
Redes neurais de maneira fácil (Parte 48): métodos para reduzir a superestimação dos valores da função Q

Introdução
No artigo anterior, nós exploramos o método Deep Deterministic Policy Gradient (DDPG), projetado para treinar modelos em espaços de ação contínua. Isso nos permite elevar nosso treinamento de modelos a um novo patamar. Como resultado, nosso Agente mais recente é capaz não apenas de prever a direção futura dos movimentos de preço, mas também desempenha funções de gestão de capital e riscos. Ele determina o tamanho ótimo da posição a ser aberta, bem como os níveis de stop loss e take profit.
No entanto, o DDPG não está isento de desvantagens. Assim como outros seguidores do aprendizado Q, ele está sujeito ao problema da sobreavaliação dos valores da função Q. Durante o processo de treinamento, o erro pode se acumular, levando eventualmente ao treinamento de um agente com uma estratégia não otimizada.
Quero lembrar que no DDPG, o modelo do Crítico aprende a função Q (previsão de recompensa esperada) com base nas interações com o ambiente. Enquanto isso, o modelo do Agente é treinado para maximizar a recompensa esperada apenas com base nas avaliações das ações pelo Crítico. Portanto, a qualidade do treinamento do Crítico tem um forte impacto na estratégia de comportamento do Agente e em sua capacidade de tomar decisões ótimas.
1. Abordagens para reduzir a sobreavaliação
O problema da sobreavaliação dos valores da função Q é frequentemente observado ao treinar diferentes modelos com o método DQN e suas derivações. Isso é verdade tanto para modelos com ações discretas quanto para resolução de tarefas em espaços de ação contínuos. As causas desse fenômeno e os métodos para lidar com suas consequências podem ser específicos para cada caso. Por isso, é importante adotar uma abordagem abrangente para resolver esse problema. Uma dessas abordagens foi apresentada no artigo "Addressing Function Approximation Error in Actor-Critic Methods", publicado em fevereiro de 2018. Nele, foi proposto um algoritmo chamado Twin Delayed Deep Deterministic Policy Gradient (TD3). Esse algoritmo é uma extensão lógica do DDPG e introduz melhorias que elevam a qualidade do treinamento dos modelos.
No início, os autores acrescentam um segundo Crítico. A ideia não é nova e já foi usada anteriormente em modelos com espaços de ação discretos. No entanto, os autores do método contribuíram com sua própria compreensão, visão e abordagem para o uso desse segundo Crítico.
A ideia aqui é que ambos os Críticos sejam inicializados com parâmetros aleatórios e treinem simultaneamente com os mesmos dados. Inicializados com parâmetros iniciais diferentes, eles começam seu treinamento a partir de estados diferentes. No entanto, ambos os Críticos são treinados com os mesmos dados, portanto, devem convergir para o mesmo mínimo global, idealmente. É natural que durante o treinamento, seus resultados de previsão se aproximem. No entanto, eles não serão idênticos devido à influência de vários fatores. E sim, cada um deles está sujeito ao problema da sobreavaliação da função Q. Mas em um momento específico, um modelo superestimará a função Q, enquanto o outro subestimará. E mesmo quando ambos os modelos superestimarem a função Q, o erro de um modelo será menor que o do outro. Com base nessas suposições, os autores do método propõem usar a previsão mínima para treinar ambos os Críticos. Isso minimiza o impacto da sobreavaliação da função Q e a acumulação de erro durante o treinamento.
Matematicamente, essa abordagem pode ser representada da seguinte forma:
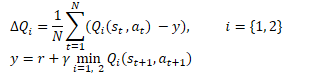
Similar ao DDPG, os autores do TD3 recomendam o uso de atualizações suaves para os modelos alvo. Em exemplos práticos, os autores demonstram que o uso de atualizações suaves para os modelos alvo leva a um processo de treinamento da função Q mais estável com menor dispersão nos resultados. Ao mesmo tempo, o uso de alvos mais estáveis (menos atualizados) durante o treinamento resulta em uma redução na acumulação do erro de sobreavaliação da função Q.
Os resultados dos experimentos levaram os autores a considerar a possibilidade de atualizar a política do Ator com menos frequência.
Lembre-se de que o treinamento de redes neurais é um processo iterativo de redução gradual do erro. A taxa de aprendizado é determinada pelos coeficientes de aprendizado e pelo algoritmo de atualização dos parâmetros. Esse método permite suavizar o erro na amostra de treinamento e construir um modelo que se aproxima ao máximo do processo em estudo.
Os resultados do trabalho do Ator são parte da amostra de treinamento do Crítico. Atualizar a política do Ator com menos frequência permite reduzir a estocasticidade na amostra de treinamento do Crítico e, assim, aumentar a estabilidade de seu treinamento.
Por sua vez, treinar o Ator com os dados da avaliação de um Crítico mais preciso permite melhorar a qualidade do trabalho do Ator e eliminar operações desnecessárias de atualização com resultados incorretos.
Além disso, os autores do algoritmo TD3 sugeriram adicionar um suavizador à função alvo no processo de treinamento. O uso desse subprocesso é baseado na suposição de que ações semelhantes levam a resultados semelhantes. Supomos que realizar duas ações ligeiramente diferentes levará ao mesmo resultado. Logo, adicionar um ruído insignificante às ações do Agente não afetará a recompensa do ambiente. No entanto, isso permite introduzir alguma estocasticidade no treinamento do Crítico e suavizar suas estimativas em determinados cenários de valores-alvo.
![]()
Essa técnica permite introduzir uma espécie de regularização no processo de treinamento do Crítico e suavizar os picos que levam à sobreavaliação dos valores da função Q.
Assim, o Twin Delayed Deep Deterministic Policy Gradient (TD3) introduz 3 principais adições ao algoritmo DDPG:
- Aprendizagem paralela de dois Críticos
- Atualização atrasada dos parâmetros do Ator
- Suavização da função alvo
Como pode ser observado, todas as 3 adições se referem apenas à elaboração do processo de treinamento e não afetam a arquitetura dos modelos.
2. Implementação em MQL5
Na parte prática deste artigo, examinaremos uma implementação do algoritmo TD3 usando MQL5. Devo mencionar que nesta implementação usaremos apenas 2 das 3 adições. Optamos por não incluir o suavizador da função alvo devido à natureza estocástica do próprio mercado financeiro. Na nossa base de treinamento, é improvável encontrarmos dois estados completamente idênticos.
Além disso, estamos retornando ao uso de 3 EAs:
- Research — coleta do banco de dados de exemplos
- Study — treinamento de modelos
- Test — verificação dos resultados obtidos
Além disso, estamos fazendo alterações na interpretação dos resultados do modelo e, consequentemente, no algoritmo de negociação do EA.
2.1. Alterações no algoritmo de negociação
Vamos primeiro discutir as alterações no algoritmo de negociação. Decidimos abandonar a abordagem de "abrir e esquecer", que envolve a abertura contínua de novas posições com base na análise da situação atual do mercado e seu fechamento com base em stop-loss ou take-profit. Em vez disso, abriremos e acompanharemos posições. No entanto, não excluímos a possibilidade de adicionar posições ou fazer fechamentos parciais.
Nessa nova abordagem, é onde alteramos a interpretação dos sinais do modelo. Como antes, o Agente fornece 6 valores: tamanho da posição, stop-loss e take-profit em 2 direções de negociação. Mas agora, compararemos o volume recebido com a posição atual e, se necessário, adicionaremos ou fecharemos parcialmente a posição. Adicionaremos posições da maneira convencional e criaremos uma função ClosePartial para o fechamento parcial.
Aqui, vale a pena mencionar que podemos fechar parte de uma posição usando métodos padrão. No entanto, estamos considerando a presença de várias posições abertas como resultado de adições. Portanto, a função criada tem como objetivo fechar posições com base no método FIFO (First In - First Out) com base no volume total.
A função recebe o tipo de posição e o volume de fechamento como parâmetros. No corpo da função, verificamos imediatamente o volume de fechamento recebido e, em caso de valor incorreto, encerramos a função.
A seguir, fazemos um laço para percorrer todas as posições abertas. No corpo do laço, verificamos o instrumento e o tipo da posição aberta. Quando encontramos a posição desejada, verificamos o seu volume. Aqui, existem 2 cenários:
- volume da posição menor ou igual ao volume de fechamento — fechamos a posição por completo e reduzimos o volume a ser fechado de acordo com o volume da posição;
- volume da posição é maior do que o volume de fechamento — realizamos um fechamento parcial da posição e zeramos o volume com o fechamento.
Continuamos a iterar pelo laço até percorrer todas as posições abertas ou até que o volume a ser fechado seja maior que "0".
bool ClosePartial(ENUM_POSITION_TYPE type, double value) { if(value <= 0) return true; //--- for(int i = 0; (i < PositionsTotal() && value > 0); i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; if(PositionGetInteger(POSITION_TYPE) != type) continue; double pvalue = PositionGetDouble(POSITION_VOLUME); if(pvalue <= value) { if(Trade.PositionClose(PositionGetInteger(POSITION_TICKET))) { value -= pvalue; i--; } } else { if(Trade.PositionClosePartial(PositionGetInteger(POSITION_TICKET), value)) value = 0; } } //--- return (value <= 0); }
Com o volume da posição definido, agora vamos falar sobre os níveis de stop-loss e take-profit. Com base na experiência de negociação, sabemos que mover o nível de stop-loss à medida que o preço se move contra a posição é uma prática ruim. Isso só aumenta os riscos e acumula perdas. Por isso, rastrearemos o stop-loss apenas na direção da negociação. No entanto, permitimos o ajuste do nível de take-profit em ambas as direções. A lógica aqui é simples. Inicialmente, podemos definir o take-profit de forma mais conservadora, mas o desenvolvimento do mercado pode implicar movimentos mais fortes. Portanto, podemos rastrear o stop-loss atrás do preço e, ao mesmo tempo, elevar o patamar de lucro esperado. Ou, inversamente, se não virmos o movimento esperado do mercado, podemos reduzir o patamar de lucro. Levamos apenas o que o mercado oferece.
Para implementar essa funcionalidade, criamos a função TrailPosition. Nos parâmetros da função, especificamos o tipo de posição, os preços do stop-loss e take-profit. Observe que estamos especificando os preços dos níveis de negociação, não os desvios em pontos em relação ao preço atual.
No corpo da função, não fazemos a verificação dos níveis especificados, deixando essa responsabilidade para o usuário, e fazemos uma observação sobre a necessidade desse controle no programa principal.
Em seguida, fazemos um laço para percorrer todas as posições abertas, da mesma forma que na função de fechamento parcial da posição, verificando o instrumento e o tipo da posição no corpo do laço.
Quando encontramos a posição desejada, armazenamos as atuais stop-loss e take-profit da posição em variáveis locais. Nesse ínterim, definimos o sinalizador de modificação da posição como false.
Em seguida, verificamos o desvio dos níveis de negociação da posição aberta em relação aos valores passados como parâmetros. É importante notar que a verificação da necessidade de modificação depende do tipo da posição aberta. Portanto, fazemos esse controle no corpo de um switch com verificação do tipo da posição. Se for necessário alterar pelo menos um dos níveis de negociação, substituímos o valor correspondente na variável local e alteramos o sinalizador de modificação da posição para true.
Ao concluir as operações no ciclo, verificamos o valor do sinalizador de modificação da posição e, se necessário, atualizamos os níveis de negociação da posição. O resultado da operação é armazenado em uma variável local.
Após percorrer todas as posições abertas, encerramos a função. Nesse momento, retornamos o resultado lógico das operações executadas para o programa que a chamou.
bool TrailPosition(ENUM_POSITION_TYPE type, double sl, double tp) { int total = PositionsTotal(); bool result = true; //--- for(int i = 0; i <total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; if(PositionGetInteger(POSITION_TYPE) != type) continue; bool modify = false; double psl = PositionGetDouble(POSITION_SL); double ptp = PositionGetDouble(POSITION_TP); switch(type) { case POSITION_TYPE_BUY: if((sl - psl) >= Symb.Point()) { psl = sl; modify = true; } if(MathAbs(tp - ptp) >= Symb.Point()) { ptp = tp; modify = true; } break; case POSITION_TYPE_SELL: if((psl - sl) >= Symb.Point()) { psl = sl; modify = true; } if(MathAbs(tp - ptp) >= Symb.Point()) { ptp = tp; modify = true; } break; } if(modify) result = (Trade.PositionModify(PositionGetInteger(POSITION_TICKET), psl, ptp) && result); } //--- return result; }
Quando falamos sobre as alterações na interpretação dos sinais do Ator, vale a pena mencionar mais um ponto. Anteriormente, na saída do Ator, usávamos a função de ativação LReLU. Isso permitia obter resultados ilimitados nas faixas superiores, mas também permitia resultados negativos, que interpretávamos como um sinal de ausência de negociação. Na abordagem atual da interpretação dos sinais do Ator, decidimos alterar a função de ativação para a sigmoidal, cujo intervalo de valores vai de 0 a 1. Esses valores nos satisfazem para o volume da negociação, mas não para os níveis de negociação. Para decifrar os valores dos níveis de negociação, introduzimos duas constantes que determinam o tamanho máximo do desvio do stop-loss e do take-profit em relação ao preço. Multiplicando essas constantes pelos valores correspondentes do Ator, obtemos os níveis de negociação em pontos em relação ao preço atual.
#define MaxSL 1000 #define MaxTP 1000
Quanto à arquitetura de nossos modelos, não fizemos mudanças significativas. Portanto, não vou apresentar a descrição dela aqui, mas você pode encontrá-la no anexo. Como sempre, a descrição da arquitetura dos modelos está no arquivo "TD3\Trajectory.mqh" na função CreateDescriptions.
2.2. Construção de um EA para coletar uma base de dados de exemplos
Agora que determinamos os princípios de decifração dos sinais do Ator e os fundamentos do algoritmo de negociação, podemos começar a trabalhar diretamente em nossos EAs de treinamento de modelos.
Primeiro, criaremos um EA para coletar uma base de dados de exemplos "TD3\Research.mq5". O EA é construído com base em EAs semelhantes discutidos anteriormente. Neste artigo, abordaremos apenas o método OnTick, no qual é implementado o algoritmo de negociação descrito anteriormente. Em geral, a nova versão do EA difere pouco das versões anteriores.
No início do método, como antes, verificamos se ocorreu um evento de abertura de uma nova vela. Em seguida, carregamos os dados históricos dos movimentos de preço do instrumento e os indicadores analisados.
void OnTick() { //--- if(!IsNewBar()) return; //--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Os dados carregados são transferidos para um buffer que descreve o estado atual do ambiente.
MqlDateTime sTime; float atr = 0; State.Clear(); for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; TimeToStruct(Rates[b].time, sTime); float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- State.Add((float)Rates[b].close - open); State.Add((float)Rates[b].high - open); State.Add((float)Rates[b].low - open); State.Add((float)Rates[b].tick_volume / 1000.0f); State.Add((float)sTime.hour); State.Add((float)sTime.day_of_week); State.Add((float)sTime.mon); State.Add(rsi); State.Add(cci); State.Add(atr); State.Add(macd); State.Add(sign); }
A próxima etapa envolve a preparação de um vetor que descreve o estado da conta.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; //--- Account.Clear(); Account.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); Account.Add((float)(sState.account[1] / PrevBalance)); Account.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); Account.Add(sState.account[2]); Account.Add(sState.account[3]); Account.Add((float)(sState.account[4] / PrevBalance)); Account.Add((float)(sState.account[5] / PrevBalance)); Account.Add((float)(sState.account[6] / PrevBalance));
Como pode ser observado, a preparação dos dados iniciais é semelhante à elaboração desse processo nos EAs discutidos anteriormente.
Em seguida, transmitimos os dados preparados para a entrada do modelo Ator e realizamos a propagação.
if(Account.GetIndex() >= 0) if(!Account.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) return;
Salvamos os dados necessários para o próximo candle e obtemos o resultado do trabalho do Ator.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); float delta = MathAbs(ActorResult - temp).Sum(); ActorResult = temp;
Observe que neste EA estamos usando apenas o modelo Ator. Afinal, é o Ator que gera a ação de acordo com a política (estratégia) aprendida. Os modelos Críticos serão usados no processo de treinamento do modelo.
Em seguida, com o objetivo de estudar o ambiente da melhor maneira possível, adicionamos um pequeno ruído aos resultados do trabalho do Ator.
Lembre-se de que temos dois modos de operação para o EA. Na fase inicial, iniciamos o EA sem um modelo pré-treinado e inicializamos nosso Ator com parâmetros aleatórios. Nesse modo, não precisamos adicionar ruído para explorar o ambiente, já que o modelo não treinado já fornecerá valores caóticos. No entanto, ao carregar um modelo pré-treinado, a adição de ruído nos permitirá explorar o ambiente nas proximidades das decisões do Ator.
Os valores obtidos são limitados pela faixa de valores permitidos da sigmoidal, que usamos como função de ativação na saída do modelo Ator.
if(AddSmooth) { int err = 0; for(ulong i = 0; i < temp.Size(); i++) temp[i] += (float)(temp[i] * Math::MathRandomNormal(0, 0.3, err)); temp.Clip(0.0f, 1.0f); }
Passamos então à fase de decifração do vetor de resultados do Ator. Primeiro, armazenamos em variáveis locais as principais constantes: tamanho mínimo da posição, passo de alteração do tamanho da posição e margens mínimas dos níveis de negociação.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point();
Começamos decifrando os indicadores de posições longas. O primeiro elemento do vetor corresponde ao tamanho da posição. Deve ser maior ou igual ao tamanho mínimo da posição. Os segundo e terceiro elementos indicam os valores de take-profit e stop-loss, respectivamente. Ajustamos esses elementos com as constantes de valores máximos de take-profit e stop-loss, e também multiplicamos pelo valor de um ponto do instrumento. Como resultado, devemos obter um valor maior que a margem mínima dos níveis de negociação. Se pelo menos um indicador não atender às condições, fechamos todas as posições abertas nessa direção.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); }
Quando os resultados do Ator recomendam abrir ou manter uma posição longa, normalizamos o tamanho da posição de acordo com os requisitos da corretora para o instrumento analisado. Convertemos os níveis de negociação em valores de preço específicos. Em seguida, chamamos a função de modificação de posições abertas descrita anteriormente, especificando o tipo de posição POSITION_TYPE_BUY e os valores de preço dos níveis de negociação obtidos.
else { double buy_lot = min_lot+MathRound((double)(temp[0]-min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp);
Em seguida, ajustamos o tamanho das posições abertas de acordo com as recomendações do Ator. Se o volume das posições abertas for maior do que o recomendado, chamamos a função de fechamento parcial de posições. Nos parâmetros desta função, especificamos o tipo de posição POSITION_TYPE_BUY e a diferença entre os volumes aberto e recomendado como o tamanho das posições a serem fechadas.
Se for recomendado adicionar posições, abrimos uma posição adicional para o volume em falta. Nesse caso, especificamos os níveis recomendados de stop-loss e take-profit.
if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Da mesma forma, decodificamos os indicadores de posição curta.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot+MathRound((double)(temp[3]-min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
No final do método, adicionamos os dados a um array de trajetória para posterior armazenamento no banco de exemplos. Usamos, como recompensa, a alteração relativa no saldo que registramos anteriormente no primeiro elemento do vetor de descrição do estado da conta. A este valor de recompensa, se necessário, adicionamos uma penalização por não haver posições abertas.
Na estrutura de descrição do estado, adicionamos vetores do estado atual do ambiente e dos resultados do Ator. Os dados sobre o estado da conta já foram inseridos anteriormente. E chamamos o método para adicionar o estado atual ao array de trajetória.
//--- float reward = Account[0]; if((buy_value + sell_value) == 0) reward -= (float)(atr / PrevBalance); for(ulong i = 0; i < temp.Size(); i++) sState.action[i] = temp[i]; State.GetData(sState.state); if(!Base.Add(sState, reward)) ExpertRemove(); }
As outras funções do EA foram transferidas praticamente sem alterações. Você pode se familiarizar com elas no anexo. E agora vamos para a próxima etapa do nosso trabalho.
2.3. Criação do EA para treinamento de modelos
O treinamento do modelo é realizado no EA "TD3\Study.mq5". Neste EA, organizaremos todo o algoritmo TD3 com treinamento do Ator e de 2 Críticos.
A elaboração do processo de treinamento requer a adição de várias variáveis externas que nos ajudarão a controlar o processo de treinamento. Como de costume, aqui especificamos o número de iterações para atualizar os parâmetros dos modelos. No contexto do método TD3, isso se refere ao treinamento dos modelos Críticos.
input int Iterations = 1000000;
Para indicar a periodicidade da atualização do Ator, criaremos a variável UpdatePolicy, na qual especificaremos quantas atualizações do Crítico são necessárias para 1 atualização do Ator.
input int UpdatePolicy = 3;
Além disso, especificamos a periodicidade da atualização dos modelos-alvo e o coeficiente de atualização.
input int UpdateTargets = 100; input float Tau = 0.01f;
Na área de variáveis globais, declararemos 6 instâncias da classe de rede neural: Ator, 2 Críticos e modelos-alvo.
CNet Actor; CNet Critic1; CNet Critic2; CNet TargetActor; CNet TargetCritic1; CNet TargetCritic2;
Devo dizer que o método de inicialização do EA é praticamente idêntico aos EAs similares das artigos anteriores. Claro, levando em consideração o número diferente de modelos a serem treinados. Você pode conferir isso no anexo.
No entanto, no método de desativação, fazemos a atualização e o armazenamento dos modelos-alvo, em vez dos modelos de treinamento (como feito anteriormente). Os modelos-alvo são mais estáticos e acumulam menos erros.
void OnDeinit(const int reason) { //--- TargetActor.WeightsUpdate(GetPointer(Actor), Tau); TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); TargetActor.Save(FileName + "Act.nnw", 0, 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt1.nnw", TargetCritic1.getRecentAverageError(), 0, 0, TimeCurrent(), true); TargetCritic1.Save(FileName + "Crt2.nnw", TargetCritic2.getRecentAverageError(), 0, 0, TimeCurrent(), true); delete Result; }
O processo de treinamento dos modelos em si é realizado na função Train. No corpo da função, armazenamos o número de trajetórias de treinamento carregadas em uma variável local e fazemos um ciclo de treinamento com base no número de iterações especificadas em um parâmetro externo.
void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Dentro do ciclo, escolhemos aleatoriamente uma trajetória e um estado da trajetória selecionada.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Primeiro, realizamos uma propagação pelos modelos-alvo, o que nos permite obter a previsão de valor do estado subsequente.
É importante observar que, teoricamente, poderíamos treinar os modelos sem a função alvo. Poderíamos determinar o valor do estado subsequente com base na recompensa subsequente acumulada. Esse enfoque seria apropriado se estivéssemos lidando com um ambiente de estado final finito. No entanto, estamos treinando um modelo para os mercados financeiros, que são infinitos em termos de horizonte de tempo. Estados semelhantes de 1 ou 3 meses atrás têm o mesmo valor para nós, pois queremos aproveitar essa experiência no futuro. Por isso, um modelo Crítico bem treinado tornará os resultados comparáveis independentemente da profundidade do histórico.
Agora, voltando ao nosso EA. Transferimos os dados do banco de exemplos para os buffers de descrição do estado do ambiente e formamos um vetor de descrição do estado da conta. Observe que estamos pegando os dados não para o estado atual, mas para o estado subsequente.
//--- Target State.AssignArray(Buffer[tr].States[i + 1].state); float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
Em seguida, efetuamos uma propagação pelo modelo-alvo do Ator.
if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!TargetActor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Depois, realizamos uma propagação pelos dois modelos-alvo dos Críticos. Os dados de entrada para ambos os modelos são os modelos-alvo do Ator.
if(!TargetCritic1.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor)) || !TargetCritic2.feedForward(GetPointer(TargetActor), LatentLayer, GetPointer(TargetActor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Os dados obtidos nos permitem formar os valores-alvo para o treinamento dos modelos Críticos.
Lembre-se de que cada Crítico retorna apenas um valor de previsão para a ação nas condições atuais. Desse modo, teremos apenas um valor-alvo.
De acordo com o algoritmo TD3, pegamos o valor mínimo entre os resultados dos dois modelos Críticos-alvo. Multiplicamos esse valor pelo fator de desconto e adicionamos a recompensa real pela ação realizada no banco de exemplos.
TargetCritic1.getResults(Result); float reward = Result[0]; TargetCritic2.getResults(Result); reward = DiscFactor * MathMin(reward, Result[0]) + (Buffer[tr].Revards[i] - Buffer[tr].Revards[i + 1]);
Nesta etapa, temos o valor alvo para o Crítico. O algoritmo TD3 prevê apenas um valor alvo para os 2 modelos de Críticos. No entanto, antes de realizar a retropropagação, é necessário fazer uma propagação pelos Críticos. E aqui está um ponto importante. Como você sabe, a arquitetura do Crítico não inclui um bloco de processamento de dados primário. Esse recurso é desempenhado pelo Ator, e passamos ao Crítico o estado latente do Ator como dados de entrada para a descrição do estado do ambiente. Por isso, primeiro pegamos os dados de entrada do banco de exemplos e realizamos uma propagação pelo modelo do Ator.
//--- Q-function study State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); //--- if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Aqui devemos lembrar que, durante o treinamento do Ator, é altamente provável que ele retorne ações diferentes das armazenadas no banco de exemplos. No entanto, a recompensa não corresponde à ação armazenada. Por esse motivo, extraímos o estado latente do Ator, carregamos a ação realizada do banco de exemplos e realizamos uma propagação pelos dois Críticos com base nesses dados.
if(!Critic1.feedForward(Result,1,false, GetPointer(Actions)) || !Critic2.feedForward(Result,1,false, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Vamos observar mais um ponto. Teoricamente, poderíamos ter salvo o estado latente do Ator na fase de coleta de exemplos e agora simplesmente usar os dados salvos. Mas lembre-se de que, durante o treinamento, os parâmetros de todas as camadas neurais mudam. Assim sendo, durante o treinamento do Ator, também ocorre uma alteração no bloco de processamento de dados primário. Como resultado, a representação latente do mesmo estado ambiental também muda. E se treinarmos o Crítico com dados de entrada incorretos, obteremos resultados imprevisíveis ao treinar o Ator. E isso não é o que queremos. Logo, para treinar os Críticos, usamos uma representação latente correta do estado do ambiente, juntamente com as ações realizadas no banco de exemplos e as recompensas correspondentes.
Em seguida, preenchemos o buffer com os valores alvo e realizamos a retropropagação dos dois Críticos.
Result.Clear(); Result.Add(reward); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Agora que entendemos as nuances do treinamento dos Críticos vamos passar para o treinamento do Ator. Como foi dito na parte teórica deste artigo, a atualização dos parâmetros do Ator ocorre com menos frequência. Por isso, primeiro verificamos se essa etapa é necessária na iteração atual.
//--- Policy study if(iter > 0 && (iter % UpdatePolicy) == 0) {
Caso seja o momento de atualizar os parâmetros do Ator, para manter a objetividade, escolhemos aleatoriamente novos dados de entrada.
tr = (int)((MathRand() / 32767.0) * (total_tr - 1)); i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); State.AssignArray(Buffer[tr].States[i].state); PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance);
E realizamos uma propagação pelo Ator.
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
A seguir, realizamos uma propagação de um Crítico. Observe que, neste caso, não usamos dados do banco de exemplos. A propagação pelo Crítico é feita inteiramente com base nos novos resultados do Ator. Afinal de contas, é importante avaliarmos a política atual do modelo.
if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Para a atualização dos parâmetros do Ator, utilizei o Crítico 1. Com base em minhas observações, a escolha do modelo de Crítico neste caso não é crítica. Apesar das diferenças nas avaliações, durante os testes, ambos os Críticos retornaram valores de gradiente idênticos para o Ator.
O treinamento do Ator visa maximizar a recompensa esperada. Pegamos o resultado atual da avaliação das ações pelo Crítico e adicionamos a ele uma pequena constante positiva. Vale ressaltar que, no caso de recebermos uma avaliação negativa das ações, usei minha própria constante positiva como valor alvo. Dessa forma, busquei acelerar a saída da zona de avaliações negativas.
Critic1.getResults(Result); float forecast = Result[0]; Result.Update(0, (forecast > 0 ? forecast + PoliticAdjust : PoliticAdjust));
É importante destacar que, durante a atualização dos parâmetros do Ator, o modelo do Crítico é usado apenas como uma espécie de função de perda. Ele apenas gera o gradiente de erro na saída do Ator. Nesse processo, os parâmetros do próprio Crítico não são alterados. Para isso, desativamos o modo de treinamento no Crítico antes da retropropagação. Após transmitir o gradiente de erro ao Ator, retornamos o Crítico ao modo de treinamento.
Critic1.TrainMode(false); if(!Critic1.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { Critic1.TrainMode(true); PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } Critic1.TrainMode(true); }
Após receber o gradiente de erro do Crítico, realizamos a retropropagação do Ator.
Nesta etapa, fazemos o processo de aprendizado das funções Q pelos Críticos e o treinamento das políticas pelos Ator. Agora, resta implementar a atualização suave dos modelos alvo. A elaboração desse processo foi detalhada no artigo anterior. Aqui, apenas verificamos se é hora de atualizar os modelos e chamamos os métodos correspondentes para cada modelo alvo.
//--- Update Target Nets if(iter > 0 && (iter % UpdateTargets) == 0) { TargetActor.WeightsUpdate(GetPointer(Actor), Tau); TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); }
Ao concluir a iteração do ciclo, informamos ao usuário sobre o estado do processo de treinamento e exibimos os erros atuais de ambos os Críticos. Não exibimos métricas de desempenho do Ator, pois essa modelo não calcula erro.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Após a conclusão das iterações do ciclo, limpamos a área de comentários e iniciamos o processo de encerramento do EA.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); ExpertRemove(); //--- }
Não entraremos em detalhes sobre o algoritmo de funcionamento do EA de teste do modelo treinado "TD3\Test.mq5". Seu código é praticamente idêntico ao do EA de coleta de exemplos. A única diferença é que removemos a adição de ruído aos resultados do Ator. Afinal, durante o teste, queremos avaliar a qualidade do treinamento do modelo, o que exclui a exploração do ambiente. Ao mesmo tempo, mantivemos o bloco de coleta de trajetória e gravação no banco de exemplos. Isso nos permitirá salvar corridas bem-sucedidas e menos bem-sucedidas, e ao iniciar o processo de treinamento posterior, "trabalhar com os erros".
Lembrando que você pode consultar o código completo de todos os programas mencionados no anexo.
3. Teste
Após concluir o desenvolvimento dos programas, avançamos para o processo de treinamento e verificação dos resultados obtidos. Como de costume, o treinamento dos modelos foi realizado com base em dados históricos do par de moedas EURUSD, no período de janeiro a maio de 2023, com intervalo de tempo H1. Os parâmetros dos indicadores e todos os hiperparâmetros foram mantidos nos valores padrão.
É importante mencionar que o processo de treinamento foi longo e iterativo. Na primeira fase, foi criada uma base de dados com 200 trajetórias. O primeiro ciclo de treinamento foi executado com 1.000.000 de iterações. A atualização da política do Ator ocorreu a cada 10 iterações de atualização dos parâmetros dos Críticos, e a atualização suave dos modelos alvo foi realizada a cada 1.000 iterações de atualização dos Críticos.
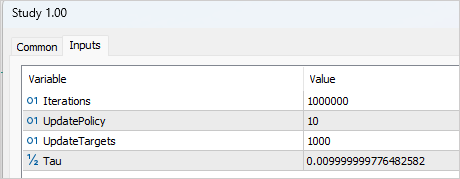
Após a primeira fase de treinamento, mais 50 trajetórias foram adicionadas à base de exemplos e a segunda fase de treinamento dos modelos foi iniciada. Nesse estágio, o número de iterações antes da atualização do Ator e dos modelos alvo foi reduzido para 3 e 100, respectivamente.
Após aproximadamente 5 ciclos de treinamento (com a adição de 50 trajetórias a cada ciclo), obtemos um modelo capaz de gerar lucro no conjunto de treinamento. Ao longo de 5 meses de treinamento, o modelo conseguiu obter um lucro de quase 10%. O índice não é o maior. Foram fechadas 58 operações. A taxa de operações lucrativas atingiu cerca de 40%. O fator de lucro foi de 1,05, e o fator de recuperação foi de 1,50. O lucro foi alcançado principalmente devido ao tamanho das posições lucrativas. O lucro médio por negociação foi 1,6 vezes maior do que a perda média. Além disso, o lucro máximo foi 3,5 vezes maior do que a perda máxima em uma única operação.
É interessante notar que o rebaixamento na conta chegou a quase 32%, enquanto o patrimônio líquido mal ultrapassou os 6%. Como pode ser observado no gráfico, mesmo quando a linha do patrimônio líquido permanece estável ou cresce, ainda ocorrem rebaixamentos na conta. Esse efeito ocorre devido à abertura simultânea de posições em direções opostas. Quando uma posição perdedora atinge o stop loss, ocorre um rebaixamento na conta. No entanto, ao mesmo tempo, uma posição oposta aberta acumula lucro, o que é refletido na linha de patrimônio líquido.


Como lembramos do artigo anterior, o modelo mostrou um resultado mais significativo no conjunto de treinamento, mas não conseguiu replicá-lo em novos dados. Agora a situação é inversa. Não obtivemos lucros excepcionais no conjunto de treinamento, mas o modelo apresentou resultados consistentes fora dele. Ao testar o desempenho do modelo em dados subsequentes que não faziam parte do conjunto de treinamento, vemos uma "versão reduzida" do teste anterior. O modelo obteve um lucro de 2,5% em um mês. O fator de lucro foi de 1,07, e o fator de recuperação foi de 1,16. Houve um total de 27% de operações lucrativas, mas o lucro médio por negociação foi quase 3 vezes maior do que a perda média. O rebaixamento na conta foi de 32%. enquanto o rebaixamento no patrimônio líquido foi de apenas 2%.


Conclusão
Neste artigo, familiarizamos você com o algoritmo Twin Delayed Deep Deterministic Policy Gradient (TD3). Os autores deste método propõem algumas melhorias importantes no algoritmo DDPG, que aumentam a eficácia e a estabilidade do treinamento de modelos.
No contexto deste artigo, implementamos este método usando o MQL5 e o testamos em dados históricos. Durante o treinamento, conseguimos obter um modelo capaz de gerar lucros não apenas nos dados de treinamento, mas também de aplicar essa experiência a novos dados. Vale ressaltar que o modelo obteve resultados comparáveis aos do conjunto de treinamento nos novos dados. Sim, os resultados não são exatamente como gostaríamos que fossem, e há áreas que precisam ser aprimoradas. Mas uma coisa é certa: o algoritmo TD3 permite treinar modelos que funcionam de forma estável com novos dados.
Em resumo, podemos considerar o algoritmo como uma adição valiosa para pesquisas futuras na construção de modelos para negociação real.
Referências
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA de coleta de exemplos |
| 2 | Study.mq5 | EA | EA de treinamento do agente |
| 3 | Test.mq5 | EA | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca das classes para criar uma rede neural |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca do código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/12892
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso