
Redes neurais de maneira fácil (Parte 49): Soft Actor-Critic (SAC)

Introdução
Continuamos nossa jornada explorando algoritmos de resolução de problemas usando aprendizado por reforço em espaços de ação contínua. Em artigos anteriores, já nos familiarizamos com os algoritmos Deep Deterministic Policy Gradient (DDPG) e Twin Delayed Deep Deterministic Policy Gradient (TD3). Neste artigo, proponho apresentar a vocês mais um algoritmo - Soft Actor-Critic (SAC). Este algoritmo foi introduzido pela primeira vez no artigo "Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor" (janeiro de 2018). Ele foi apresentado praticamente ao mesmo tempo que o TD3 e compartilha algumas semelhanças, mas também possui diferenças nos algoritmos. O principal objetivo do SAC é maximizar a recompensa esperada levando em consideração a máxima entropia da política, permitindo encontrar soluções ótimas diversas em ambientes estocásticos.
1. Algoritmo Soft Actor-Critic
Ao iniciar a exploração do algoritmo SAC, é importante notar que ele não é um descendente direto do método TD3 (e vice-versa). No entanto, eles têm alguma semelhança. Ambos:
- é um algoritmo off-policy
- explora abordagens do DDPG
- utiliza 2 Críticos
No entanto, ao contrário dos dois métodos previamente abordados, o SAC utiliza a política estocástica do Ator. Isso permite que o algoritmo explore diversas estratégias e encontre soluções ótimas levando em consideração a máxima diversidade nas ações do Ator.
Quando falamos sobre a estocasticidade do ambiente circundante, entendemos que, em um estado S, ao executar uma ação A, recebemos uma recompensa R dentro do intervalo [Rmin, Rmax] com uma certa probabilidade Psa.
O Soft Actor-Critic utiliza um Ator com política estocástica. Isso significa que, em um estado S, o Ator pode escolher uma ação A' de todo o espaço de ações com uma certa probabilidade Pa'. Em outras palavras, a política do Ator em cada estado específico permite escolher não apenas uma ação ótima específica, mas qualquer uma das ações possíveis (mas com uma probabilidade determinada). E durante o treinamento, o Ator aprende essa distribuição de probabilidade para obter a máxima recompensa.
Essa característica da política estocástica do Ator permite explorar diversas estratégias e encontrar soluções ótimas que podem estar ocultas ao usar uma política determinística. Além disso, a política estocástica do Ator leva em consideração a incerteza no ambiente circundante. Na presença de ruído ou fatores aleatórios, essa política pode ser mais robusta e adaptável, permitindo gerar ações diversas para interagir eficazmente com o ambiente circundante.
No entanto, o treinamento da política estocástica do ator introduz mudanças no processo de aprendizado. O treinamento clássico de aprendizado por reforço visa maximizar o retorno esperado. Durante o treinamento, podemos dizer que, para cada ação S, escolhemos uma ação A* que tem a maior probabilidade de nos dar um maior retorno. Essa abordagem determinística estabelece uma dependência clara entre St → At → St+1 ⇒ R e não deixa espaço para a estocasticidade das ações. Para treinar uma política estocástica, os autores do algoritmo Soft Actor-Critic introduzem uma regularização de entropia na função de recompensa.
![]()
A entropia (H) neste contexto é uma medida de incerteza ou diversidade da política. E o parâmetro ɑ>0 é um coeficiente de temperatura que permite equilibrar a exploração do ambiente e a exploração do modelo.
Lembrando que a entropia é uma medida de incerteza de uma variável aleatória e é definida pela fórmula
![]()
Observe que estamos falando do logaritmo da probabilidade de escolha de uma ação no intervalo de valores [0, 1]. E dentro deste intervalo de valores permitidos, o gráfico da função de entropia é decrescente e está na zona de valores positivos. Assim, quanto menor a probabilidade de escolha de uma ação, maior a recompensa, e o modelo é incentivado a explorar o ambiente.
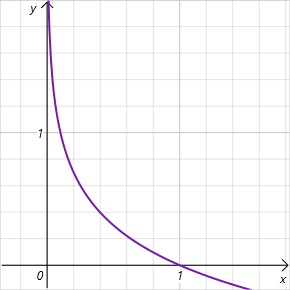
Como pode ser observado, isso coloca requisitos bastante elevados na escolha do hiperparâmetro ɑ. Atualmente, existem diferentes implementações do algoritmo SAC. Entre elas, há a abordagem clássica com um parâmetro fixo. É bastante comum encontrar implementações com redução gradual desse parâmetro. É fácil perceber que quando ɑ=0, chegamos ao treinamento determinístico por reforço. Além disso, existem diferentes abordagens para otimizar o parâmetro ɑ durante o processo de treinamento.
Com a função de recompensa esclarecida, vamos passar para o treinamento do Crítico. Da mesma forma que o TD3, o SAC treina simultaneamente dois modelos do Crítico usando o Erro Quadrático Médio (MSE) como função de perda. Para a previsão do valor futuro do estado, é usado o valor mínimo entre as dois modelos alvo do Crítico. No entanto, existem duas diferenças-chave aqui.
Em primeiro lugar, está a função de recompensa mencionada anteriormente. Aplicamos a regularização de entropia tanto para o estado atual quanto para o estado futuro, levando em consideração o coeficiente de desconto aplicado ao valor do próximo estado do sistema.
A segunda diferença reside no Ator. O SAC não utiliza um modelo alvo para o Ator. Para escolher a ação no estado atual e no estado seguinte, é usado um único modelo treinável do Ator. Isso enfatiza que a obtenção de recompensas futuras é alcançada usando a política atual. Além disso, o uso de um único modelo para o Ator permite reduzir os requisitos de memória e recursos computacionais.
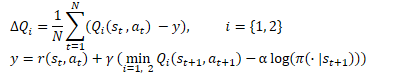
Para treinar a política do Ator, utilizamos abordagens semelhantes ao DDPG. O gradiente do erro de ação é obtido através da retropropagação do gradiente do erro de previsão do valor da ação através do modelo do Crítico. No entanto, ao contrário do TD3 (onde utilizávamos apenas o modelo do Crítico 1), os autores do SAC sugerem o uso do modelo com menor estimativa de valor da ação.
Aqui, há mais um ponto a ser considerado. Durante o processo de treinamento, alteramos a política, o que leva a mudanças nas ações do Ator em diferentes estados do sistema. Além disso, o uso de uma política estocástica do Ator também contribui para a variedade das ações do Ator. Ao mesmo tempo, treinamos os modelos com dados do buffer de experiência, recompensando outras ações do agente. Neste caso, seguimos a suposição teórica de que, durante o treinamento do Ator, estamos avançando em direção à maximização da recompensa prevista. Isso significa que em qualquer estado S, o valor da ação usando a nova política πnew não será inferior ao valor da ação na política anterior πold.
![]()
É uma suposição bastante subjetiva, mas está totalmente alinhada com nossa abordagem de treinamento de modelos. E para evitar possíveis erros, recomendo atualizar o buffer de experiência com mais frequência durante o treinamento, levando em consideração as atualizações na política do Ator.
A atualização dos modelos alvo é realizada de forma suave, usando um coeficiente τ, da mesma forma que no TD3.
E mais uma diferença em relação ao método TD3. No algoritmo Soft Actor-Critic, não há atraso na atualização do Ator e nos modelos alvo. Aqui, a atualização de todos os modelos ocorre a cada etapa de treinamento.
Resumindo o algoritmo Soft Actor-Critic:
- Na função de recompensa, é introduzida uma regularização de entropia.
- No início do processo de treinamento, os modelos do Ator e dos 2 Críticos são inicializados com parâmetros aleatórios.
- Durante a interação com o ambiente, o buffer de reprodução de experiência é preenchido. Isso envolve a gravação do estado do ambiente, a ação, o estado subsequente e a recompensa.
- Depois que o buffer de experiência é preenchido, treinamos os modelos
- Aleatoriamente, amostramos um conjunto de dados do buffer de reprodução de experiência.
- Determinamos a ação para o estado futuro com base na política atual do Ator.
- Determinamos o custo previsto do estado futuro usando pelo menos 2 modelos Críticos alvo.
- Atualizamos os modelos Críticos.
- Atualizamos a política do Ator.
- Atualizamos os modelos alvo.
O processo de treinamento dos modelos é iterativo e continua até que o resultado desejado seja alcançado ou que um mínimo extremo seja atingido no gráfico da função de perda dos Críticos.
2. Implementação usando o MQL5
Após a familiarização teórica com o algoritmo Soft Actor-Critic, vamos passar para sua implementação no MQL5. O primeiro desafio que enfrentamos é a determinação da probabilidade de diferentes ações. Na verdade, é uma questão bastante simples quando se trata de implementar uma política do Ator em forma tabular. No entanto, isso se torna complicado quando usamos redes neurais, pois não mantemos estatísticas dos estados do ambiente e das ações tomadas. Essa informação está "codificada" nos parâmetros ajustáveis do nosso modelo. Nesse contexto, lembrei-me do Aprendizado Q Distribuído. Lembra-se, foi quando discutimos a aprendizagem da distribuição de probabilidade da recompensa esperada. O Aprendizado Q Distribuído nos permitiu obter a distribuição de probabilidade para um número fixo de valores de recompensa em intervalos. E o modelo de função Q totalmente parametrizado (FQF) nos permite aprender tanto os valores em intervalos quanto suas probabilidades.
2.1 Criação de uma classe de camada neural personalizada
Herdando da classe CNeuronFQF, criaremos uma nova classe de camada neural para implementar o algoritmo proposto, chamada CNeuronSoftActorCritic. O conjunto de métodos da nova classe é bastante padrão, mas tem suas peculiaridades.
Especificamente, em nossa implementação, decidimos usar parâmetros ajustáveis para a regularização da entropia. Para isso, adicionamos uma camada neural chamada cAlphas. Nesta implementação, usamos uma camada do tipo CNeuronConcatenate. Isso ocorre porque para determinar o tamanho dos coeficientes, usaremos uma incorporação do estado atual e a distribuição de quantil na saída.
Além disso, adicionamos um buffer separado para registrar os valores de entropia, que serão usados posteriormente na função de recompensa.
Ambos os objetos adicionados são declarados como estáticos, permitindo-nos deixar os construtores e destrutores da classe vazios.
class CNeuronSoftActorCritic : public CNeuronFQF { protected: CNeuronConcatenate cAlphas; CBufferFloat cLogProbs; virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSoftActorCritic(void) {}; ~CNeuronSoftActorCritic(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint actions, uint quantiles, uint numInputs, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcAlphaGradients(CNeuronBaseOCL *NeuronOCL); virtual bool GetAlphaLogProbs(vector<float> &log_probs) { return (cLogProbs.GetData(log_probs) > 0); } virtual bool CalcLogProbs(CBufferFloat *buffer); //--- virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual int Type(void) override const { return defNeuronSoftActorCritic; } virtual void SetOpenCL(COpenCLMy *obj); };
Primeiro, vamos analisar o método de inicialização da classe, chamado Init. Os parâmetros deste método são idênticos aos parâmetros do método correspondente na classe pai. No corpo do método, chamamos imediatamente o método da classe pai. Esse método é frequentemente usado porque a classe pai implementa todo o controle necessário. Além disso, ele inicializa todos os objetos herdados. Uma única verificação do resultado do método da classe pai substitui o controle completo das operações mencionadas. Nos resta apenas inicializar os objetos adicionados.
Em primeiro lugar, inicializamos a camada que calcula os coeficientes ɑ. Como mencionado anteriormente, alimentaremos esta camada com uma incorporação do estado atual, cujo tamanho será igual ao tamanho da camada neural anterior. Também adicionaremos a distribuição de quantil na saída da camada atual, que é mantida no objeto interno cQuantile2 (declarado e inicializado na classe pai). Na saída da camada cAlphas, planejamos obter os coeficientes de temperatura para cada ação individual. Dessa forma, o tamanho da camada será igual ao número de ações.
Os coeficientes devem ser não negativos. Para atender a esse requisito, definimos a função Sigmoid como a função de ativação desta camada.
Ao final do método, inicializamos o buffer de entropia com valores zero. Seu tamanho também é igual ao número de ações. E criamos imediatamente um buffer no contexto atual do OpenCL.
bool CNeuronSoftActorCritic::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint actions, uint quantiles, uint numInputs, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronFQF::Init(numOutputs, myIndex, open_cl, actions, quantiles, numInputs, optimization_type, batch)) return false; //--- if(!cAlphas.Init(0, 0, OpenCL, actions, numInputs, cQuantile2.Neurons(), optimization_type, batch)) return false; cAlphas.SetActivationFunction(SIGMOID); //--- if(!cLogProbs.BufferInit(actions, 0) || !cLogProbs.BufferCreate(OpenCL)) return false; //--- return true; }
Em seguida, passamos à implementação do processo de propagação. Aqui, é importante mencionar que o processo de treinamento dos quantis e da distribuição de probabilidade é completamente herdado da classe pai, sem alterações. No entanto, a execução do processo de cálculo dos coeficientes de temperatura e dos valores de entropia precisa ser adicionada. Além disso, se para calcular os coeficientes de temperatura só precisamos chamar a propagação da camada cAlphas, a determinação dos valores de entropia terá que ser implementada do zero.
Precisamos calcular a entropia para cada ação do Ator. Neste estágio, esperamos que haja um número não muito grande de ações. Mas, uma vez que todos os dados de entrada estão na memória do contexto OpenCL, é lógico efetuar nossas operações nesse ambiente. Primeiro, criaremos o kernel SAC_AlphaLogProbs da programação OpenCL para implementar essa funcionalidade.
Nos parâmetros do kernel, passaremos 5 buffers de dados e 2 constantes:
- outputs — buffer de resultados que contém somas ponderadas por probabilidade de valores de quantis para cada ação.
- quantiles — médias dos valores dos quantis (buffer de resultados da camada interna cQuantile2).
- probs — tensor de probabilidades (buffer de resultados da camada interna cSoftMax).
- alphas — vetor de coeficientes de temperatura.
- log_probs — vetor de valores de entropia (neste caso, um buffer para registrar os resultados).
- count_quants — quantidade de quantis para cada ação.
- activation — tipo de função de ativação.
É importante observar que a classe CNeuronFQF não utiliza uma função de ativação na saída. Eu diria até que isso entra em conflito com a sua essência. Afinal, a distribuição das médias dos quantis da recompensa esperada é delimitada pela própria recompensa real durante o processo de treinamento do modelo. No nosso caso, na saída da camada, esperamos um valor da ação do Ator de uma distribuição contínua. Devido a várias circunstâncias técnicas ou outras, a faixa de ações aceitáveis do agente pode ser limitada por algum intervalo. Isso nos permite adicionar uma função de ativação. No entanto, é crucial para obter uma estimativa precisa da probabilidade que a função de ativação seja aplicada após a determinação da probabilidade da ação real. Portanto, adicionamos sua implementação a este kernel.
__kernel void SAC_AlphaLogProbs(__global float *outputs, __global float *quantiles, __global float *probs, __global float *alphas, __global float *log_probs, const int count_quants, const int activation ) { const int i = get_global_id(0); int shift = i * count_quants; float quant1 = -1e37f; float quant2 = 1e37f; float prob1 = 0; float prob2 = 0; float value = outputs[i];
No corpo do kernel, identificamos a operação atual. Isso nos dará o número de ordem da ação sendo analisada. Em seguida, determinamos imediatamente o deslocamento nos buffers de quantis e probabilidades.
A seguir, declaramos variáveis locais. Para determinar a probabilidade de uma ação específica, precisaremos encontrar os 2 quantis mais próximos. Na variável `quant1`, armazenaremos a média do quantil mais próximo abaixo. E na variável `quant2`, a média do quantil mais próximo acima. No estágio inicial, inicializamos essas variáveis com valores extremos conhecidos. As probabilidades correspondentes são armazenadas nas variáveis `prob1` e `prob2`, que são inicializadas com valores zero. Afinal, em nossa compreensão, a probabilidade de obter valores tão extremos é igual a "0".
O valor procurado no buffer é armazenado em uma variável local `value`.
Lembrando que, devido às peculiaridades da gestão da memória do contexto OpenCL, o acesso a variáveis locais é muito mais rápido do que obter dados do buffer de memória global. Ao operar com variáveis locais, melhoramos o desempenho de todo o programa OpenCL.
Agora, após salvarmos o valor desejado em uma variável local, podemos aplicar a função de ativação ao buffer de resultados do neurônio sem problemas.
switch(activation) { case 0: outputs[i] = tanh(value); break; case 1: outputs[i] = 1 / (1 + exp(-value)); break; case 2: if(value < 0) outputs[i] = value * 0.01f; break; default: break; }
Em seguida, efetuamos um laço para percorrer todas as médias dos quantis e procuramos os mais próximos.
É importante notar que não efetuamos a ordenação das médias dos quantis. Isso não afeta o cálculo da média ponderada e, portanto, dispensamos operações desnecessárias. Por isso, é altamente provável que os quantis mais próximos ao valor procurado não estejam nos elementos adjacentes do buffer de quantis. Então, percorremos todos os valores.
Mais um ponto a ser observado é que, para não atribuirmos o mesmo valor de quantil para ambas as variáveis na parte inferior, usamos o operador lógico ">=" e, para a parte superior, usamos estritamente "<". Quando encontramos um quantil mais próximo, substituímos o valor nas variáveis previamente declaradas, a média do quantil e sua probabilidade correspondente.
for(int q = 0; q < count_quants; q++) { float quant = quantiles[shift + q]; if(value >= quant && quant1 < quant) { quant1 = quant; prob1 = probs[shift + q]; } if(value < quant && quant2 > quant) { quant2 = quant; prob2 = probs[shift + q]; } }
Após a conclusão de todas as iterações do laço, nossas variáveis locais conterão os dados dos quantis mais próximos. E o valor procurado estará entre eles. No entanto, nosso conhecimento sobre a distribuição de probabilidade das ações está limitado apenas à distribuição estudada. Neste caso, usamos a suposição de uma dependência linear de probabilidade entre os 2 quantis mais próximos. Com um número suficientemente grande de quantis, considerando o intervalo limitado de valores da área de ações reais, nossa suposição não está longe da verdade.
float prob = fabs(value - quant1) / fabs(quant2 - quant1); prob = clamp((1-prob) * prob1 + prob * prob2, 1.0e-3f, 1.0f); log_probs[i] = -alphas[i] * log(prob); }
Após determinar a probabilidade de uma ação, calculamos a entropia da ação e multiplicamos o valor obtido pelo coeficiente de temperatura. Para evitar valores muito altos de entropia, limitei o limite inferior da probabilidade a 0,001.
Com isso, concluímos o trabalho nos kernels de propagação e passamos para o programa principal. Aqui, criamos o método de propagação da nossa classe `CNeuronSoftActorCritic::feedForward`.
Como você se lembra, aqui exploramos amplamente as capacidades de métodos virtuais em objetos herdados. Por isso, os parâmetros deste método são idênticos aos métodos correspondentes de todas as classes anteriormente discutidas.
No corpo do método, primeiro chamamos o método de propagação da classe pai e o método correspondente da camada de cálculo dos coeficientes de temperatura. Aqui, é suficiente controlar os resultados desses métodos.
bool CNeuronSoftActorCritic::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!CNeuronFQF::feedForward(NeuronOCL)) return false; if(!cAlphas.FeedForward(GetPointer(cQuantile0), cQuantile2.getOutput())) return false;
A seguir, calcularemos a parte da entropia da função de recompensa. Para fazer isso, preparamos o processo de execução do kernel discutido anteriormente. Iremos executá-lo em um espaço unidimensional, de acordo com o número de ações analisadas.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()};
Como sempre, antes de enfileirar o kernel para execução, realizamos a transferência de dados de entrada para seus parâmetros.
if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_alphas, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_outputs, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_probs, cSoftMax.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaLogProbs, def_k_sac_alp_quantiles, cQuantile2.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_count_quants, (int)(cSoftMax.Neurons() / global_work_size[0]))) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaLogProbs, def_k_sac_alp_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Observe que não estamos verificando nenhum buffer. Isso ocorre porque todos os buffers usados já passaram pelo controle na fase de propagação do método da classe pai e na camada de cálculo dos coeficientes de temperatura. Apenas o buffer interno para armazenar os resultados do kernel não foi verificado. No entanto, esse é um objeto interno, cuja criação controlamos na fase de inicialização do objeto da classe. O acesso externo a ele está indisponível. A probabilidade de erro neste momento é bastante baixa. Por isso, estamos correndo esse risco em prol do desempenho de nosso programa.
Ao final do método, enfileiramos o kernel para execução e verificamos os resultados das operações.
if(!OpenCL.Execute(def_k_SAC_AlphaLogProbs, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Gostaria de enfatizar mais uma vez que, neste caso, estamos verificando o resultado de enfileirar o kernel para execução, mas não os resultados das operações dentro do kernel. Para obter os resultados, precisaremos carregar os dados do buffer `cLogProbs` na memória principal. Essa funcionalidade é implementada no método `GetAlphaLogProbs`. O código do método cabe em uma única linha e é apresentado no bloco de descrição da estrutura da classe.
Encerramos aqui o trabalho de execução do processo de propagação da classe e passamos a criar a funcionalidade de retropropagação. É importante mencionar que a maior parte dessa funcionalidade já está implementada no método da classe pai. Surpreendentemente, não vamos sobrescrever o método de distribuição de gradiente de erro através da camada neural. A questão é que a distribuição do gradiente de erro na regularização de entropia não se encaixa bem na nossa estrutura geral. Obtemos o gradiente de erro em relação à ação a partir do modelo do Crítico, a partir da sua camada final. A própria regularização de entropia foi incorporada à função de recompensa. Dessa forma, o erro dela também estará no nível da previsão da recompensa, ou seja, na camada de saída do Crítico. E aqui temos 2 perguntas:
- A introdução de um buffer de gradientes adicional interromperia o modelo que construímos para virtualizar os métodos de retropropagação.
- Na etapa de retropropagação do Ator, não temos informações sobre o erro do Crítico. Portanto, seria necessário construir um novo processo para todo o modelo.
Decidimos lidar com isso de forma mais simples e criar um novo processo paralelo apenas para o gradiente de erro da regularização de entropia, sem revisar completamente o processo de retropropagação no modelo.
Primeiro, criaremos um kernel no programa OpenCL. Seu código é bastante simples. Apenas multiplicamos o gradiente de erro obtido pela entropia. E, em seguida, ajustamos esse valor pela derivada da função de ativação da camada de cálculo dos coeficientes de temperatura.
__kernel void SAC_AlphaGradients(__global float *outputs, __global float *gradient, __global float *log_probs, __global float *alphas_grad, const int activation ) { const int i = get_global_id(0); float out = outputs[i]; //--- float grad = -gradient[i] * log_probs[i]; switch(activation) { case 0: out = clamp(out, -1.0f, 1.0f); grad = clamp(grad + out, -1.0f, 1.0f) - out; grad = grad * max(1 - pow(out, 2), 1.0e-4f); break; case 1: out = clamp(out, 0.0f, 1.0f); grad = clamp(grad + out, 0.0f, 1.0f) - out; grad = grad * max(out * (1 - out), 1.0e-4f); break; case 2: if(out < 0) grad = grad * 0.01f; break; default: break; } //--- alphas_grad[i] = grad; }
Observe que, para simplificar os cálculos, simplesmente multiplicamos o gradiente pelo valor do buffer `log_probs`. Como você se lembra, durante a propagação, gravamos o valor da entropia aqui, levando em consideração o coeficiente de temperatura. Matematicamente, precisaríamos dividir o valor do buffer por essa quantidade. No entanto, usamos uma sigmoid como função de ativação para a temperatura. Portanto, seu valor está sempre no intervalo [0,1]. Dividir por um número positivo menor que 1 apenas aumentaria o gradiente de erro. E, nesse caso, optamos conscientemente por não fazê-lo.
Após concluir o trabalho no kernel SAC_AlphaGradients, passamos ao trabalho no programa principal e criamos o método `CNeuronSoftActorCritic::calcAlphaGradients`. Neste estágio, primeiro enfileiramos o kernel para execução e só então chamamos os métodos dos objetos internos. Por isso, antes de iniciar o processo, preparamos um bloco de verificações.
bool CNeuronSoftActorCritic::calcAlphaGradients(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL || !NeuronOCL.getGradient() || !NeuronOCL.getGradientIndex()<0) return false;
Em seguida, definimos o espaço de tarefas do kernel e transmitimos os dados de entrada aos seus parâmetros.
uint global_work_offset[1] = {0}; uint global_work_size[1] = {Neurons()}; if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_outputs, cAlphas.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_alphas_grad, cAlphas.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_gradient, NeuronOCL.getGradientIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_SAC_AlphaGradients, def_k_sac_alg_log_probs, cLogProbs.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_SAC_AlphaGradients, def_k_sac_alg_activation, (int)cAlphas.Activation())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Após isso, enfileiramos o kernel para execução e não esquecemos de controlar a execução das operações.
if(!OpenCL.Execute(def_k_SAC_AlphaGradients, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; }
No final do método, chamamos o método de retropropagação da nossa camada interna de cálculo dos coeficientes de temperatura.
return cAlphas.calcHiddenGradients(GetPointer(cQuantile0), cQuantile2.getOutput(), cQuantile2.getGradient()); }
Além disso, vamos sobrescrever o método de atualização dos parâmetros da camada neural `CNeuronSoftActorCritic::updateInputWeights`. O algoritmo deste método é bastante simples. Nele, apenas chamamos métodos semelhantes da classe pai e dos objetos internos. Você pode encontrar o código completo deste método no apêndice. Lá, você também encontrará o código completo de todos os métodos e classes usados neste artigo, incluindo os métodos de trabalho com arquivos de nossa nova classe, sobre os quais não discutiremos agora.
2.2 Fazendo alterações na classe `CNet`
Após concluir o trabalho com a nova classe, vamos declarar constantes para gerenciar os kernels criados. E não esqueceremos de adicionar os novos kernels ao processo de inicialização do objeto de contexto e do programa OpenCL. Este recurso foi repetido mais de 50 vezes ao criar cada novo kernel, então não vamos nos deter nele.
Agora é hora de lembrar que a funcionalidade de nossa biblioteca não inclui a capacidade do usuário de acessar diretamente uma camada neural específica. Todo o processo de interação é construído por meio da funcionalidade de trabalho do modelo como um todo, no nível da classe `CNet`. E para que o usuário possa obter os valores da componente de entropia, criaremos o método `CNet::GetLogProbs`.
Os parâmetros deste método incluem um ponteiro para um vetor para armazenar os valores.
No corpo do método, realizamos um bloco de verificações com uma redução passo a passo do nível dos objetos. Primeiro, verificamos a presença de um objeto de array dinâmico de camadas neurais. Em seguida, descemos para o nível inferior e verificamos o ponteiro para o objeto da última camada neural. Em seguida, descemos mais um nível e verificamos o tipo da última camada neural. Deve ser nossa nova camada `CNeuronSoftActorCritic`.
bool CNet::GetLogProbs(vectorf &log_probs) { //--- if(!layers) return false; int total = layers.Total(); if(total <= 0 || !layers.At(total - 1)) return false; CLayer *layer = layers.At(total - 1); if(!layer.At(0) || layer.At(0).Type() != defNeuronSoftActorCritic) return false; //--- CNeuronSoftActorCritic *neuron = layer.At(0);
Somente após passar por todos os níveis de controle com sucesso, acessamos o método semelhante de nossa camada neural.
return neuron.GetAlphaLogProbs(log_probs);
}
Observe que neste estágio estamos apenas lidando com a camada final do modelo. Isso implica que o uso desta camada é possível apenas como a última camada do Ator.
Outro ponto importante é que este método apenas lê os dados do buffer e não inicia o processo de cálculo. Portanto, faz sentido chamá-lo apenas após a propagação do Ator. Na verdade, isso não representa nenhuma limitação, já que, em nossa concepção, a regularização de entropia será usada apenas para formar a recompensa durante a coleta de dados primários e o treinamento dos modelos. Nos processos mencionados, a propagação do Ator, com a geração da ação, é primordial.
Para as necessidades do processo de retropropagação, criaremos o método `CNet::AlphasGradient`. Como mencionamos anteriormente, a distribuição do gradiente em relação à entropia vai além do processo que construímos anteriormente. Isso também se reflete no algoritmo deste método. Construímos o método de tal forma que o chamaremos para o Crítico. E nos parâmetros do método, passaremos um ponteiro para o objeto Ator.
O algoritmo do bloco de controle deste método está configurado da mesma forma. Primeiro, verificamos a validade do ponteiro para o objeto Ator e a presença do último `CNeuronSoftActorCritic` nele.
bool CNet::AlphasGradient(CNet *PolicyNet) { if(!PolicyNet || !PolicyNet.layers) return false; int total = PolicyNet.layers.Total(); if(total <= 0) return false; CLayer *layer = PolicyNet.layers.At(total - 1); if(!layer || !layer.At(0)) return false; if(layer.At(0).Type() != defNeuronSoftActorCritic) return true; //--- CNeuronSoftActorCritic *neuron = layer.At(0);
A segunda parte do bloco de controle realiza verificações semelhantes para a última camada do Crítico. Aqui, é claro, não há restrições quanto ao tipo de camada neural.
if(!layers) return false; total = layers.Total(); if(total <= 0 || !layers.At(total - 1)) return false; layer = layers.At(total - 1);
Somente após passar com sucesso por todos os controles, acessamos o método de distribuição de gradiente de nossa nova camada neural.
return neuron.calcAlphaGradients((CNeuronBaseOCL*) layer.At(0)); }
É justo dizer que o uso de um modelo completamente parametrizado nos permite determinar as probabilidades de ações individuais. Mas não permite criar uma política Ator verdadeiramente estocástica. A estocasticidade do Ator implica a amostragem de ações de uma distribuição aprendida, o que não podemos realizar do lado do contexto OpenCL. No variational autoencoder, para resolver esse problema, usamos uma técnica de reparametrização com um vetor de valores aleatórios gerados do lado do programa principal. No entanto, neste caso, para a amostragem, precisaríamos carregar a distribuição de probabilidade. Em vez disso, na fase de coleta de dados de treinamento, amostraremos valores em algum ambiente da quantidade calculada (semelhante ao TD3) e depois solicitaremos à modelo as entropias dessas ações. Para esses fins, criaremos o método `CNet::CalcLogProbs`. Seu algoritmo lembra a construção do método `GetLogProbs`, mas, ao contrário deste, receberemos um ponteiro para um buffer de dados com os valores amostrados nos parâmetros. E como resultado das operações do método, obteremos suas probabilidades no mesmo buffer.
Você pode encontrar o código completo de todas as classes e seus métodos no anexo.
2.3 Criação de EAs de treinamento do modelo
Após concluir o trabalho na criação de novos objetos para nosso modelo, passamos a realizar o processo de sua criação e treinamento. Como antes, neste processo envolvemos 3 EAs:
- Research — coleta de dados para a base de exemplos.
- Study — treinamento dos modelos.
- Test — verificação dos resultados obtidos.
Com o objetivo de reduzir o tamanho do artigo e economizar seu tempo, abordaremos apenas as alterações que foram feitas na versão dos EAs correspondentes do artigo anterior para elaborar o algoritmo em questão.
Em primeiro lugar, a arquitetura do modelo. Aqui, alteramos apenas a última camada do Ator, substituindo-a pela nova classe `CNeuronSoftActorCritic`. O tamanho da camada foi especificado com base no número de ações e 32 quantis para cada ação (conforme recomendado pelos autores do método FQF).
Como função de ativação, estamos usando a sigmoide, da mesma forma que nos experimentos do artigo anterior.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- Actor ......... ......... //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftActorCritic; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; descr.activation = SIGMOID; if(!actor.Add(descr)) { delete descr; return false; } //--- Critic ......... ......... //--- return true; }
O algoritmo do EA "...\SoftActorCritic\Research.mq5" foi transferido praticamente sem alterações do artigo anterior. Nem o bloco de coleta de dados históricos nem o bloco de execução de operações de negociação sofreram alterações. As alterações foram feitas apenas na função OnTick em relação à recompensa do ambiente. Como mencionado anteriormente, o algoritmo Soft Actor-Critic adiciona regularização de entropia à função de recompensa.
Assim como antes, usamos a mudança relativa no saldo da conta como recompensa. Também adicionamos uma penalização por falta de posições abertas. Mas agora precisamos adicionar a regularização de entropia. Anteriormente, criamos o método `CalcLogProbs` para isso. Mas há um detalhe. No distribuição quantil do nosso classe, os valores são armazenados antes da função de ativação. No entanto, no processo de tomada de decisão, usamos os resultados ativados do modelo Ator. Usamos a sigmoid como função de ativação na saída do Ator.
![]()
Por meio de transformações matemáticas, chegamos a
![]()
Vamos aproveitar essa propriedade e ajustar as ações amostradas da maneira necessária. Em seguida, transferimos os dados do vetor para um buffer de dados e, se possível, transferimos as informações para a memória do contexto OpenCL.
Após concluir essa preparação, solicitamos ao Ator a entropia das ações realizadas.
Observe que obtivemos a entropia de 6 ações, levando em consideração o coeficiente de temperatura. Mas temos apenas um número para avaliar o estado atual e todas as ações em conjunto. Nesta implementação, usamos o valor total da entropia, o que se encaixa bem no contexto de probabilidades e logaritmos. A probabilidade de um evento complexo é igual ao produto das probabilidades de seus eventos constituintes. E o logaritmo do produto é igual à soma dos logaritmos dos fatores individuais. No entanto, admito o uso de outras abordagens. Sua relevância para cada caso específico pode ser testada durante o treinamento. Não tenha medo de experimentar.
void OnTick() { //--- ......... ......... //--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; temp.Clip(0.001f, 0.999f); temp = MathLog((temp - 1.0f) * (-1.0f) / temp) * (-1); Result.AssignArray(temp); if(Result.GetIndex() >= 0) Result.BufferWrite(); if(Actor.CalcLogProbs(Result)) { Result.GetData(temp); reward += temp.Sum(); } if(!Base.Add(sState, reward)) ExpertRemove(); }
As mudanças mais significativas foram feitas no processo de treinamento do modelo no EA "...\SoftActorCritic\Study.mq5". Vamos nos concentrar mais detalhadamente na função Train desse EA. É aqui que todo o processo de treinamento do modelo é realizado.
No início da função, amostramos um conjunto de dados do buffer de reprodução, como fizemos antes.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); //--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
A seguir, determinamos o valor previsto do estado futuro. O algoritmo repete o processo semelhante à implementação do método TD3. A diferença é a falta do modelo alvo do Ator. Aqui, para determinar a ação no estado futuro, usamos um modelo treinável do Ator.
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance); //--- if(Account.GetIndex() >= 0) Account.BufferWrite();
Preenchemos os buffers de dados de entrada e chamamos os métodos de propagação do Ator e de 2 modelos alvo do Crítico.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
Assim como no método TD3, para treinar o Crítico, usamos o valor mínimo previsto do estado. No entanto, neste caso, adicionamos uma componente de entropia.
vector<float> log_prob; if(!Actor.GetLogProbs(log_prob)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = Buffer[tr].Revards[i] + DiscFactor * (MathMin(reward, Result[0]) + log_prob.Sum() - Buffer[tr].Revards[i + 1]);
É importante notar que, ao salvar a trajetória, também salvamos a soma acumulada das recompensas até o final da passagem, levando em consideração o fator de desconto. Além disso, a recompensa para cada transição para um novo estado inclui a regularização de entropia. Para treinar os modelos Críticos, ajustamos a recompensa acumulada salva pela correção do uso da política atualizada. Para fazer isso, calculamos a diferença entre o valor previsto mínimo do estado subsequente, levando em consideração a componente de entropia, e a recompensa acumulada salva para esse estado no buffer de reprodução de experiência. Em seguida, ajustamos esse valor com o fator de desconto e o somamos ao valor previamente salvo do estado atual. Neste caso, usamos a suposição de que o valor das ações não diminui durante o processo de otimização dos modelos.
Em seguida, chegamos à fase de treinamento dos modelos Críticos. Para fazer isso, preenchemos os buffers de dados com o estado atual do sistema.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Update(0, (Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Update(1, Buffer[tr].States[i].account[1] / PrevBalance); Account.Update(2, (Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Update(3, Buffer[tr].States[i].account[2]); Account.Update(4, Buffer[tr].States[i].account[3]); Account.Update(5, Buffer[tr].States[i].account[4] / PrevBalance); Account.Update(6, Buffer[tr].States[i].account[5] / PrevBalance); Account.Update(7, Buffer[tr].States[i].account[6] / PrevBalance); //--- Account.BufferWrite();
Observe que, neste caso, não verificamos mais a presença do buffer de descrição do estado da conta no contexto OpenCL. Logo após salvarmos os dados, simplesmente chamamos o método de transferência de dados para o contexto. Isso é possível devido à propriedade de todas as nossas modelos estarem trabalhando em um único contexto OpenCL. Já discutimos anteriormente as vantagens dessa abordagem. Ao chamar os métodos de propagação dos modelos alvo, o buffer já foi criado no contexto. Caso contrário, receberíamos um erro ao executá-los. Portanto, nessa fase, não gastamos mais tempo e recursos em verificações desnecessárias.
Após o carregamento dos dados, chamamos o método de propagação do Ator e carregamos a componente de entropia da recompensa.
if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } //--- Actor.GetLogProbs(log_prob);
Neste estágio, temos todos os dados necessários para a propagação e retropropagação dos Críticos. No entanto, neste ponto, fizemos uma pequena alteração em relação ao algoritmo original. Os autores do método sugerem usar o Crítico com a menor estimativa para atualizar a política do Ator após a atualização dos parâmetros dos Críticos. Com base em nossas observações, apesar das diferenças nas estimativas, o gradiente de erro em relação às ações permanece praticamente inalterado. Por isso, decidimos simplesmente alternar entre os modelos Críticos. Em iterações pares, atualizamos o modelo do Crítico 2 com base nas ações do buffer de reprodução de experiência. E treinamos a política do Ator com base nas estimativas do primeiro Crítico.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if((iter % 2) == 0) { if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Clear(); Result.Add(reward-log_prob.Sum()); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Critic1.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Update(0,Buffer[tr].Revards[i]); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Nas iterações ímpares, alternamos o uso dos modelos Críticos.
else { if(!Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Clear(); Result.Add(reward); if(!Critic2.backProp(Result, GetPointer(Actor)) || !Critic2.AlphasGradient(GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Result.Update(0,Buffer[tr].Revards[i]); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } }
Observe a sequência de chamadas dos métodos de retropropagação. Primeiro, realizamos a retropropagação no Crítico. Em seguida, passamos o gradiente pela componente de entropia. Em seguida, realizamos a retropropagação na parte de processamento de dados primários do Ator. Isso nos permite adaptar as camadas convolucionais às necessidades do Crítico. E somente depois disso, realizamos a retropropagação completa do Ator para otimizar sua política de ações.
No final da função, atualizamos os modelos-alvo e exibimos uma mensagem informativa ao usuário para controle visual do processo de treinamento.
//--- Update Target Nets TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); //--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Você pode encontrar o código completo do EA no anexo. Lá também está o código do EA de teste, que sofreu alterações semelhantes às do EA de coleta de dados, e não entraremos em detalhes sobre isso.
3. Testes
O treinamento e os testes do modelo foram realizados com base em dados históricos do instrumento EURUSD, no período de janeiro a maio de 2023, com um intervalo de tempo H1. Os parâmetros dos indicadores e todos os hiperparâmetros foram usados com os valores padrão.
Infelizmente, devo admitir que não consegui treinar um modelo capaz de gerar lucro no conjunto de treinamento ao longo do trabalho nesta pesquisa. Os resultados dos testes mostraram que meu modelo perdeu 3,8% durante os 5 meses do período de treinamento.

O ponto positivo é que o maior lucro em uma negociação de 3,6 excede a maior perda em uma negociação por 1 única operação. A média de negociações lucrativas é apenas um pouco maior do que a média de negociações com prejuízo. No entanto, a porcentagem de negociações lucrativas é de 49%. Em essência, faltou apenas 1% para atingir o ponto de equilíbrio.
Os resultados fora do conjunto de treinamento permaneceram praticamente inalterados. A porcentagem de negociações lucrativas aumentou para 51%, mas o valor médio das negociações lucrativas diminuiu, e mais uma vez obtivemos um prejuízo.

A estabilidade do desempenho do modelo fora do conjunto de treinamento é um fator positivo. No entanto, permanece a questão de como nos livrarmos das perdas. Talvez a razão esteja em nossas alterações no algoritmo. Ou talvez a razão seja o coeficiente de temperatura elevado, incentivando uma maior exploração do mercado.
Além disso, a causa pode estar na grande variação dos valores das ações amostradas. Ao amostrar ações com uma probabilidade próxima de "0", a alta entropia aumenta suas recompensas, distorcendo a política do Ator. Para identificar a causa, serão necessários testes adicionais, cujos resultados compartilharei com você sem falta.
Conclusão
Neste artigo, nos familiarizamos com o algoritmo Soft Actor-Critic (SAC), projetado para resolver problemas em espaços de ação contínua. Ele se baseia na ideia de maximizar a entropia da política, o que permite ao agente explorar diferentes estratégias e encontrar soluções ótimas em ambientes estocásticos, levando em consideração a máxima diversidade de ações.
Os autores do método propuseram o uso de regularização de entropia, que é adicionada à função de objetivo do treinamento. Isso permite que o algoritmo estimule a exploração de novas ações e evite uma fixação muito rígida em estratégias específicas.
Implementamos este método usando a linguagem MQL5, mas, infelizmente, não conseguimos treinar uma estratégia lucrativa. No entanto, o modelo treinado demonstra estabilidade tanto no conjunto de treinamento quanto fora dele. Isso sugere a capacidade do método de generalizar a experiência adquirida e aplicá-la a estados desconhecidos do ambiente circundante.
Estabelecemos metas para encontrar oportunidades de treinar uma política lucrativa do Ator, e apresentaremos os resultados deste trabalho aos leitores posteriormente.
Referências
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
- Soft Actor-Critic Algorithms and Applications
- Redes neurais de maneira fácil (Parte 48): métodos para reduzir a superestimação dos valores da função Q
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | EA de coleta de exemplos |
| 2 | Study.mq5 | Expert Advisor | EA de treinamento do agente |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca das classes para criar uma rede neural |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca do código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/12941
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso