
Нейросети — это просто (Часть 88): Полносвязный Энкодер временных рядов (TiDE)

Введение
Для решения задач прогнозирования временных рядов были исследованы, наверное, все известные архитектуры нейронных сетей, включая рекуррентные, сверточные и графовые модели. Но наиболее заметные результаты демонстрируют модели на основе архитектуры Transformer. В данной серии статей было то же представлено несколько таких алгоритмов. Однако недавние исследования показали, что архитектуры на основе Transformer могут оказаться менее мощными, чем ожидалось. На некоторых бенчмарках прогнозирования временных рядов простые линейные модели могут демонстрировать сопоставимые или даже лучшие результаты. Но, к сожалению, такие линейные модели обладает недостатками, поскольку не подходят для моделирования нелинейных зависимостей между последовательностью временных рядов и независимыми по времени ковариатами.
Дальнейшие исследования в области анализа и прогнозирования временных рядов, можно сказать, разделились на 2 направления. Одни видят не полностью раскрытый потенциал Transformer и работают над повышением эффективности подобных архитектур. Другие работают над минимизацией недостатков линейных моделей. Статья "Long-term Forecasting with TiDE: Time-series Dense Encoder" относится ко второму направлению. В этой работе предлагается простая и эффективная архитектура глубокого обучения для прогнозирования временных рядов, которая обеспечивает более высокую производительность по сравнению с существующими моделями глубокого обучения на популярных бенчмарках. Представленная модель на основе многослойного персептрона (MLP) является удивительно простой и не имеет механизмов Self-Attention, рекуррентных или сверточных слоев. Поэтому она обладает линейной вычислительной масштабируемостью по отношению к длине контекста и горизонту прогнозирования, в отличие от многих решений на основе Transformer.
Модель Time-series Dense Encoder (TiDE) использует MLP для кодирования прошлого временного ряда вместе с ковариатами и декодирования прогнозного временного ряда вместе с будущими ковариатами.
Авторы метода анализируют упрощенную линейную модель TiDE и демонстрируют, что эта линейная модель может достичь почти оптимальной ошибки в линейных динамических системах (LDS), когда матрица конструкции LDS имеет максимальное сингулярное значение, отличное от 1. Они эмпирически проверяют это на симулированных данных, где линейная модель превосходит LSTMs и Tarnsformers.
На популярных реальных бенчмарках прогнозирования временных рядов TiDE достигает лучших или схожих результатов по сравнению с предыдущими базовыми моделями нейронных сетей. В то же время TiDE в 5 раз быстрее в режиме эксплуатации и более чем в 10 раз быстрее при обучении по сравнению с лучшей моделью на основе Transformer.
1. Алгоритм TiDE
Модель называется TiDE (Time-series Dense Encoder) представляет собой простую и эффективную архитектуру на основе MLP для долгосрочного прогнозирования временных рядов. Авторы алгоритма добавляют нелинейности в виде MLP таким образом, чтобы они могли обрабатывать прошлые данные и ковариаты.
Модель применяется к независимым каналам данных, то есть входом в модель являются прошлое и ковариаты одного временного ряда за раз. При этом веса модели обучаются глобально с использованием всего набора данных, т.е. едины для всех независимых каналов.
Ключевым компонентом модели является блок MLP с обратной связью — это MLP с одним скрытым слоем и активацией ReLU. Он также имеет связь пропуска, которая является полностью линейной. Авторы метода используют Dropout на линейном слое, который отображает скрытый слой на выход, а также используют нормализацию слоя на выходе.
Модель TiDE логически разделяется на секции кодирования и декодирования. Секция кодирования содержит шаг проекции признаков, за которым следует плотный MLP-энкодер. Секция декодирования состоит из плотного декодера, за которым следует временной декодер.
Плотный энкодер и плотный декодер можно объединить в один блок. Однако авторы метода разделяют их, так как используют различные размеры скрытых слоев в двух блоках. Также последний слой блока декодера уникален в том смысле, что его размер выхода должен соответствовать горизонту планирования.
Задачей этапа кодирования является отображение прошлого и ковариатов временного ряда в плотное представление признаков. Кодирование в модели TiDE имеет два ключевых шага.
Вначале блок с обратной связью используется для отображения ковариат на каждом временном шаге (как в контексте истории, так на горизонте прогнозирования) в проекцию меньшей размерности.
Затем мы объединяем и сглаживаем все прошлые и будущие спроектированные ковариаты, объединяем их со статическими атрибутами и прошлым временным рядом. После чего отображаем их в эмбеддинг с использованием плотного энкодера, который содержит несколько блоков с обратной связью.
Декодирование в модели TiDE отображает закодированные скрытые представления в будущие прогнозные значения временных рядов. Оно также включает две операции: плотный декодер и временной декодер.
Плотный декодер — это стек нескольких блоков с обратной связью, аналогичным блокам энкодера. Он принимает на вход результаты работы энкодера и отображает его в вектор представления прогнозных состояний.
На выходе модели используется временной декодер для генерации конечных прогнозов. Временной декодер — это такой же блок с обратной связью, который отображает декодированный вектор на t-й временной шаг горизонта прогнозирования, объединенный с проектированными ковариатами прогнозного периода.
Эта операция добавляет связь от ковариатов прогнозного периода к прогнозным значениям временного ряда. Что может быть полезно, если некоторые ковариаты имеют сильное прямое воздействие на фактическое значение на определенном временном шаге. Например, новостной фон в отдельные календарные дни.
К значениям временного декодера добавляются значения глобальное остаточного соединение, которое линейно отображает прошлое анализируемого временного ряда к вектору горизонта планирования. Это гарантирует, что чисто линейная модель всегда является подклассом модели TiDE.
Авторская визуализация метода представлена ниже.
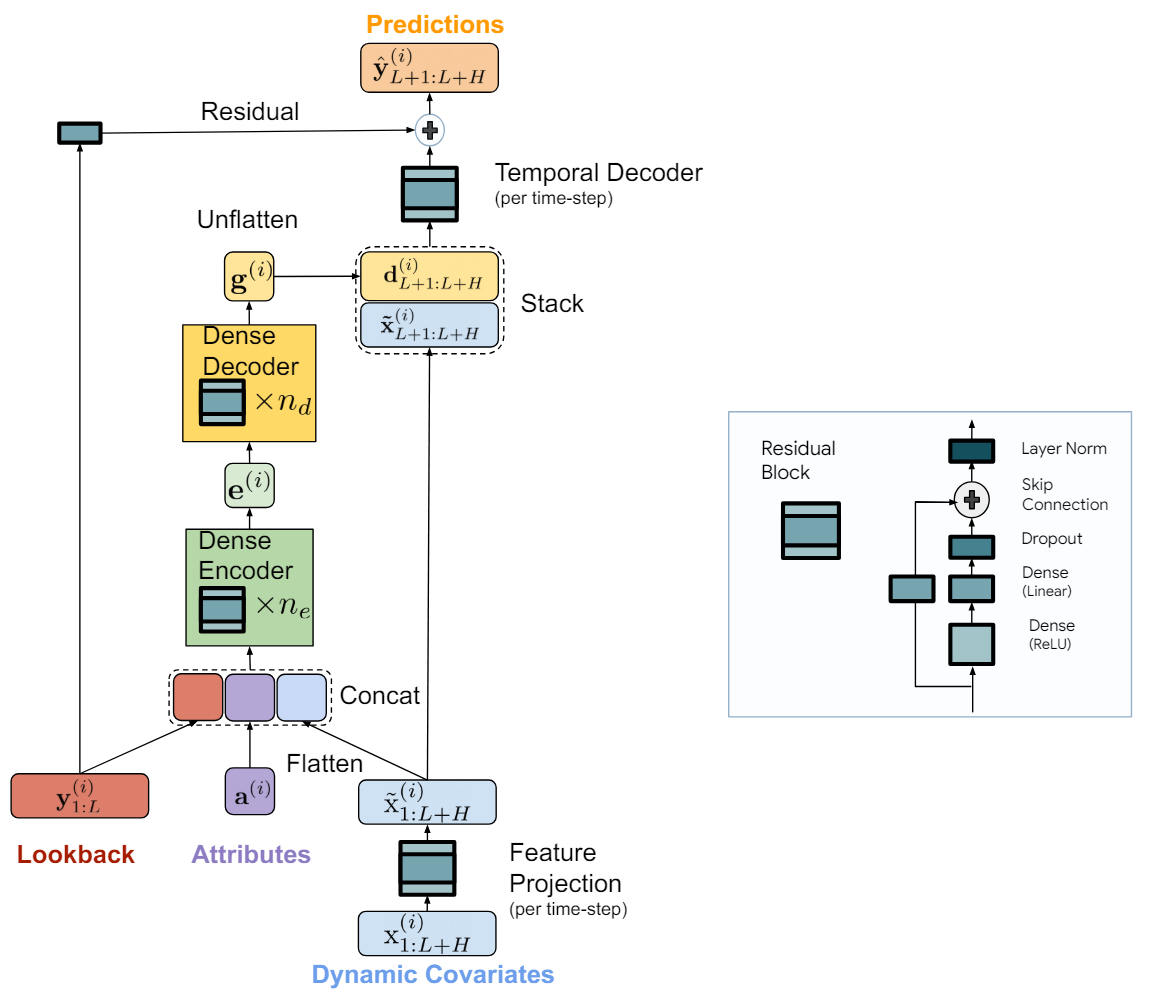
Модель обучается с использованием градиентного спуска по мини-пакетам. Авторы метода в качестве функции потерь используют среднеквадратичную ошибку (MSE). Каждая эпоха включает в себя все пары прошлого и горизонта прогнозирования, которые могут быть построены из периода обучения. То есть два мини-пакета могут иметь перекрывающиеся временные точки.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов алгоритма TiDE мы переходим к реализации предложенных подходов средствами MQL5.
Как уже было сказано выше, основным "кирпичиком" рассматриваемого нами метода TiDE является блок с обратной связью. В нем авторы метода используют полносвязные слои. Но стоит обратить внимание, что каждый такой блок в модели применяется к отдельно взятому независимому каналу. При этом обучаемые параметры блока обучаются глобально и едины для всех каналов анализируемого многомерного временного ряда.
Разумеется, что в своей реализации мы бы хотели реализовать параллельное вычисление для всех независимых каналов анализируемого нами многомерного временного ряда. В подобных случаях мы уже не раз использовали сверточные слои с несколькими фильтрами свертки. Размер окна такого сверточного слоя равен его шагу и соответствует объему данных одного канала. Думаю, очевидно, что оно равно глубине анализируемой истории временного ряда.
И раз уж мы пришли к использованию сверточных слоев, то мне вспоминается блок с обратной связью, который мы создавали при реализации метода CCMR. Внимательный читатель найдет отличие в наличие слоев нормализации, которые мы использовали в указанной реализации. Однако, в рамках работы над данной статьей я решил пренебречь указанным отличием в архитектуре блок и использовать готовый блок CResidualConv для построения новой модели.
Что ж, базовый "кирпичик" предложенного алгоритма TiDE у нас есть. Теперь нам предстоит собрать из этих блоков весь алгоритм.
2.1 Класс алгоритма TiDE
Реализацию предложенных подходов мы обернем в новый класс CNeuronTiDEOCL, который создадим наследником базового класса нейронных слоев нашей модели CNeuronBaseOCL. Для архитектуры нашего нового класса ключевыми являются 4 параметра, для которых мы объявим локальные переменные:
- iHistory — глубина анализируемой истории временного ряда;
- iForecast — горизонт прогнозирования временного ряда;
- iVariables — количество анализируемых переменных (каналов);
- iFeatures — количество ковариат временного ряда.
class CNeuronTiDEOCL : public CNeuronBaseOCL { protected: uint iHistory; uint iForecast; uint iVariables; uint iFeatures; //--- CResidualConv acEncoderDecoder[]; CNeuronConvOCL cGlobalResidual; CResidualConv acFeatureProjection[2]; CResidualConv cTemporalDecoder; //--- CNeuronBaseOCL cHistoryInput; CNeuronBaseOCL cFeatureInput; CNeuronBaseOCL cEncoderInput; CNeuronBaseOCL cTemporalDecoderInput; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = None); public: CNeuronTiDEOCL(void) {}; ~CNeuronTiDEOCL(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint history, uint forecast, uint variables, uint features, uint &encoder_decoder[], ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronTiDEOCL; } virtual void SetOpenCL(COpenCLMy *obj); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); };
Как можно заметить, среди указанных переменных нет количества блоков ни в Энкодере, ни в Декодере модели. В своей реализации мы объединили Энкодер и Декодер в один массив блоков acEncoderDecoder[]. Размер данного массива укажет нам на общее количество блоков с обратной связью, используемых для кодирования исторических данных и декодирования прогнозных значений временного ряда.
Кроме того, проекцию ковариат временного ряда мы разделили на 2 блока (acFeatureProjection[2]). В одном мы будем генерировать проекцию ковариат для кодирования исторических данных, а во втором — для декодирования прогнозных значений.
Мы так же добавим блок временного декодера cTemporalDecoder. А для глобального остаточного соединения воспользуемся сверточным слоем cGlobalResidual.
Дополнительно объявим 4 локальных полносвязных слоя для записи промежуточных значений. С конкретным предназначением каждого слоя мы познакомимся в процессе реализации.
Все объекты в нашем классе мы объявили статичными, что позволяет нам оставить "пустыми" конструктор и деструктор класса.
Должен сказать, что набор переопределяемых методов довольно стандартный. А их рассмотрения мы, как всегда, начнем с метода инициализации объекта класса CNeuronTiDEOCL::Init.
bool CNeuronTiDEOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint history, uint forecast, uint variables, uint features, uint &encoder_decoder[], ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, forecast * variables, optimization_type, batch)) return false;
В параметрах метод получает всю необходимую информацию для реализации требуемой архитектуры. А в теле метода мы сначала вызываем одноименный метод родительского класса, в котором осуществляется минимально-необходимый контроль полученных параметров и инициализация унаследованных объектов.
После успешного выполнения операций метода инициализации родительского класса мы сохраняем значения ключевых констант.
iHistory = MathMax(history, 1); iForecast = forecast; iVariables = variables; iFeatures = MathMax(features, 1);
А затем к переходим к инициализации внутренних объектов. Первыми мы инициализируем блоки проецирования ковариат.
if(!acFeatureProjection[0].Init(0, 0, OpenCL, iFeatures, iHistory * iVariables, 1, optimization, iBatch)) return false; if(!acFeatureProjection[1].Init(0, 1, OpenCL, iFeatures, iForecast * iVariables, 1, optimization, iBatch)) return false;
Здесь надо сказать, что в нашем эксперименте мы не используем каких-либо априорных знаний о ковариатах анализируемого временного ряда. Вместо этого мы спроецируем на последовательность временную гармоники временной метки. При этом мы сгенерируем собственные проекции для каждого канала (переменной) анализируемого многомерного временного канала.
Размерности скрытых слоев плотных энкодера и декодера мы получаем в виде массива encoder_decoder[]. Размер массива указывает на суммарное количество блоков с обратной связью в энкодере и декодере. А значение элементов массива указывает на размерность соответствующего блока. При этом мы помним, что на вход энкодера подается конкатенированный вектор исторических данных временного ряда с проекцией ковариат. А на выходе декодера необходимо получить вектор, соответствующий горизонту прогнозирования. Для выполнения последнего требования мы добавим ещё один блок на выходе декодера необходимого размера.
int total = ArraySize(encoder_decoder); if(ArrayResize(acEncoderDecoder, total + 1) < total + 1) return false; if(total == 0) { if(!acEncoderDecoder[0].Init(0, 2, OpenCL, 2 * iHistory, iForecast, iVariables, optimization, iBatch)) return false; } else { if(!acEncoderDecoder[0].Init(0, 2, OpenCL, 2 * iHistory, encoder_decoder[0], iVariables, optimization, iBatch)) return false; for(int i = 1; i < total; i++) if(!acEncoderDecoder[i].Init(0, i + 2, OpenCL, encoder_decoder[i - 1], encoder_decoder[i], iVariables, optimization, iBatch)) return false; if(!acEncoderDecoder[total].Init(0, total + 2, OpenCL, encoder_decoder[total - 1], iForecast, iVariables, optimization, iBatch)) return false; }
Далее мы инициализируем блок временного декодера и слой глобальной обратной связи.
if(!cGlobalResidual.Init(0, total + 3, OpenCL, iHistory, iHistory, iForecast, iVariables, optimization, iBatch)) return false; cGlobalResidual.SetActivationFunction(TANH); if(!cTemporalDecoder.Init(0, total + 4, OpenCL, 2 * iForecast, iForecast, iVariables, optimization, iBatch)) return false;
Здесь стоит обратить внимание на 2 момента:
- Временной декодер получает на вход конкатенированную матрицу прогнозных значений временного ряда и проекции прогнозных ковариат. А на выход блока мы получаем скорректированные прогнозные значения временного ряда.
- На выходе каждого блока CResidualConv осуществляется нормализация данных: среднее значение каждого канала равно "0", а дисперсия "1". Чтобы привести данные глобально блока обратной связи в сопоставимый вид мы воспользуемся гиперболическим тангенсом (tanh) в качестве функции активации слоя cGlobalResidual.
Следующим этапом мы инициализируем вспомогательные объекты сохранения промежуточных данных. Исторические данные анализируемого многомерного временного ряда и получаемые от внешней программы ковариаты мы будем сохранять в cHistoryInput и cFeatureInput, соответственно.
if(!cHistoryInput.Init(0, total + 5, OpenCL, iHistory * iVariables, optimization, iBatch)) return false; if(!cFeatureInput.Init(0, total + 6, OpenCL, iFeatures, optimization, iBatch)) return false;
Конкатенированную матрицу исторических данных и проекции ковариат запишем в cEncoderInput.
if(!cEncoderInput.Init(0, total + 7, OpenCL, 2 * iHistory * iVariables, optimization,iBatch)) return false;
Результаты работы плотного декодера будут конкатенироваться с ковариатами прогнозных значений и записываться в cTemporalDecoderInput.
if(!cTemporalDecoderInput.Init(0, total + 8, OpenCL, 2 * iForecast * iVariables, optimization, iBatch)) return false;
В завершении метода инициализации объекта класса мы осуществим подмену буферов данных для исключения излишнего копирования градиентов ошибки между буферами данных отдельных элементов нашего класса.
if(cGlobalResidual.getGradient() != Gradient) if(!cGlobalResidual.SetGradient(Gradient)) return false; if(cTemporalDecoder.getGradient() != getGradient()) if(!cTemporalDecoder.SetGradient(Gradient)) return false; //--- return true; }
После завершения работы по инициализации экземпляра класса мы переходим к построению алгоритма прямого прохода, который описан в методе CNeuronTiDEOCL::feedForward. В параметрах метода мы получаем указатели на 2 объекта, содержащие исходные данные. Это исторические данные многомерного временного ряда в виде буфера результатов предыдущего нейронного слоя и ковариаты, представленные отдельных буферов данных.
bool CNeuronTiDEOCL::feedForward(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { if(!NeuronOCL || !SecondInput) return false;
В теле метода мы сразу проверяем актуальность полученных указателей.
Далее нам предстоит скопировать полученные исходные данные во внутренние объекты. Но вместо переноса полного объема информации мы лишь проверим указатели на буферы данных и, при необходимости, скопируем их.
if(cHistoryInput.getOutputIndex() != NeuronOCL.getOutputIndex()) { CBufferFloat *temp = cHistoryInput.getOutput(); if(!temp.BufferSet(NeuronOCL.getOutputIndex())) return false; } if(cFeatureInput.getOutputIndex() != SecondInput.GetIndex()) { CBufferFloat *temp = cFeatureInput.getOutput(); if(!temp.BufferSet(SecondInput.GetIndex())) return false; }
После проведения подготовительной работы мы проецируем исторические данные в размерность прогнозных значений. Своеобразная авторегрессионная модель.
if(!cGlobalResidual.FeedForward(NeuronOCL)) return false;
И сгенерируем проекции ковариат к историческим и прогнозным значениям.
if(!acFeatureProjection[0].FeedForward(NeuronOCL)) return false; if(!acFeatureProjection[1].FeedForward(cFeatureInput.AsObject())) return false;
После чего конкатенируем исторические данные с соответствующей матрицей проекции ковариат.
if(!Concat(NeuronOCL.getOutput(), acFeatureProjection[0].getOutput(), cEncoderInput.getOutput(), iHistory, iHistory, iVariables)) return false;
И организуем цикл проведения операций блока плотных энкодера и декодера.
uint total = acEncoderDecoder.Size(); CNeuronBaseOCL *prev = cEncoderInput.AsObject(); for(uint i = 0; i < total; i++) { if(!acEncoderDecoder[i].FeedForward(prev)) return false; prev = acEncoderDecoder[i].AsObject(); }
Результаты работы декодера мы конкатенируем с проекцией ковариат прогнозных значений.
if(!Concat(prev.getOutput(), acFeatureProjection[1].getOutput(), cTemporalDecoderInput.getOutput(), iForecast, iForecast, iVariables)) return false;
Конкатенированная матрица подается служит исходными данными для блока временного декодера.
if(!cTemporalDecoder.FeedForward(cTemporalDecoderInput.AsObject())) return false;
В завершении операций прямого прохода мы суммируем результаты 2 потоков данных и нормализуем полученный результата в рамках независимых каналов.
if(!SumAndNormilize(cGlobalResidual.getOutput(), cTemporalDecoder.getOutput(), Output, iForecast, true)) return false; //--- return true; }
За прямым проходом, как всегда, следует обратный проход, который состоит из 2 этапов. Вначале мы распределяем градиент ошибки между всеми внутренними объектами и внешними исходными данными в соответствии с их влиянием на конечный результат в методе CNeuronTiDEOCL::calcInputGradients. В параметрах метод получает указатели на объекты для записи градиентов ошибки исходных данных.
bool CNeuronTiDEOCL::calcInputGradients(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput, CBufferFloat *SecondGradient, ENUM_ACTIVATION SecondActivation = -1) { if(!cTemporalDecoderInput.calcHiddenGradients(cTemporalDecoder.AsObject())) return false;
Напомню, что благодаря подмене буферов данных у нас нет необходимости копировать данные из градиентов ошибки нашего класса в соответствующие буферы вложенных объектов. Поэтому мы сразу переходим к вызову методов распределения градиента ошибки наших вложенных блоков в обратном порядке от прямого прохода.
Вначале мы проводим градиент ошибки через блок временного декодера. Результат операций мы распределяем между плотным декодером и проекцией ковариат прогнозного ряда.
int total = (int)acEncoderDecoder.Size(); if(!DeConcat(acEncoderDecoder[total - 1].getGradient(), acFeatureProjection[1].getGradient(), cTemporalDecoderInput.getGradient(), iForecast, iForecast, iVariables)) return false;
После чего распределим градиент ошибки по блоку плотных энкодера и декодера.
for(int i = total - 2; i >= 0; i--) if(!acEncoderDecoder[i].calcHiddenGradients(acEncoderDecoder[i + 1].AsObject())) return false; if(!cEncoderInput.calcHiddenGradients(acEncoderDecoder[0].AsObject())) return false;
Градиент ошибки на уровне исходных данных плотного энкодера мы распределим между историческими данными многомерного временного ряда и соответствующими ковариатами.
if(!DeConcat(cHistoryInput.getGradient(), acFeatureProjection[0].getGradient(), cEncoderInput.getGradient(), iHistory, iHistory, iVariables)) return false;
Далее мы скорректируем градиент ошибки слоя глобальной обратной связи на производную функции активации.
if(cGlobalResidual.Activation() != None) { if(!DeActivation(cGlobalResidual.getOutput(), cGlobalResidual.getGradient(), cGlobalResidual.getGradient(), cGlobalResidual.Activation())) return false; }
И опустим градиент ошибки на уровень исходных данных.
if(!NeuronOCL.calcHiddenGradients(cGlobalResidual.AsObject())) return false;
Тут же мы скорректируем на производную функции активации предыдущего слоя градиент ошибки второго потока данных.
if(NeuronOCL.Activation()!=None) if(!DeActivation(cHistoryInput.getOutput(),cHistoryInput.getGradient(), cHistoryInput.getGradient(),SecondActivation)) return false;
После чего суммируем градиенты ошибки от обоих потоков данных.
if(!SumAndNormilize(NeuronOCL.getGradient(), cHistoryInput.getGradient(), NeuronOCL.getGradient(), iHistory, false, 0, 0, 0, 1)) return false;
На этом этапе мы передали градиент ошибки на уровень исторических данных многомерного временного ряда. И нам остается передать градиент ошибки ковариатам.
Здесь надо сказать, что в рамках проводимого нами эксперимента данный процесс является излишним. Ведь в качестве ковариат мы используем гармоники временной метки, которые задаются формулой. И она не корректируется в процессе обучения. Но мы все же создаем процесс передачи градиента на уровень ковариат с "заделом на будущее". Так как в последующих эксперимента возможно использование различных моделей обучения ковариат временного ряда.
Вначале и спускаем градиент ошибки от ковариат исторических данных. Полученные значения переносим в буфер градиентов ковариат.
if(!cFeatureInput.calcHiddenGradients(acFeatureProjection[0].AsObject())) return false; if(!SumAndNormilize(cFeatureInput.getGradient(), cFeatureInput.getGradient(), SecondGradient, iFeatures, false, 0, 0, 0, 0.5f)) return false;
После чего получим градиенты ковариат прогнозных значений и суммируем результат 2 потоков данных.
if(!cFeatureInput.calcHiddenGradients(acFeatureProjection[1].AsObject())) return false; if(!SumAndNormilize(SecondGradient, cFeatureInput.getGradient(), SecondGradient, iFeatures, false, 0, 0, 0, 1.0f)) return false;
При необходимости корректируем градиент ошибки на производную функции активации.
if(SecondActivation!=None) if(!DeActivation(SecondInput,SecondGradient,SecondGradient,SecondActivation)) return false; //--- return true; }
Вторым этапом обратного прохода является корректировка обучаемых параметров модели. Этот функционал организован в методе CNeuronTiDEOCL::updateInputWeights. Алгоритм данного метода довольно прост. Мы лишь осуществляем поочередный вызов соответствующего метода всех внутренних объектов, которые имеют обучаемые параметры.
bool CNeuronTiDEOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL, CBufferFloat *SecondInput) { //--- if(!cGlobalResidual.UpdateInputWeights(cHistoryInput.AsObject())) return false; if(!acFeatureProjection[0].UpdateInputWeights(cHistoryInput.AsObject())) return false; if(!acFeatureProjection[1].UpdateInputWeights(cFeatureInput.AsObject())) return false; //--- uint total = acEncoderDecoder.Size(); CNeuronBaseOCL *prev = cEncoderInput.AsObject(); for(uint i = 0; i < total; i++) { if(!acEncoderDecoder[i].UpdateInputWeights(prev)) return false; prev = acEncoderDecoder[i].AsObject(); } //--- if(!cTemporalDecoder.UpdateInputWeights(cTemporalDecoderInput.AsObject())) return false; //--- return true; }
Хочется несколько слов сказать о методах работы с файлами. Для экономии дискового пространства мы сохраняем лишь ключевые константы и объекты с обучаемыми параметрами.
bool CNeuronTiDEOCL::Save(const int file_handle) { if(!CNeuronBaseOCL::Save(file_handle)) return false; //--- if(FileWriteInteger(file_handle, (int)iHistory, INT_VALUE) < INT_VALUE) return false; if(FileWriteInteger(file_handle, (int)iForecast, INT_VALUE) < INT_VALUE) return false; if(FileWriteInteger(file_handle, (int)iVariables, INT_VALUE) < INT_VALUE) return false; if(FileWriteInteger(file_handle, (int)iFeatures, INT_VALUE) < INT_VALUE) return false; //--- uint total = acEncoderDecoder.Size(); if(FileWriteInteger(file_handle, (int)total, INT_VALUE) < INT_VALUE) return false; for(uint i = 0; i < total; i++) if(!acEncoderDecoder[i].Save(file_handle)) return false; if(!cGlobalResidual.Save(file_handle)) return false; for(int i = 0; i < 2; i++) if(!acFeatureProjection[i].Save(file_handle)) return false; if(!cTemporalDecoder.Save(file_handle)) return false; //--- return true; }
Однако это приводит к некоторому усложнению алгоритма метода загрузки данных CNeuronTiDEOCL::Load. Как и ранее, в параметрах метод получает хендл файла для загрузки данных. Вначале мы загружаем данные родительского объекта.
bool CNeuronTiDEOCL::Load(const int file_handle) { if(!CNeuronBaseOCL::Load(file_handle)) return false;
Затем считываем значения основных констант.
if(FileIsEnding(file_handle)) return false; iHistory = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false; iForecast = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false; iVariables = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false; iFeatures = (uint)FileReadInteger(file_handle); if(FileIsEnding(file_handle)) return false;
И далее нам предстоит загрузить данные блока плотных энкодера и декодера. Но здесь нас ждет первый нюанс. Мы считываем размер стека блоков из файла данных. Он может оказаться как больше, так и меньше текущего размера нашего массива acEncoderDecoder. При необходимости мы корректируем размер массива.
int total = FileReadInteger(file_handle); int prev_size = (int)acEncoderDecoder.Size(); if(prev_size != total) if(ArrayResize(acEncoderDecoder, total) < total) return false;
Далее мы организовываем цикл и считываем данные блоков из файла. Однако, прежде чем вызвать метод загрузки данных добавленных элементов массива, нам необходимо их инициализировать. Это не относится к ранее созданным объектам, так как они были инициализированы на предыдущих этапах.
for(int i = 0; i < total; i++) { if(i >= prev_size) if(!acEncoderDecoder[i].Init(0, i + 2, OpenCL, 1, 1, 1, ADAM, 1)) return false; if(!LoadInsideLayer(file_handle, acEncoderDecoder[i].AsObject())) return false; }
Далее мы загружаем объекты глобальной обратной связи, проекции ковариат и временного декодера. Здесь не наблюдается "подводных камней".
if(!LoadInsideLayer(file_handle, cGlobalResidual.AsObject())) return false; for(int i = 0; i < 2; i++) if(!LoadInsideLayer(file_handle, acFeatureProjection[i].AsObject())) return false; if(!LoadInsideLayer(file_handle, cTemporalDecoder.AsObject())) return false;
На этом этапе мы загрузили все сохраненные данные. Но у нас остались вспомогательные объекты, которые мы инициализируем аналогично алгоритму инициализации класса.
if(!cHistoryInput.Init(0, total + 5, OpenCL, iHistory * iVariables, optimization, iBatch)) return false; if(!cFeatureInput.Init(0, total + 6, OpenCL, iFeatures, optimization, iBatch)) return false; if(!cEncoderInput.Init(0, total + 7, OpenCL, 2 * iHistory * iVariables, optimization,iBatch)) return false; if(!cTemporalDecoderInput.Init(0, total + 8, OpenCL, 2 * iForecast * iVariables,optimization, iBatch)) return false;
И, при необходимости, осуществляем подмену буферов данных.
if(cGlobalResidual.getGradient() != Gradient) if(!cGlobalResidual.SetGradient(Gradient)) return false; if(cTemporalDecoder.getGradient() != getGradient()) if(!cTemporalDecoder.SetGradient(Gradient)) return false; //--- return true; }
С полным кодом всех методов нашего нового класса Вы можете ознакомиться во вложении. Там же Вы найдете вспомогательные методы класса, которые не были рассмотрены в рамках данной статьи. Их алгоритм довольно прост для самостоятельного изучения. А мы переходим к рассмотрению архитектуры обучаемых моделей.
2.2 Архитектура обучаемых моделей
Думаю, не сложно догадаться, что новый класс метода TiDE мы внесли в архитектуру Энкодера состояния окружающей среды. Именно так мы поступали со всеми рассмотренными ранее алгоритмами прогнозирования будущих состояний временного ряда. Как Вы помните, архитектуру Энкодера мы описываем в методе CreateEncoderDescriptions. В параметрах указанного метода мы получаем указатель на объект динамического массива для записи архитектуры создаваемой модели.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы проверяем полученный указатель и, при необходимости, создаем новый экземпляр объекта динамического массива.
На вход модели мы, как и ранее, подаем необработанные исторические данные, получаемые от терминала.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Полученные данные проходят первичную обработку в слое пакетной нормализации, где они приводятся в сопоставимый вид.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь я хочу напомнить, что в процессе сбора исторических данных описания состояния окружающей среды мы формируем данные в разрезе свечей. Алгоритм же метода TiDE предусматривает анализ данных в разрезе независимых каналов отдельных признаков. С целью сохранения возможности использования ранее собранных буферов воспроизведения опыта для обучения новой модели мы не стали переделывать блок сбора данных. Вместо этого мы добавили слой транспонирования данных, который приведет исходные данные в необходимы вид.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
И далее идет наш новый слой реализации подходов метода TiDE.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTiDEOCL;
Количество анализируемых независимых каналов равно размеру вектора описания одной свечи состояния окружающей среды.
descr.count = BarDescr;
При этом глубина анализируемой истории и горизонт прогнозных значений определяются соответствующими константами.
descr.window = HistoryBars; descr.window_out = NForecast;
Временная метка у нас представляется в виде вектора из 4 гармоник: в разрезе года, месяца, недели и дня.
descr.step = 4;
Архитектура блока плотного энкодера-декодера задается в виде массива значений, как это обсуждалось при построении класса.
{
int windows[]={HistoryBars,2*EmbeddingSize,EmbeddingSize,2*EmbeddingSize,NForecast};
if(ArrayCopy(descr.windows,windows)<=0)
return false;
}
Все функции активации указаны во внутренних объектах класса, поэтому здесь мы ее не указываем.
descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Напомню, что внутри слоя CNeuronTiDEOCL несколько раз осуществляется нормализация данных. И для коррекции смещения прогнозных значений мы воспользуемся сверточным слоем без функции активации, который выполняет простую функцию линейного смещения в рамках независимых каналов.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = NForecast; descr.step = NForecast; descr.window_out = NForecast; descr.activation=None; if(!encoder.Add(descr)) { delete descr; return false; }
Затем мы транспонируем прогнозные значения в размерность исходного представления данных.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
И вернем статистические показатели распределения исходных данных.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr*NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
В связи с изменением архитектуры Энкодера состояния окружающей среды следует обратить внимание на 2 момента. Первое — это указатель на слой извлечения скрытого состояния прогнозных значений окружающей среды.
#define LatentLayer 4
Второе — размер этого скрытого состояния. Если в предыдущей статье на выходе Энкодера состояния было описание исторических данных и прогнозных значений, то сейчас мы имеем только прогнозные значения. Следовательно, нам нужно внести соответствующие корректировки в архитектуры моделей Актера и Критика.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic) { //--- ........ ........ //--- Actor ........ ........ //--- layer 2-12 for(int i = 0; i < 10; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } } ........ ........ //--- Critic ........ ........ //--- layer 2-12 for(int i = 0; i < 10; i++) { if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossAttenOCL; { int temp[] = {1, BarDescr}; ArrayCopy(descr.units, temp); } { int temp[] = {EmbeddingSize, NForecast}; ArrayCopy(descr.windows, temp); } descr.window_out = 32; descr.step = 4; descr.activation = None; descr.optimization = ADAM; if(!critic.Add(descr)) { delete descr; return false; } } ........ ........ //--- return true; }
Обратите внимание, что в данной реализации мы сохраним использование алгоритмов Transformer в моделях Актера и Критика. При этом мы осуществляем кросс-внимание к независимым каналам прогнозных значений. Однако Вы можете поэкспериментировать и с использованием кросс-внимания к прогнозным значениям в разрезе свечей. Только не забудьте изменить указатель на слой скрытого состояния Энкодера, а так же количество анализируемых объектов и размер окна описания одного объекта.
2.3 Советник обучения Энкодера состояния
Следующим этапом наше работы является обучение моделей. И здесь нам потребовались некоторые доработки в алгоритме советников обучения моделей. Прежде всего это касается работы с моделью Энкодера состояния окружающей среды. Ведь именно в эту модель мы добавили новый класс. В данной статье мы не будем детально рассматривать все методы советника обучения модели "...\Experts\TiDE\StudyEncoder.mq5", остановимся лишь на методе непосредственного обучения модели Train.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); //--- vector<float> result, target; bool Stop = false; //--- uint ticks = GetTickCount();
Начало метода сохраняет алгоритм, рассмотренный в предыдущих статьях. Здесь мы видим уже привычную подготовительную работу.
За ней следует цикл обучения модели, в теле которого мы сэмрлируем траекторию из буфера воспроизведения опыта и состояние на ней.
for(int iter = 0; (iter < Iterations && !IsStopped() && !Stop); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2 - NForecast)); if(i <= 0) { iter--; continue; }
Как и ранее мы загружаем исторические данные описания состояния окружающей среды.
bState.AssignArray(Buffer[tr].States[i].state);
Но теперь для генерации прогнозных значений нам необходимы ещё данные ковариат. При построении модели мы договорились использовать гармоники даты состояния окружающей среды. И надеемся, что модель выучит её проекцию на исторические и прогнозные значения.
Подготовим буфер гармоник временной метки.
bTime.Clear(); double time = (double)Buffer[tr].States[i].account[7]; double x = time / (double)(D'2024.01.01' - D'2023.01.01'); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_MN1); bTime.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_W1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = time / (double)PeriodSeconds(PERIOD_D1); bTime.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); if(bTime.GetIndex() >= 0) bTime.BufferWrite();
И теперь мы можем вызвать метод прямого прохода Энкодера состояния окружающей среды.
//--- State Encoder if(!Encoder.feedForward((CBufferFloat*)GetPointer(bState), 1, false, (CBufferFloat*)GetPointer(bTime))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Далее мы, как и ранее, подготавливаем целевые значения.
//--- Collect target data if(!Result.AssignArray(Buffer[tr].States[i + NForecast].state)) continue; if(!Result.Resize(BarDescr * NForecast)) continue;
И осуществляем вызов метода обратного прохода Энкодера.
if(!Encoder.backProp(Result, GetPointer(bTime), GetPointer(bTimeGradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); Stop = true; break; }
Здесь следует обратить внимание, что в параметрах метода обратного прохода помимо целевых значений мы указываем указатели на буферы гармоник временной мети и их градиентов ошибки. На первый взгляд мы не используем градиенты ошибки и могли бы подставить буфер самих гармоник вместо градиентов. Ведь мы не используем градиенты ошибки гармоник в дальнейшей работе. А сами гармоники будут перезаписаны на следующей итерации. Зачем на создавать лишний буфер в памяти?
Но я хочу Вас предостеречь от этого опрометчивого шага. Дело в том, что после распределения градиента ошибки мы осуществляем корректировку параметров модели. Для корректировки весов каждый слой использует градиент ошибки на выходе слоя и исходные данные. Следовательно, если мы перезапишем гармоники временной метки градиентами ошибки, то при обновлении параметров проекции их на ковариаты исторических данных и прогнозных состояний мы получим искаженные градиенты весовых коэффициентов. И, как следствие, искаженную корректировку параметров модели. Думаю, не надо говорить, что в таком случае обучение модели пойдет в непредсказуемом направлении.
После успешного выполнения операций прямого и обратного прохода Энкодера мы информируем пользователя о ходе выполнения процесса обучения и переходим к следующей итерации цикла обучения.
if(GetTickCount() - ticks > 500) { double percent = double(iter) * 100.0 / (Iterations); string str = StringFormat("%-14s %6.2f%% -> Error %15.8f\n", "Encoder", percent, Encoder.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Процесс обучения модели повторяется до выполнения заданного числа итераций цикла, которое указывается во внешних параметрах цикла. А после завершения обучения мы очищаем поле комментариев на графике инструмента.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Encoder", Encoder.getRecentAverageError()); ExpertRemove(); //--- }
Выводим в журнал терминала результаты обучения модели и инициализируем завершение работы советника.
В советник обучения моделей Актера и Критика "...\Experts\TiDE\Study.mq5" мы так же вносим аналогичные корректировки работы моделью Энкодера состояния окружающей среды. Но мы не будем сейчас подробно останавливаться на их описании. Ведь с представленным выше описанием Вы без труда найдете аналогичные блоки в коде советника самостоятельно. А полный код советника Вы можете найти во вложении. Там же представлены советники взаимодействия с окружающей средой и сбора обучающих данные, которые содержат аналогичные правки.
3. Тестирование
Выше мы познакомились с новым методом прогнозирования временных рядов Time-series Dense Encoder (TiDE) и реализовали свое видение предложенных подходов средствами MQL5.
Как уже было сказано ранее, мы сохранили структуру исходных данных от предыдущих моделей, что позволяет нам использовать собранные ранее данные для обучения новых моделей.
Напомню, что обучение всех моделей осуществляется на исторических данных инструмента EURUSD таймфрейм H1. Вполне естественно, что по мене написания статей изменяется и время за нашим окном. На данный момент для обучения своих моделей я использую реальные исторические данные за 2023 год. А тестирование обученных моделей осуществляется в тестере стратегий MetaTrader 5 на данных января 2024 года. Период тестирования следует за периодом обучения, чтобы оценить возможности модели на новых данных, не входящих в обучающую выборку. При этом максимально приблизить условия, когда модель работает в реальном времени на вновь поступающих данных физически не известных на момент обучения модели.
Как и в ряде предыдущих статей, модель Энкодера состояния окружающей среды не зависит от состояния счета и открытых позиций. А следовательно мы можем обучать модель даже на обучающей выборке с одним проходом взаимодействия с окружающей до получения желаемой точности прогнозирования будущих состояний. Естественно, что "желаемая точность прогнрзирования" не модет превышать возможности самой модели. Вы должы помнить, что "нельзя прыгнуть выше головы".
Поле обучения модели прогнозирования состояний окружающей среды мы переходим ко второму эпапу — обучению политики поведения Актера. На этом этапе мы итерационно обучаем модели Актера и Критика с переобдическим обновлением буфера воспроизведения опыта.
Напомню, что под обновлением буфера воспроизведения опыта мы подразумеваем дополнительный сбро опыта взаимодействия с окружающей средой с учетом актуальной политики поведения Актера. Ведь изучаемая нами окружающая среда финансовых рынкло довольно многогранна. И мы не можем полностью собрать все её проявляения в буфере воспроизведения опыта. Мы делаем лишь маленький срез в небольшом окружении действий текущей политики Актера. Анализируя полученный срез, мы делаем маленький шаг на пути оптимизации политики поведения нашего Актера. И при приближении к границам данного среза нам необходимо собрать дополнительные данные, расширив видимую область в окрестностях обновленной политки Актера.
В результате указанных итераций мне удалось обучить политику Актера, способную генерировать как на обучающей, так и на тестовой выборках.


На представленном выше графике мы видим убыточную сделку в начале, которая затем сменяется явным прибыльным трендом. Да, доля прибыльных сделок состаляет менее 40%. Практически на 1 прибыльную сделку приходится 2 убыточных. Однако мы наблюдаем, что убыточние сделки значительно меньше прибыльных. Средняя прибыльная сделка почти в 2 раза превышает среднюю убыточную. Все это позволяет модели получить прибыль на тестовом периоде. По итогам теста профит-фактор составил 1.23.
Заключение
В данной статье мы познакомились с оригинальной моделью TiDE (Time-series Dense Encoder), предназначенной для долгосрочного прогнозирования временных рядов. Данная модель отличается от классических линейных моделей и трансформеров тем, что использует многослойные персептроны (MLP) как для кодирования прошлых данных и ковариат, так и для декодирования будущих прогнозов.
Проведенные авторами метода эксперименты демонстрируют, что применение MLP моделей имеет большой потенциал в области решения задач анализа и прогнозирования временных рядов. Кроме того, TiDE обладает линейной вычислительной сложностью в отличии от Transformer, что делает ее более эффективной в работе с большими объемами данных.
В практической части данной статьи мы реализовали свое видение предложенных подходов, которое немного отличается от авторского. Тем не менее, полученные результаты позволяют говорить об эффективности предложенного подхода. И да, обучение модели осуществляется значительно быстрее рассмотренных ранее Transformers.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования