные сети используются для идентификации объектов в данных. Мы можем обучить модель выделять какие-то точки разворота движения или небольшие тенденции. Но на практике процесс формирования канала может быть растянут во времени с различной интенсивностью тенденций внутри канала. А сверточные модели не всегда хорошо справляются с подобными искажениями. К тому же, ни сверточные, ни полносвязные нейронные слои не могут разделить 2 различных паттерна, которые состоят из одних и тех же объектов с различной последовательностью.
Также следует отметить, что сверточные нейронные сети способны только выявлять объекты. Но не способны выстраивать зависимости между ними. А значит нам нужно найти некий иной алгоритм, который бы мог обучаться подобным зависимостям. И здесь мы должны вспомнить о моделях внимания. Именно модели внимания позволяют акцентировать внимание на отдельных объектах, выделяя их из общего массива данных.
Впервые "обобщенный механизм внимания" был предложен в сентябре 2014 года для повышения эффективности моделей машинного перевода с использованием рекуррентных моделей. Было предложено создание дополнительного слоя внимания, который собирал скрытые состояния энкодера при обработке исходной последовательности. Это позволило решить проблему долгосрочной памяти. А анализ зависимостей между элементами последовательности помог повысить качество машинного перевода.
Алгоритм работы такого механизма включал следующие итерации:
1. Создание скрытых состояний Encoder и аккумулирование их в блоке внимания.
2. Оценка парных зависимостей между скрытыми состояниями каждого элемента Encoder и последнего срытого состояния Decoder.
3. Полученные оценки объединяются в единый вектор и нормализуются путем использования функции Softmax.
4. Вычисления вектора контекста, путем умножения всех скрытых состояний Encoder на соответствующее им оценки выравнивания.
5. Декодирование вектора контекста и объединение полученного значения с предыдущим состоянием Decoder.
Все итерации повторяются до получения сигнала конца предложения.
На рисунке ниже представлена визуализация предложенного решения.

Однако, обучение рекуррентных моделей является довольно трудоёмким процессом и в июне 2017 года в статье "Attention Is All You Need" была предложена новая архитектура нейронной сети Трансформер, в которой отказались от использования рекуррентных блоков и предложили новый алгоритм внимания — Self-Attention. В отличии от описанного выше алгоритм Self-Attention анализирует парные зависимости внутри одной последовательности. В предыдущих статьях мы уже создали 3 типа нейронных слоёв с использованием алгоритма Self-Attention. И в рамках этой статьи мы воспользуемся одним из них. Но прежде, чем приступать к реализации советника, давайте рассмотрим, каким образом алгоритм Self-Attention может выучить структуру графа.

На входе алгоритма Self-Attention мы ожидаем тензор исходных данных. В котором каждый элемент последовательности описывается неким количеством признаков. Количество таких признаков определено заранее и фиксировано для всех элементов последовательности. Таким образом, тензор исходных данных представляется нам таблицей. Каждая строка данной таблицы является описанием одного элемента последовательности. И каждый столбец будет соответствовать отдельно взятому признаку.
Используемые признаки могут абсолютно различные распределения. Характеристики распределения одного признака могут сильно отличаться от аналогичных характеристик другого признака. А также влияние на конечный результат абсолютных значений признаков и их изменений могут быть абсолютно противоположны. Для приведения данных в сопоставимый вид, по аналогии со скрытым состоянием рекуррентного слоя мы используем матрицу весов. Умножение каждой строки тензора исходных данных на матрицу весов переводит описание элемента последовательности в некое d-мерное пространство внутреннего эмбединга. А подбор параметров указанной матрицы в процессе обучения позволяет подобрать такие их значения, при которых элементы последовательности будут максимально разделимы между собой и сгруппированы по сходству. Надо сказать, что алгоритмом Self-Attention предусматривается создание и обучение трех таких матриц. Которые позволяют формировать три различных эмбединга исходных данных: Query, Key и Value. Размерность вектора Query и Key задаются при создании модели. А размерность вектора Value соответствует количеству признаков в исходных данных (размеру вектора описания одного элемента последовательности).
Каждый из генерируемых эмбедингов имеет своё функциональное назначение. Query и Key используются для определения взаимозависимостей между элементами последовательности. А Value определяет какую информацию от каждого элемента последовательности необходимо передать дальше.
Для определения коэффициентов зависимости между элементами последовательности нам необходимо попарно умножить эмбединг каждого элемента последовательности из тензора Query на эмбединги всех элементов из тензора Key (включая эмбединг соответствующего элемента). При использовании матричных операций нам достаточно умножить матрицу Query на транспонированную матрицу Key.
![]()
Полученные значения мы разделим на квадратный корень из размерности эмбединга Key. И нормализуем функцией Softmax в разрезе элементов последовательности эмбедингов Query. В результате данной операции мы получим квадратную матрицу зависимостей между элементами последовательности исходных данных.
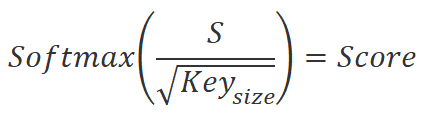
Здесь надо обратить внимание на 2 момента:
- Благодаря функции Softmax мы получили нормализованные коэффициенты зависимости в диапазоне от 0 до 1. При этом построчная сумма коэффициентов равна 1.
- Для создания эмбедингов Query и Key мы использовали различные матрицы. А значит получили различные эмбединги для одного и того же элемента последовательности исходных данных. Такой подход позволяет нам в конечном итоге получить недиагональную матрицу коэффициентов зависимостей. В которой коэффициент зависимости элемента A от элемента B и коэффициент обратной зависимости элемента B от элемента А будут отличаться.
В этом месте стоит вспомнить о целях данного действия. Как было сказано выше, мы бы хотели получить модель, способную выстраивать графы зависимостей между различными объектами и событиями. Каждый объект или событие мы описываем с помощью векторов признаков в тензоре исходных данных. А полученная нами матрица коэффициентов зависимости и является табличным представлением искомого графа. В которой нулевые значения коэффициентов говорят об отсутствии связей между соответствующими узлами исходных данных. А ненулевые значения определяют взвешенное влияние одного узла на значение другого.
Но вернемся к алгоритму Self-Attention, полученные коэффициенты зависимости мы умножаем на соответствующие эмбединги в тензоре Value. Полученные значения "взвешенных" эмбедингов мы суммируем и полученный вектор является выходом блока Self-Attention для анализируемого элемента последовательности. При использовании матричных операций нам достаточно воспользоваться функцией умножения матриц. Умножение квадратной матрицы коэффициентов зависимости на тензор Value даст нам искомый тензор результатов блока Self-Attention.
![]()
Выше описан алгоритм Self-Attention в простом случае одной головы внимания. На практике же в основном используется вариант многоголового внимания. В такой реализации добавляется ещё одна матрица понижения размерности, которая понижает размерность конкатенированный тензор со всех голов внимания до размерности исходных данных.
В завершении алгоритма Self-Attention предусмотрено сложение тензора исходных данных с результатом блока внимания и последующая нормализация полученных значений.
Как можно заметить, на входе и выходе блока Self-Attention мы имеем тензоры одинакового размера. Только на выходе мы получаем тензор нормализованных значений. В котором признаки, оказывающие существенное влияние на результат максимизированы. А значение признаков, не оказывающих влияния на результат и шумовых явлений будут минимизированы. Как правило, для усиления данного эффекта в моделях используют несколько последующих блоков внимания.
Однако, блок внимания способен лишь помочь нам выделить существенные признаки. Он не даёт нам решения поставленной задачи. Поэтому за блоком внимания организовывается блок принятия решения. В качестве которого можно использовать полносвязный перцептрон или любое изученное ранее архитектурное решение.
2. Реализация средствами MQL5
Приступая к реализации, надо сказать, что мы не будем повторять модель из оригинальной статьи "Deep reinforcement learning with relational inductive biases". Мы лишь воспользуемся предложенными наработками и добавим реляционный модуль в нашу модель с использованием модуля внутреннего любопытства. Которую мы создали в предыдущей статье. Мы создадим копию советника из предыдущей статьи и назовем файл "RLL-Learning.mq5".
Так как изменение внутренней архитектуры обучаемой модели без изменения слоя исходных данных и слоя результатов не требует изменения алгоритма работы советника, то мы могли бы просто создать новые файлы моделей и не вносить изменения непосредственно в код советника. Но в последнее время в комментариях к ранее созданным статьям я часто встречаю вопросы с ошибками загрузки моделей, созданных с применением инструмента NetCreator. Поэтому в данной статье я решил вернуться к составлению описания архитектуры модели в коде советника.
Конечно, Вы по-прежнему можете воспользоваться инструментом NetCreator для создания необходимых моделей. Но тогда прошу Вас обращать внимание на ниже следующие аспекты.
В коде советника имя файла модели задаётся макроподстановкой. Следовательно, создаваемая Вами модель должна иметь соответствовать заданному формату.
#define FileName Symb.Name()+"_"+EnumToString(TimeFrame)+"_"+StringSubstr(__FILE__,0,StringFind(__FILE__,".",0))
Имя файла составляется из:
- Названия инструмента, на графике которого запущен советник. Указывается полное имя инструмента в Вашем терминале с учетом префиксов и суффиксов.
- Таймфрейм, указанные в параметрах советника.
- Имя файла советника без расширения.
Все выше указанные составляющие разделяются знаком подчеркивания.
К имени файла добавляется расширение:
- "nnw" - для обучаемой модели,
- "fwd" - для Forward Model,
- "inv" - для Inverse Model.
Файлы всех созданных моделей должны быть помещены в каталог "Files" Вашего терминала или "Common/Files". При этом каталог с файлами должен соответствовать флагу common, который вы указали в коде программы. Значение true флага common соответствует каталогу "Common/Files".
bool CNet::Load(string file_name, float &error, float &undefine, float &forecast, datetime &time, bool common = true)
Но вернемся к коду нашего советника. В функции OnInit мы сначала инициализируем классы для работы с индикаторами.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED;
Затем мы пытаемся загрузить ранее подготовленные модели. Обратите внимание, что загружать модели я пытаюсь из каталога "Common/Files". Такой подход мне позволяет использовать советник без изменений как в тестере стратегий, так и при работе в реальном времени. Дело в том, что при запуске советника в тестере стратегий он не обращается к каталогу "Files" терминала. Так как из соображений безопасности тестер стратегий создаёт "свою песочницу" для каждого агента тестирования. В то же время, у каждого агента есть доступ к общему файловому ресурсу — каталогу "Common/Files".
//--- if(!StudyNet.Load(FileName + ".icm", true)) if(!StudyNet.Load(FileName + ".nnw", FileName + ".fwd", FileName + ".inv", 6, true)) {
В случае неудачной загрузки предварительно подготовленных моделей мы создаем описание архитектуры используемых моделей. Данный подпроцесс я вынес в отдельный метод CreateDescriptions. Здесь мы лишь вызываем его и проверяем результат выполнения операций. В случае неудачи мы удаляем лишние объекты и выходим из функции инициализации советника с результатом INIT_FAILED.
CArrayObj *model = new CArrayObj(); CArrayObj *forward = new CArrayObj(); CArrayObj *inverse = new CArrayObj(); if(!CreateDescriptions(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; }
После удачного создания описания всех трех необходимых моделей и вызываем метод создания модели. И обязательно проверяем результат выполнения операций метода.
if(!StudyNet.Create(model, forward, inverse)) { delete model; delete forward; delete inverse; return INIT_FAILED; } StudyNet.SetStateEmbedingLayer(6); delete model; delete forward; delete inverse; }
Далее мы указываем нейронный слой обучаемой модели с результатами энкодера и удаляем уже не нужны объекты описания архитектуры созданных моделей.
На следующем этапе мы переведем модель в режим обучения и укажем размер буфера воспроизведения опыта.
if(!StudyNet.TrainMode(true)) return INIT_FAILED; StudyNet.SetBufferSize(Batch, 10 * Batch);
Зададим размеры индикаторных буферов.
//--- CBufferFloat* temp; if(!StudyNet.GetLayerOutput(0, temp)) return INIT_FAILED; HistoryBars = (temp.Total() - 9) / 12; delete temp; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
И укажем тип исполнения торговых операций.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- return(INIT_SUCCEEDED); }
На этом мы завершаем работу с методом инициализации советника. И перейдем к работе над методом создания описания архитектуры моделей CreateDescriptions.
bool CreateDescriptions(CArrayObj *Description, CArrayObj *Forward, CArrayObj *Inverse)
{
В параметрах данный метод получает указатели на три динамических массива для записи архитектур трех создаваемых моделей:
- Description — обучаемая модель,
- Forward модель,
- Inverse модель.
В теле метода мы сразу проверяем полученные указатели. И при необходимости создаем новые экземпляры объектов.
//--- if(!Description) { Description = new CArrayObj(); if(!Description) return false; } //--- if(!Forward) { Forward = new CArrayObj(); if(!Forward) return false; } //--- if(!Inverse) { Inverse = new CArrayObj(); if(!Inverse) return false; }
При этом мы контролируем процесс выполнения операций. И в случае неудачи завершаем работу метода с результатом False.
После успешного создания необходимых объектов мы переходим к подпроцессу непосредственного описания архитектуры создаваемых моделей. И первой мы опишем архитектуру обучаемой модели. Мы очищаем динамический массив для записи описания архитектуры модели и подготовим переменную для записи указателя на объект описания одного нейронного слоя CLayerDescription.
//--- Model
Description.Clear();
CLayerDescription *descr;
Как обычно, первым мы создаем нейронный слой исходных данных. В качестве слоя исходных данных мы будем использовать полносвязный нейронный слой без функции активации. Размер нейронного слоя мы указываем равным количеству передаваемых в модель значений. Напомню, что для описания каждой свечи исторических данных мы будем передавать 12 значений. Среди описание самой свечи и значения анализируемых индикаторов. Кроме того, мы будем передавать состояние счета и объем открытых позиций. Что добавит ещё 9 значений.
Алгоритм описания нейронного слоя будет повторяться для каждого нейронного слоя и состоит из трех этапов. Сначала мы создаём новый экземпляр объекта описания нейронного слоя. И не забываем проверить результат выполнения операции. Так как при ошибке создания нового объекта мы рискуем получить критическую ошибку обращения к несуществующему объекту.
Далее мы задаем описание нейронного слоя. Здесь количество указываемых параметров будет варьироваться от типа создаваемого нейронного слоя. Для слоя исходных данных мы указываем тип нейронного слоя, количество элементов в нейронном слое, тип оптимизации параметров и функцию активации.
После внесения всех необходимых параметров нейронного слоя мы добавляем указатель на объект описания нейронного слоя в динамический массив описания архитектуры модели.
//--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = HistoryBars * 12 * 9; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Опыт обучения нейронных сетей подсказывает, что процесс обучения проходит стабильнее при использовании нормализованных исходных данных. Для нормализации данных в процессе обучения и опытной эксплуатации мы будем использовать слой пакетной нормализации. Его мы и создадим сразу за слоем исходных данных.
Здесь мы, как и ранее, вначале создаём новый экземпляр объекта описания нейронного слоя и проверяем результат выполнения операции. Далее укажем тип создаваемого нейронного слоя defNeuronBatchNormOCL. Количество элементов на уровне размера предыдущего нейронного слоя. И размер пакета нормализации. После чего добавляем указатель на объект описания нейронного слоя в динамический массив описания архитектуры модели.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
После нормализации данных мы создадим блок предварительной обработки. Здесь мы с помощью сверточных нейронных слоёв будем искать закономерности в исходных данных.
Как и ранее, мы создаем новый экземпляр объекта описания нейронного слоя CLayerDescription. Указываем тип нейронного слоя defNeuronConvOCL. Укажем окно анализируем данных в размере 3 элементов. Шаг окна данных установим в размере 1. При таких параметрах количество элементов в одном фильтре будет на 2 меньше размера предыдущего слоя. Чтобы по максимуму раскрыть потенциал я создал 16 фильтров в данном нейронном слое. Такое количество фильтров выглядит завышенным. Но мне хотелось сделать модель максимально гибкой. В качестве функции активации я использовал LeakReLU. А для оптимизации параметров будем использовать Adam.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = prev_count - 2; descr.window = 3; descr.step = 1; descr.window_out = 16; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Следующий шаг весьма не стандартный. После сверточного слоя мы привыкли использовать подвыборочный слой для понижения размерности. Но в данном случае мы имеем дело с тайм-сериями. И помимо самих значений нам необходимо отслеживать динамику изменения признаков. И с этой целью решил провести эксперимент и установить после сверточного слоя LSTM-блок. Разумеется, его размер будет меньше выхода сверточного слоя. Но благодаря архитектуре рекуррентного блока мы ожидаем получить понижение размерности с оглядкой на предыдущие состояния системы.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 300; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Для выявления более сложных структур мы повторим еще раз блок из сверточного и рекуррентного нейронных слоев.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = 100; descr.window = 3; descr.step = 3; descr.window_out = 10; descr.activation = LReLU; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronLSTMOCL; descr.count = 100; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Далее мы подходим к реляционному блоку нашей обучаемой модели. Здесь мы будем использовать блок из многослойного многоголового Self-Attention. Для этого мы укажем тип нейронного слоя defNeuronMLMHAttentionOCL. Количество элементов последовательности исходных данных мы укажем равным количеству анализируемых свечей. В таком случае количество признаков описания одной свечи будет равным 5.
Прошу не путать количество признаков описания одной свечи и входе в модель и на входе реляционного блока. Так как до реляционного блока проведена первичная обработка данных сверточными и рекуррентными нейронными слоями.
Размер вектора Keys мы укажем равным 16. А количество голов внимания зададим 64. Как и в случае с фильтрами сверточных нейронных сетей, я указал завышенное количество голов внимания с целью всестороннего анализа сложившейся рыночной ситуации.
Таких слоёв мы создадим 4. Но мы не будем 4 раза сохранять данное описание нейронного слоя. Вместо этого мы укажем параметр layers равным 4.
Как и во всех предыдущих случаях, метод оптимизации параметров будем использовать Adam. А функция активации в данном случае не указывается, так как все функции активации прописаны алгоритмом построения нейронного слоя.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = 20; descr.window = 5; descr.step = 64; descr.window_out = 16; descr.layers = 4; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
Для завершения описания архитектуры обучаемой модели нам остаётся указать слой полностью параметризированной квантильной функции. В описании данного нейронного слоя мы указываем лишь тип нейронного слоя defNeuronFQF, пространство действий, количество квантилей и метод оптимизации параметров.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = 4; descr.window_out = 32; descr.optimization = ADAM; if(!Description.Add(descr)) { delete descr; return false; }
На этом мы завершаем подпроцесс описания архитектуры обучаемой модели. Но нам ещё необходима Forward и Inverse модели. Их архитектура полностью взята из предыдущей статьи. Но для правильной работы советника нам необходимо добавить их описание в нашем методе. Подпроцесс описания полностью повторяет описанный выше процесс.
Вначале мы очищаем динамический массив описания архитектуры Forward модели. И добавляем нейронный слой исходных данных. Для Forward модели размер слоя исходных данных равен конкатенированному вектору из размера выхода энкодера основной модели и пространства возможных действий агента.
//--- Forward Forward.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 104; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
Далее расположился полносвязный нейронный слой из 500 элементов с функцией активации LReLU и методом оптимизации Adam.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
На выходе блока Forward мы ожидаем получить следующее состояние на выходе энкодера модели. Следовательно, завершает данную модель полносвязный нейронный слой с количеством нейронов равным размеру вектора на выходе энкодера модели. Функцию активации мы не используем. А метод оптимизации параметров, как и ранее, используется Adam.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 100; descr.activation = None; descr.optimization = ADAM; if(!Forward.Add(descr)) { delete descr; return false; }
Аналогичный подход и к построению Инверсной модели. Только на вход данного блока мы подаём конкатенированный вектор двух последующих состояний. А следовательно размер слоя исходных данных в 2 раза больше размера выхода энкодера модели.
//--- Inverse Inverse.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 200; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
Второй нейронный слой аналогичен такому же слою Forward модели.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 500; descr.activation = LReLU; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
На выходе инверсной модели мы ожидаем получить предпринятое действие. Поэтому размер следующего нейронного слоя равен пространству допустимых действий агента. Только данный слой не использует функцию активации. Вместо неё мы воспользуемся последующим слоем Softmax.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 4; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; }
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = 4; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!Inverse.Add(descr)) { delete descr; return false; } //--- return true; }
Дальнейший код советника перенесен из предыдущей статьи без изменений. А с полным кодом советника и всех используемых библиотек можно ознакомиться во вложении.
3. Тестирование
Обучение и тестирование построенной модели осуществлялось в тестере стратегий с использованием исторических данных инструмента EURUSD на тайм-фрейме H1. Параметры индикаторов использовались по умолчанию.

В результате обучения модели нам удалось получить рост баланса в тестере стратегий. Не смотря на то, что в среднем на каждые 2 прибыльные сделки приходится 2 убыточные и доля прибыльных сделок составила 53.7%. В целом мы наблюдаем довольно ровный рост графика баланса и эквити, так как средняя прибыльная сделка на 12.5% превышает среднюю убыточную сделку. Профит фактор составил 1.31. А фактор восстановления достигает 2.85.


Заключение
В данной статье мы познакомились с использование реляционных подходов в области обучения с подкреплением. Мы добавили реляционный блок в модель и обучили её с использованием модуля внутреннего любопытства. Результаты тестирования показали способность такого подхода к обучению моделей. И создании на их основе советников, генерирующих прибыль.
Хочу акцентировать внимание, что представленный в статье советник способен совершать торговые операции. Однако он не готов для использования в реальной торговле. Советник представлен только в целях демонстрации технологии. Перед использованием советника на реальных счетах требуется значительная его доработка и тщательное тестирование во всевозможных условиях.
Ссылки
- Neural Machine Translation by Jointly Learning to Align and Translate
- Effective Approaches to Attention-based Neural Machine Translation
- Attention Is All You Need
- Deep reinforcement learning with relational inductive biases
- Нейросети — это просто (Часть 8): Механизмы внимания
- Нейросети — это просто (Часть 10): Multi-Head Attention (многоголовое внимание)
- Нейросети — это просто (Часть 11): Вариации на тему GPT
- Нейросети — это просто (Часть 35): Модуль внутреннего любопытства (Intrinsic Curiosity Module)
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | RRL-learning.mq5 | Советник | Советник для обучения модели. |
| 2 | ICM.mqh | Библиотека класса | Библиотека класса организации работы модели |
| 3 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 4 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Всем привет. есть проблемка :
20 часть ae , ae2 идет и запускается
21 часть vae, vae2 ошибка компиляции 'pow' - ambiguous call to overloaded function NeuroNet.mqh 4467 38
22 часть компилируется но при запуске сразу после загрузки драйвера OpenGL моргает экран и останавливается.
23 часть AE запускается
rnn_vae компелируеться компилируется но при запуске сразу после загрузки драйвера OpenGL моргает экран и останавливается
vae выдает ошибку при компиляции
36 reinforce zero code error
rrl learning компилируется но при запуске сразу после загрузки драйвера OpenGL моргает экран и останавливается
Hi Dmitry Gizlyk,
Thanks for your wonderful articles.
Please help! When I try to train in Strategy Tester using Ryzen 9 6900hx (APU), I got this error and the EA had no transaction.
How to fix this problem bro?
Hi Dmitry,
Thank you for the awesome work! This is the best tutorial so far on the net regarding ML on MQL5 platform
Details are well explained and can be understood by new learner.
Following your tutorial, I've ran Strategy Tester and apparently, only one of my processor were use despite there are 12 available as shown in the picture below
Is there any way to activate all cores instead of just one?
OS Windows 11 build 22H2
OpenCL Support 3.0
CPU Intel i5-12400 ghz.html)
GPU Intel UHD Graphic 730 (integrated)
RAM 16gb
OpenCL are already enabled in Metatrader's settings.
Thanks for the detailed tutorial!
Hi Dmitry,
Thank you for the awesome work! This is the best tutorial so far on the net regarding ML on MQL5 platform
Details are well explained and can be understood by new learner.
Following your tutorial, I've ran Strategy Tester and apparently, only one of my processor were use despite there are 12 available as shown in the picture below
Is there any way to activate all cores instead of just one?
OS Windows 11 build 22H2
OpenCL Support 3.0
CPU Intel i5-12400 ghz.html)
GPU Intel UHD Graphic 730 (integrated)
RAM 16gb
OpenCL are already enabled in Metatrader's settings.
Thanks for the detailed tutorial!
Hi, at Strategy tester you can see only one core use. It used by mql program, not OpenCL. OpenCL use GPU or CPU cores in system outside Strategy tester monitor. There are several ways to see the resource consumption of an OpenCL program in Windows:
1. Use performance monitoring software such as MSI Afterburner or GPU-Z, which display GPU usage and other system components. They can also show what portion of resources each OpenCL program is using.
2. Use profilers such as AMD CodeXL or NVIDIA Nsight Visual Studio Edition. They allow you to analyze an OpenCL program and display which parts of the code consume the most time and resources.
3. Use the OpenCL API to gather statistics. This allows you to programmatically obtain information about the use of OpenCL resources, such as memory usage or core performance. You can use the Performance Counters for OpenCL (PCPerfCL) library to gather this information in Windows.
4. Use profiling tools such as Intel VTune Amplifier, which can help you see how a program uses processor and other system component resources.
Дмитрий добрый день!
Помогите пожалуйста запустить вашего советника с этой статьи. Пробовал уже по всякому заставить его работать, но увы не как не работает по нормальному.
Проблема следующая: советник в тестере запускается и начинает тест в тестере нормально, идёт отсчёт секунд, зелёная полоска, ошибок в логе нет, нормально видит видеокарту и её выбирает. Но на видеокарте загрузка 0%. Как будто он ничего на ней не считает. В Common\Files образуются 2 файла с расширениями icm и nnw размером 1 kb. При попытки повторно перезапустить тест в тестере ругается что не может инициализироваться и тест не стартует. Если перезагрузить МТ5 и удалить файлы созданные этим советником в Common\Files то запускается нормально, но так же не использует видеокарту и создаёт заново эти файлы по 1 kb. и так по кругу.
Я пробовал брать файлы NeuroNet.mqh из следующей статьи (что вы там в комментариях выложили) и заменять им тот что здесь в статье идёт - не помогло. Пробовал временной участок в тестере выбирать небольшой (1 месяц, 1 неделя, 2 месяца и тп) тоже не помогло.
Как его запустить? Советники с предыдущих статей запускаются нормально, и видеокарту используют корректно.
Еще проблема с советником со следующей статьи 37, 38. Там наоборот нет прогресса в тестере, но видеокарта используется на максимум и так хоть 5 часов, хоть 10 часов.
А советник с 39 статьи заработал нормально. Там я выбирал историю больше 1 месяца и он не создавал базу данных, а выбрал 1 месяц и он нормально создал базу. Остальные его части отработали нормально.